��ƪ�̳�Algorithms for Hyper-Parameter Optimizationд�ú�ʵ�ã�ϣ���ܰﵽ����
Algorithms for Hyper-Parameter Optimization
ԭ�ģ�http://papers.nips.cc/paper/4443-algorithms-for-hyper-parameter-optimization.pdf
���ߣ�
- James Bergstra
�����ѧ�����о���
- R´emi Bardenet
�ϰ����ѧ�������ѧ�о�ʵ����
- Yoshua Bengio
����������ѧ�������ѧ���˳�ѧϵ
- Bal´azs K´egl
�ϰ����ѧֱ������ʵ����
ר�����ʣ�
- DBN
Deep Belief Network������������硣
�����������������磨DBN�� https://my.oschina.net/u/876354/blog/1626639
- SMBO
Sequential Model-Based Global Optimization������˳��ģ�͵�ȫ���Ż���
- EI
Expected Improvement��Ԥ�ڸĽ���
- GP
Gaussian Process����˹���̡�
- EDA
Estimation of Distribution Algorithms���ֲ������㷨��
- CMA-ES
Covariance Matrix Adaptation - Evolution Strategy��Э���������Ӧ�������ԡ�
- TPE
Tree-structured Parzen Estimator Approach����״�ṹParzen���Ʒ�����TPE��
- PCA
Principal Component Analysis�����ɷַ�������
ժҪ
ͼ�����������м������������½�չ���������м����ĸ������ö���������ѧϰ���·�����һ����˵���������Ż��Ĺ���һֱ���˹���ɣ���Ϊ������ֻ����������Ļ����зdz���Ч��Ŀǰ���������Ⱥ��GPU�������������и�������飬���Ƿ����㷨���������ҵ����õĽ����������ѵ�������������������磨DBN��������������������Ż����������ʹ����������ͻ���Ԥ�ڸĽ����������µ�̰��˳�����Ż��������������������ѧϰijЩ���ݼ������������㹻��Ч���������Ƿ���������ѵ��������������Dz��ɿ��ġ�˳���㷨Ӧ����[1]�������ѵ������������ѧϰ���⣬���ҷ��ֱ���ǰ��������ѽ�����Ը��õĽ�����ù����ṩ������������Ӧ��ģ�� P ( y �O x ) P(y|x) P(y�Ox)���¼������������೬�������� ( x ) (x) (x)��Ԫ��������Ԫ�ظ������ض�ֵ�Dz���صġ�
1 ����
��������������磨DBN��[2]����㽵���Զ������[3]����������[4]�Լ����ڸ���������ȡ�����ķ�������ģ�;���10������Լ50��������������ȡ����ʵ�������ѡ������ģ�ͽ��в��������Լ�ʵ�����ں�����Ĭ��ֵ��ѡ����ٳ�������������Щģ�͵��Ѷ�ʹ�ù����Ľ�����Ը��ֺ���չ������ʹ��Щ������ԭʼ�о�������һ��������������һ�ſ�ѧ��
����Ľ����[5]��[6]��[7]���������ͺͶ��ģ���еij������Ż�ֱ���谭�˿�ѧ��������Щ����ͨ�����㷨�еĸ�Э���ij������Ż�������ͨ�����½�ģ�����ѧϰ���ԣ���ͼ����������Ͼ����Ƚ������ܡ�����[5]�Ľ���еó�����ѧϰ�����õĽ�����Ȼ�Ǵ���ġ��෴���������Ż�Ӧ�ñ���Ϊѧϰ�����������������ѭ����ѧϰ�㷨����a functional from data to classifier���Է�������Ϊ����������Ԥ��ѡ���ڳ�����̽���ϻ��Ѷ���CPU���ڣ��Լ����Ѷ���CPU����������ÿ��������ѡ��ͨ�����������������[5]��[7]�Ľ������������������ͼ������Ⱥ��GPU�ĵ���Ӳ����CPU���ڵ���ѷ�������Ȼ���ѧϰ���������ø���ij�����̽����
�������Ż�����ͼ�ṹ���ÿռ����Ż���ʧ���������⡣��������У����ǽ��Լ�������״�ṹ���ÿռ䡣��״�ṹ�����ÿռ���������һЩҶ����������DBN�ڶ��������ز��������ֻ���ڽڵ������������ɢѡ���˶��ٲ㣩ȡ�ض�ֵʱ���ܺܺõض���ֵ���������Ż��㷨���������Ż���ɢ������������ı��������ұ���ͬʱѡ�������һ���������Ż���
�ڸù����У�����ͨ��һ�����ɹ������������ÿռ䣬�Ի�����Ч��������������ǴӸù����л��Ƴ��������䲢��������������㷨���Ż��㷨ͨ��ʶ���Ѿ����Ƶij����������������һ�����ʧ�����������㴦��ֵ����������ϣ�����������������㹱�ף�1�����������[1]��DBN���ֶ��Ż��ǿɾ����ġ�2���Զ�˳���Ż������ֶ������������
��2�ڽ��ܻ���˳��ģ�͵��Ż���Ԥ�ڵĸĽ�������3�ڽ�����һ�ֻ��ڸ�˹���̵ij������Ż��㷨����4�ڽ����˻�������ӦParzen������һ�ַ�������5��������DBN�������Ż������⣬����ʾ�����������Ч�ʡ���6����ʾ�˸�������������������ѵ����ݼ�����˳���Ż���Ч�ʡ������ڵ�7�ں͵�8�������˽�����ܽᡣ
2 ����˳��ģ�͵�ȫ���Ż�(SMBO)
����˳��ģ�͵�ȫ���Ż���SMBO���㷨�ѱ���������Ӧ�ã�����Ӧ�Ⱥ������������ۺܸ�[8,9]������ʵ����Ӧ�Ⱥ��� f : χ → R f:\chi \to \mathbb{R} f:χ→R �����ɱ��ߵ�Ӧ���У�����ģ�͵��㷨�������� f f f ���ø����ˡ�ͨ����SMBO�㷨�е���ѭ���Ǹô�������ֵ�Ż����������ijЩ�任�������������ת�����ĵ� x ∗ x^{*} x∗ ��ԭ��Ӧ��������ʵ���� f f f �������������������ѧϰ�������㷨ģ�������ͼ1��

ͼ1 ͨ�û���˳��ģ�͵�ȫ���Ż�α����
SMBO�㷨�IJ�֮ͬ�����������ڸ��� f f f ��ģ�ͣ�����������Ż��Ի�� x ∗ x^{*} x∗ �ı������������ǵ�ģ�� f f f ͨ���۲���ʷ H \mathcal{H} H ��������е��㷨�Ż���Ԥ�ڸĽ���EI���ı�[10]���������ѱ�����ı�������Ľ����ʺ�Ԥ�ڸĽ�[10]����С����С������������[11]���Լ�[12]�������Ļ���ǿ���ı�������ѡ�������ǵĹ�����ʹ��EI������Ϊ����ֱ�۵ģ������Ѿ�֤���ڸ��ֻ����ж��ܺܺõع��������Ƕ�δ�������ĸĽ�������ϵͳ̽����Ԥ�ڵĸĽ����� f : χ → R N f:\chi \to \mathbb{R}^{N} f:χ→RN ��ij��ģ�� M M M �µ����� f ( x ) f(x) f(x) ������������ij����ֵ y ∗ y^{*} y∗��
E I y ∗ ( x ) : = ∫ − ∞ ∞ m a x ( y ∗ − y , 0 ) p M ( y �O x ) d y \mathrm{EI}_{y^{*}}(x):=\int_{-\infty}^{\infty}\mathrm{max}(y^*-y,0)pM(y|x)dy EIy∗(x):=∫−∞∞max(y∗−y,0)pM(y�Ox)dy
������Ĺ�����ͨ����ģ H \mathcal{H} H: һ�ֲַ��˹���̺���״�ṹParzen���ƣ������� f f f �������²��ԡ���Щ�ֱ��ڵ�3�ں͵�4���н���������
3 ��˹���̷�����GP��
�ڻ���ģ�͵��Ż������У���˹����һֱ����Ϊ�ǽ�ģ��ʧ�����ĺ÷���[13]����˹���̣�GPs��[14]���Ƿ�յ�Ƿ������ԭ��closed under sampling�����������飬����ζ����� f f f ������ֲ�����Ϊ�Ǿ��о�ֵ0�ͺ�k��GP����� f f f �������ֲ���֪���� H = ( x i , f ( x i ) ) i = 1 n \mathcal{H}=(x_{i},f(xi))^{n}_{i=1} H=(xi,f(xi))i=1n ��ֵҲ��GP�����ֵ��Э���������ͨ�������Ƶ�������ԭ���Ͽ���ʹ�þ���ͨ��ƽ��������GP�����Ƕ������ǵ�Ŀ�Ķ��ԣ����������ֵ���̸����ҳ�֡�����ͨ��������ֵ�����������ǵ����ݼ�����ʵ�֡����罨ģGP��ֵ���������Ƶ���ʹ��SMBO���ַ�̽�������еķ���������[15]��
�����ᵽ�ķ���ԣ��Լ�GP�ṩ��������ϡȱ��Ӱ���Ԥ�ⲻȷ������������ʵ��ʹ��GP��ΪѰ�Һ�ѡ x x x ��ͼ1����3�������ģ�� M t M_{t} Mt �ļ���������ͼ1����6����GP������ÿ�ε�������ʱ���� �O H �O \left|\mathcal{H}\right| �OH�O �����������Ų����ڱ��Ż��ı��������Ե����ţ����ǹ������� f ( x ∗ ) f(x^*) f(x∗) �Ļ���ͨ�������ڸ������ɱ���ռ������λ��
3.1 ʹ��GP�Ż�EI
������GP�� f f f ���н�ģ������ y ∗ y^{*} y∗ ����Ϊ�۲� H : y ∗ = m i n { f ( x i ) , 1 ≤ i ≤ n } \mathcal{H}:y^{*}=\mathrm{min}\{f(x_{i}),1\le i \le n\} H:y∗=min{f(xi),1≤i≤n} ���ҵ������ֵ��(1)�е�ģ�� p M pM pM ��֪�� H \mathcal{H} H �ĺ���GP��(1)�е�EI������ƽ�������ӽ������� y ∗ y^{*} y∗ ������Ͳ�ȷ���Ըߵ�Ƿ̽������֮��������ԡ�
EI����ͨ��ͨ������ռ��ϵ��꾡�������������ά�ȵ��������������������Ż���Ȼ��������EI����һЩ������Ϣ���ԴӼļ���ó�[16]��1�������ǷǸ��IJ����� D \mathcal{D} D ��ѵ���㴦Ϊ�㣬2�����̳��˺� k k k ��ƽ���ԣ���ʵ����ͨ������һ�ο��֣�3��EI�������Ǹ߶ȶ�ģ̬�ģ��ر�������ѵ�������������ӡ�[16]������ʹ��ǰ�����EI���ε����������һ�ֻ�������Ľ����㷨���ر���ּ���Ż�EI����EI�����б��ֳ����ڶԸ���Ԥ���������������ǽ������ǵķ�������һ��������������ռ����ɢ���֣��������ɢ���������ϱ����˷ֲ����ƣ�EDA��[17]���������������Ǹ��ݶ���ֲ��Ժ�ѡ����в�����ͬʱ����ʹ��Э���������Ӧ�������ԣ�CMA-ES��[18]����������ռ��ʣ�ಿ�֣���������������CMA-ES��һ�������������Ż������Ƚ������ݶȽ����㷨���ѱ�֤�����ڸ�˹����EDA����ע�⣬�������ݶȷ�������GP�ع�IJ����ںˡ����Dz�������[16]һ��ʹ�û���㷨�����Ǵ��л����λ�ÿ�ʼ�����������������[16]����ʹ�õ�����ϸ���������ǽ�ֹ�ģ���Ϊ���ǵ�����ͨ����ζ�Ź�����10�����ϵ�ά�ȣ���������ڵ������ʵ㿪ʼÿ���ֲ���������ѵ���������ѡȡ���㡣
�������ע����г���������ÿ�����ء����磬������һ�����ز��DBNû����ڶ���������������IJ�������ˣ��ڳ������������ռ��Ϸ���һ��GP�Dz����ġ�����ѡ������״��ʽͨ����ͬʹ�ó��������飬����ÿ�����Ϸ��ò�ͬ�Ķ���GP�����磬����DBN������ζ�Ž�һ��GP���ڳ����ij������ϣ�����ָʾҪ���ǵ�������ķ�����������������е�ÿһ����Ӧ�IJ����ϵ�����GP���Լ�һЩ1άGP�Ƕ������Ƶij���������ZCA������DBN��������1����
4 ��״�ṹParzen���Ʒ�����TPE��
Ԥ�����ǵij������Ż�������ζ�Ÿ�ά�Ⱥ�С��Ӧ������Ԥ������������ת��SMBO�㷨����һ�ֽ�ģ���Ժ�EI�Ż�������Ȼ�����ڸ�˹���̵ķ���ֱ��ģ�� p ( y �O x ) p(y|x) p(y�Ox) ���ò���ģ�� p ( x �O y ) p(x|y) p(x�Oy) �� p ( y ) p(y) p(y) ��
�ع�һ�½��ܣ����ÿռ� X \mathcal{X} X ��ͼ�νṹ�����ɹ������������磬����ѡ����DBN�㣬Ȼ��Ϊÿ��ѡ������������νṹParzen��������TPE��ͨ��ת�����ɹ�����ģ�� p ( x �O y ) p(x|y) p(x�Oy) ���÷Dz����ܶ��滻��ǰ���õķֲ�����ʵ�鲿���У����ǽ�����ʹ�þ��ȣ��������ȣ������������Ⱥͷ���������������ÿռ䡣����Щ����£�TPE�㷨���������滻������ → \to → �ضϸ�˹��� → \to → �������� → \to → ָ���ضϸ�˹��ϣ����� → \to → �ټ�Ȩ���ࡣ�ڷDz����ܶ���ʹ�ò�ͬ�Ĺ۲�ֵ { x ( 1 ) , . . . , x ( k ) } \{x^{(1)},...,x^{(k)}\} {x(1),...,x(k)} ����Щ�滻��ʾ���������ÿռ� X \mathcal{X} X �ϲ��������ܶȵ�ѧϰ�㷨��TPEʹ�������������ܶȶ��� p ( x �O y ) p(x|y) p(x�Oy) ��
p ( x �O y ) = { ℓ ( x ) if y < y ∗ g ( x ) if y ≥ y ∗ , p(x|y) =
{ℓ(x)g(x)amp;if y<y∗amp;if y≥y∗,
p(x�Oy)={ℓ(x)g(x)if y<y∗if y≥y∗,
���� ℓ ( x ) \ell(x) ℓ(x) ��ͨ��ʹ���㷨 { x ( k ) } \{x^{(k)}\} {x(k)} �۲��γɵ��ܶȣ�ʹ����Ӧ����ʧ f ( x ( i ) ) f(x^{(i)}) f(x(i)) С�� y ∗ y^{*} y∗ ������ g ( x ) g(x) g(x) ��ͨ��ʹ��ʣ��۲�ֵ�γɵ��ܶȡ���Ȼ����GP�ķ��������ڻ����� y ∗ y^{*} y∗ ��ͨ��С�ڹ۲쵽�������ʧ������TPE�㷨ȡ���ڴ�����ѹ۲쵽�� f ( x ) f(x) f(x) �� y ∗ y^{*} y∗ ����˿���ʹ��ijЩ�����γ� ℓ ( x ) \ell(x) ℓ(x) ��TPE�㷨ѡ�� y ∗ y^{*} y∗ ��Ϊ�۲쵽�� y y y ֵ��һЩ��λ�� γ \gamma γ ����� p ( y < y ∗ ) = γ p(y\lt y^{*})=\gamma p(y<y∗)=γ ��������Ҫ p ( y ) p(y) p(y) ���ض�ģ�͡�ͨ���� H \mathcal{H} H ��ά���۲쵽�ı����������б���TPE�㷨��ÿ�ε���������ʱ������� �O H �O |\mathcal{H}| �OH�O ���������Ų����ڱ��Ż��ı�����ά�ȣ������������Ե����š�
4.1 �Ż�TPE�㷨�е�EI
ѡ��TPE�㷨�� p ( x , y ) p(x,y) p(x,y) ��Ϊ p ( y ) p ( x �O y ) p(y)p(x|y) p(y)p(x�Oy) �IJ������Դٽ�EI���Ż���
E I y ∗ ( x ) = ∫ − ∞ y ∗ ( y ∗ − y ) p ( y �O x ) d y = ∫ − ∞ y ∗ ( y ∗ − y ) p ( x �O y ) p ( y ) p ( x ) \mathrm{EI}_{y^{*}}(x)=\int_{-\infty}^{y^{*}}(y^{*}-y)p(y|x)dy=\int_{-\infty}^{y^{*}}(y^{*}-y)\frac{p(x|y)p(y)}{p(x)} EIy∗(x)=∫−∞y∗(y∗−y)p(y�Ox)dy=∫−∞y∗(y∗−y)p(x)p(x�Oy)p(y)
ͨ������ γ = p ( y < y ∗ ) \gamma =p(y<y^{*}) γ=p(y<y∗)�� p ( x ) = ∫ R p ( x �O y ) p ( y ) d y = γ ℓ ( x ) + ( 1 − γ ) g ( x ) p\left( x \right) =\int_{\mathbb{R}}{p\left( x|y \right) p\left( y \right) dy=\gamma \ell \left( x \right) +\left( 1-\gamma \right) g\left( x \right)} p(x)=∫Rp(x�Oy)p(y)dy=γℓ(x)+(1−γ)g(x)
��ˣ�
∫ − ∞ y ∗ ( y ∗ − y ) p ( x �O y ) p ( y ) d y = ℓ ( x ) ∫ − ∞ y ∗ ( y ∗ − y ) p ( y ) d y = γ y ∗ ℓ ( x ) − ℓ ( x ) ∫ − ∞ y ∗ p ( y ) d y \int_{-\infty}^{y^*}{\left( y^*-y \right) p\left( x|y \right) p\left( y \right) \text{d}y}=\ell \left( x \right) \int_{-\infty}^{y^*}{\left( y^*-y \right)}p\left( y \right) dy=\gamma y^*\ell \left( x \right) -\ell \left( x \right) \int_{-\infty}^{y^*}{p\left( y \right) dy} ∫−∞y∗(y∗−y)p(x�Oy)p(y)dy=ℓ(x)∫−∞y∗(y∗−y)p(y)dy=γy∗ℓ(x)−ℓ(x)∫−∞y∗p(y)dy
���
E I y ∗ ( x ) = γ y ∗ ℓ ( x ) − ℓ ( x ) ∫ − ∞ y ∗ p ( y ) d y γ ℓ ( x ) + ( 1 − γ ) g ( x ) ∝ ( γ + g ( x ) ℓ ( x ) ( 1 − γ ) ) − 1 EI_{y^*}\left( x \right) =\frac{\gamma y^*\ell \left( x \right) -\ell \left( x \right) \int_{-\infty}^{y^*}{p\left( y \right) dy}}{\gamma ^{\ell \left( x \right)}+\left( 1-\gamma \right) g\left( x \right)}\propto \left( \gamma +\frac{g\left( x \right)}{\ell \left( x \right)}\left( 1-\gamma \right) \right) ^{-1} EIy∗(x)=γℓ(x)+(1−γ)g(x)γy∗ℓ(x)−ℓ(x)∫−∞y∗p(y)dy∝(γ+ℓ(x)g(x)(1−γ))−1
���һ������ʽ������Ϊ����Ľ�������ϣ���ڵ� x x x �� ℓ ( x ) \ell(x) ℓ(x) ���ʸ�ͬʱ g ( x ) g(x) g(x) ���ʵ͡� ℓ \ell ℓ �� g g g ����״�ṹ��ʽʹ�ø��� ℓ \ell ℓ ���������ѡ�߲��Ҹ��� g ( x ) / ℓ ( x ) g(x)/\ell(x) g(x)/ℓ(x) ���������������ġ���ÿ�ε����У��㷨���ؾ������EI�ĺ�ѡ�㷨 x ∗ x^{*} x∗��
4.2 Parzen Estimator��ϸ��
ģ�� ℓ ( x ) \ell(x) ℓ(x) �� g ( x ) g(x) g(x) ���漰��ɢֵ������ֵ�����ķֲ���̡�����ӦParzen������ͨ���� K K K �۲�ֵ B = { x ( 1 ) , . . . , x ( k ) } ⊂ H \mathcal{B}=\{x^{(1)},...,x^{(k)}\} \subset\mathcal{H} B={x(1),...,x(k)}⊂H ��������һ��ģ�Ͷ��� X \mathcal{X} X �ϲ���ģ�͡�ÿ��������������һ����� ( a , b ) (a, b) (a,b) ���˹��������ȷֲ��ľ�������ָ����TPE���� x ( i ) ∈ B x(i)\in\mathcal{B} x(i)∈B �е�ÿһ��Ϊ���ĵĸ�˹������������ĵȼ�Ȩ��ϡ�ÿ����˹�����ı������Ϊ��������ڵ�����еĽϴ��ߣ����ǻᱻ������������Χ�ڡ��ھ��ȵ�����£��� a a a �� b b b ����Ϊ��DZ�ڵ��ڵ㡣������ɢ���������������� N N N ������ p i p_{i} pi��������������Ԫ���� N p i + C i N_{p_{i}}+C_{i} Npi+Ci �ɱ��������� C i C_{i} Ci ���� B \mathcal{B} B ��ѡ�� i i i �ij��֡��������ȳ������ڶ������б���Ϊ���ȡ�
��1���������������DBN�������ֲ�����“��”�ָ���ѡ���Ԥ����������������ӣ�����Ȩ����ȡ����� U U U ��ʾ���ȣ� N \mathcal{N} N ��ʾ��˹�ֲ��� l o g U log\ U log U ��ʾ���ȷֲ��ڶ������С�CD��Ҳ��ΪCD-1�������Աȷ��磬���㷨���ڳ�ʼ��DBN�IJ������

5 �������DBN�еij������Ż�
��ʽ���������Ż���һ�������µIJ�����ʹ���������[5]��[19]�������������������������Ч���Ż�����������������IJ������ڱ����У�����������DBN�Ż��������������[1]�н��е�˳���������ֶ�������Ƚϡ�
����ѡ����ǰ��1���г���������DBN�����ϵ������ռ䡣[1]���ṩ�����ݼ���ϸ�ڣ�DBNģ���Լ�����CD��̰���ֲ�ѵ�����衣�������Ӧ��[1]�������ռ䣬�������²��죺(a)��������ZCAԤ����[20]��(b)��������ÿ������в�ͬ�Ĵ�С��©������������ÿ���㶼���Լ���CDѵ��������(d)��������������ֵ������ΪCD�㷨�еIJ�Ŭ����ֵ�������ϸ���ȷ����Ŭ�������������ͣ����Լ�(e)����û�н�ʵֵ�������Ŀ���ֵ��ɢ������Щ�仯��չ�˳������������⣬ͬʱ��ԭʼ�����������ռ䱣��Ϊ��չ�����ռ���Ӽ���
�ó�����������Ľ����ͼ2��ʾ��
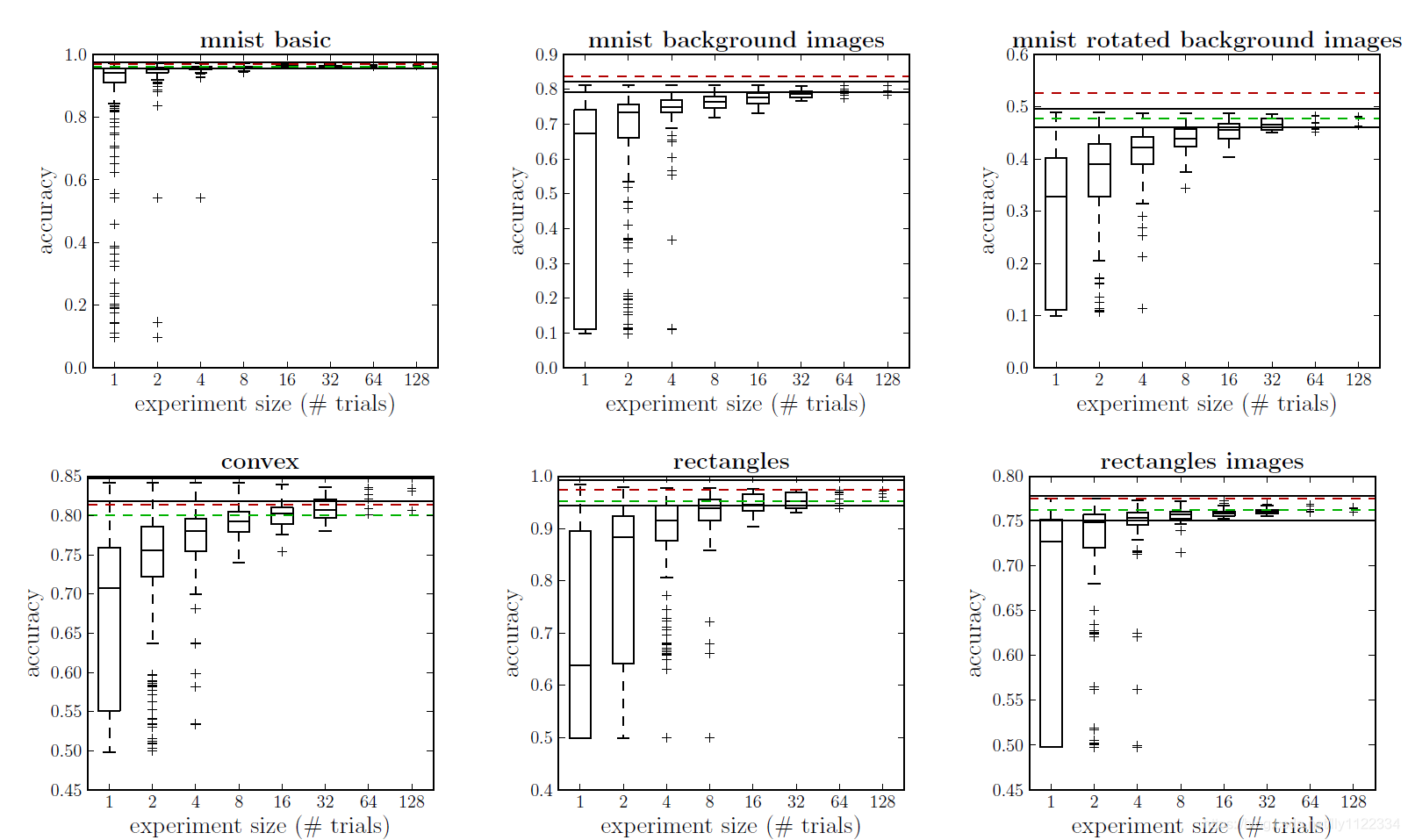
ͼ2������������磨DBN�������ܸ�����������������������̽�����32�����������μ���1����ʹ���������������ֶ��������������Ͻ��еĽ��ƽ��41����������ɫ��1��DBN���ͺ�ɫ��3��DBN��������ÿ������ͼ������ N = 1 , 2 , 4... N=1,2,4... N=1,2,4...)��ʾ��ѡ��N����������е����ģ��ʱ���Լ����ܵķֲ��� ���ݼ�“convex”��“mnist��ת����ͼ��”���ڸ����ij������Ż���
Ҳ�����˾��ȵ��ǣ��ֶ������Ľ�������뼸�����ݼ���32���������ɿ���ƥ�䡣��[21]�н�һ��̽���˴����������������Ч�ʡ������������������������ƥ�������£���ͼ2�в������ԭ�������Ƿ���Ч��������ԭʼ�ռ䣬�����������˸������ҵ��������ܵĸ���ռ䡣�����������ͨ����������Ŀռ���ij�ַ�ʽ���ķ���������෴��——��1���г��������ռ��dz������Ż��������Ȼ����������[1]�Ըÿռ�����ƿ����Ǽ��������⣬ʹ�������������������ֶ��������ؼ����ǣ������ַ���������ͬ�����ݼ���ѵ��DBN��
ͼ2�еĽ������������ijЩ���ݼ����������Ż����ѡ����磬��“MNIST��ת����ͼ��”���ݼ���MRBI��������£���������ƺ���ԽϿ�����������ֵ��32�������ʵ���е����ģ����ʾ���ܲ����С����������ȶ�ˮƽ�����ֶ�����������һ�����ݼ���convex���У���������������ֶ����������ܣ����������κ����͵�ƽ̨����������ѡ��32��ģ���е����ģ��ʱ�����������൱��IJ��졣���ֻ������������������и��õ����ܣ���������Ҫ����Ч���������ÿռ�����ҵ��������ĵ����ಿ��̽�������������ݼ��ij������Ż���˳���Ż����ԣ�convex��MRBI��
6 ��DBN��˳�������������Ż�
����ͨ���벨ʿ�ٷ������ݼ��ϵ�����������бȽ���֤�˵�3.1�ڵ�GP����������һ����13�������������ͱ����ع������ɵ�506����Ļع���������ѵ����һ������10���������Ķ���֪����MLP��������ѧϰ�ʣ� ℓ 1 \ell_{1} ℓ1 �� ℓ 2 \ell_{2} ℓ2 �ͷ������ز�Ĵ�С�������������Ƿ�Ӧ��PCAԤ��������������Ψһ���������ij�����[22]�����ǵĽ����ͼ3��ʾ��ǰ30�ε�����ʹ������������еģ����ӵ�30�ο�ʼ�����ǽ�����������ڸ�����ʷ��ѵ����GP�������ֿ�������ʵ���ظ���20�Ρ�������ά����ȵ�������ر��٣���������ģ�����������������Ը��õĵ�����֧�ֽ�SMBO����Ӧ���ڸ����IJ�������������ݼ���
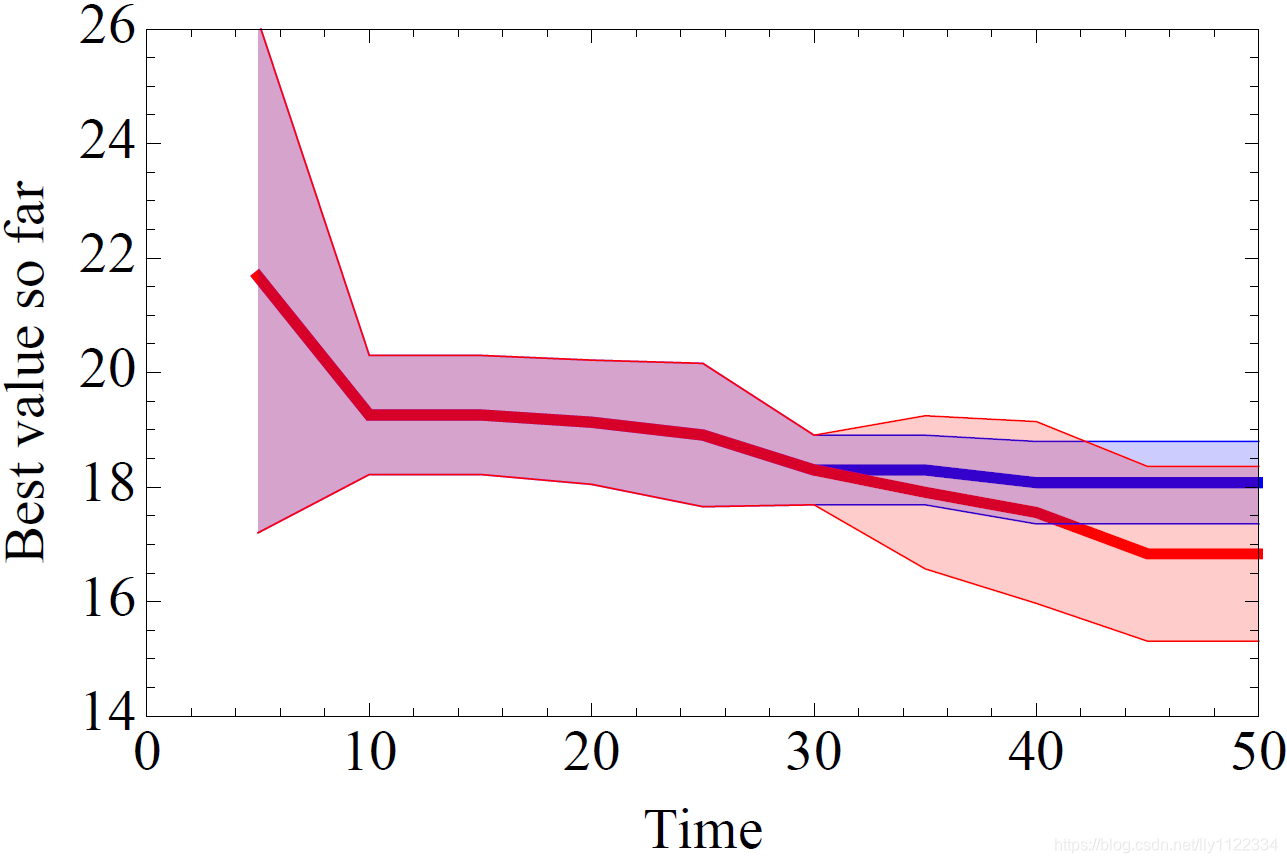
ͼ3����ʱ��30֮��GP�Ż���ʿ�ٷ��ۻع������е�MLP�������� ��ĿǰΪֹ��ÿ5�ε������ֵ������Сֵ����ʱ����ء� ��ɫ=GP����ɫ=�������Ӱ����=1-sigma�������

��2��ÿ�������㷨���ÿ�������ҵ������ģ�͵IJ��Լ��������ÿ�������㷨�������200�����顣�ֶ�����ʹ��82������convex��27������MRBI��
��GPӦ�����Ż�DBN���ܵ����⣬��������ÿ������ x ∗ x^{*} x∗ ��CMA + ES�㷨����3��������������������GP�ij��ȳ߶�ʱ�������500�ε����Ĺ����ݶȷ�����ƽ��ָ���ں�[14]����ÿ���ڵ㡣GP��CMA-ES����ʹ�óͷ����������߽磬����ʽ�������ֱ����ϴ��������� H \mathcal{H} H ����30������������ʼ��GP�㷨����200�������ʹ�ø�GPԤ��� x ∗ x^{*} x∗ ��Ҫ��Լ150�롣���ڻ���TPE���㷨������ѡ���� γ = 0.15 \gamma=0.15 γ=0.15 ��������ÿ�ε����д� ℓ ( x ) \ell(x) ℓ(x) �г�ȡ��100����ѡ�е����ѡ��Ϊ���� x ∗ x^{*} x∗ ����200������֮��ʹ�ø�TPE�㷨Ԥ��� x ∗ x^{*} x∗ ��Ҫ��Լ10�롣����TPE���Ż������г���������������ij�ʼ���ޣ���GP����������������������Ż������б����ڳ�ʼ�����ڡ�TPE�㷨��30�������������г�ʼ����GP�㷨Ҳͬ������30����������㲥�֡�
6.1 ���л�˳������
GP��TPE����ʵ�������첽���еģ��Ա����ö������ڵ㲢�����˷�ʱ��ȴ�����������ɡ�����GP������ʹ����ν�ĺ㶨ƭ�ӣ�constant liar��������ÿ�������ѡ�� x ∗ {x^{*}} x∗ ʱ����ʱ�������ѵ���� D \mathcal{D} D �ڵ� y y y'��ƽ��ֵ�ļ���Ӧ��������ֱ���������Ϊֹ�� ������ʵ����ʧloss f ( x ∗ ) f(x^{*}) f(x∗)������TPE���������Ǽغ������������ĵ㣬������������ ℓ ( x ) \ell(x) ℓ(x) ���Ƶ���������ṩ��һ�ε�������һ�ε����IJ�ͬ��ѡ�����л��Ľ����ÿ������ x ∗ x^{*} x∗ �����ڽ��ٵķ�������ʹ����Ч�ʽ��ͣ�����ǽ��ʱ��ʱ�䷽����졣
�����Ƿ���GTX 285,470,480��580��ִ�У�ÿ�����������ʱ������Ϊ1СʱGPU���㡣���������Ļ���֮����ٶȲ����������ϴ�Լ����������ʵ�ʵļ���Ч�ʻ�ȡ���ڻ����ĸ��غ���������ã���ͬ��������ٶ��ڲ�ͬ�������������Dz�ͬ�ģ���ͨ��GP��TPE�㷨�Զ�������IJ���������ÿ��ʵ��ʹ�����GPU���Ѵ�Լ24Сʱ�Ĵ���ʱ�䡣
7 ����
ÿ���㷨�����Ĺ켣�� H \mathcal{H} H�����200������ͼ4��ʾ���������������[1]�н��е��ֶ����������˱Ƚϡ�
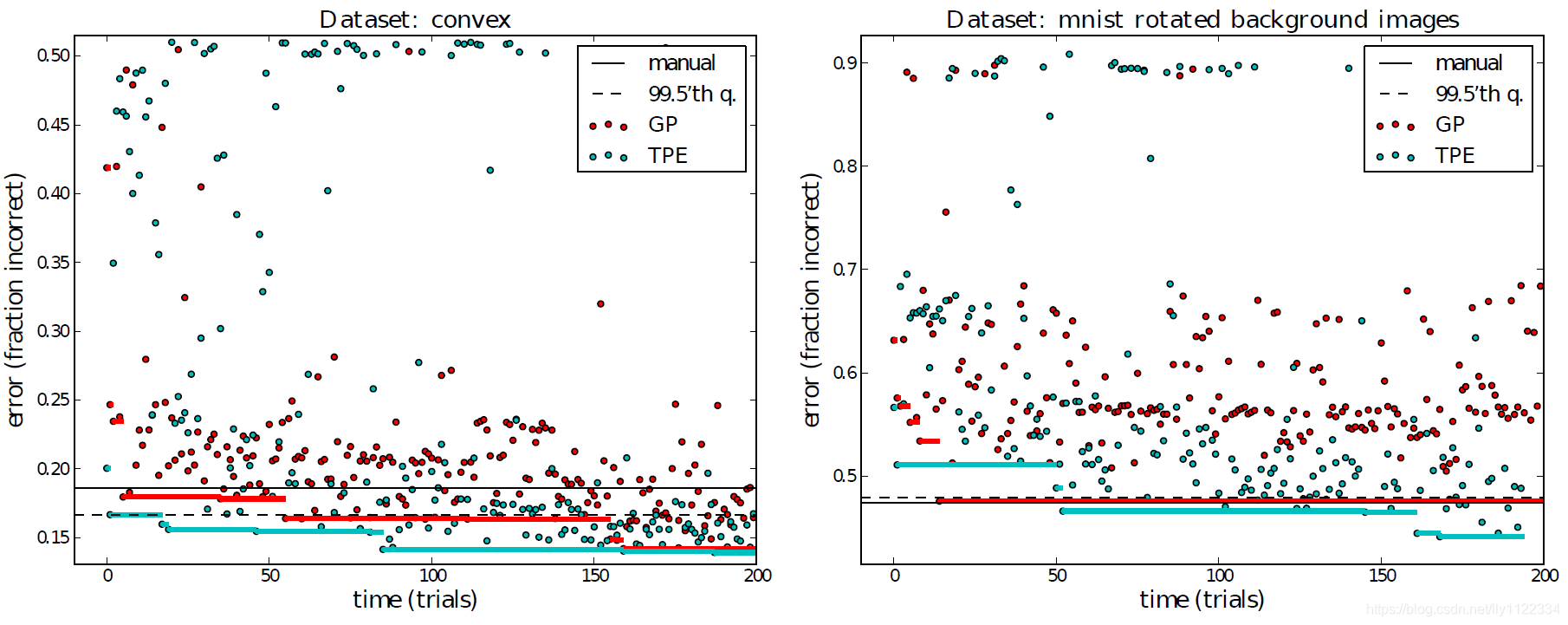
ͼ4�����ڸ�˹���̣�GP���ͻ���ͼ��ģ�ͣ�TPE��˳���Ż��㷨��Ч�ʣ�������convex������MRBI�����ң����Ż���������DBN����֤�����ܵ�������ÿ��SMBO�㷨�����Ĺ켣 H \mathcal{H} H ��Ԫ�ء���ɫ������ÿ��ʱ���֮ǰ�ҵ�������������֤��ȷ�ȡ�TPE��GP�㷨�����������ʼ������ȡ�����������������Ҵ�������ֶ��������������������convex����������֤������95������������ÿ������Ϸ����·�����0.018����MRBI��������ÿ������Ϸ����·�����0.021��ʵ�ߺ���������ר��ʹ�������������ֶ�����[1]����ϻ�õIJ��Լ����ȡ������Ǵ�����֮ǰ�ķֲ����μ���1���г����������з��ֵ�99.5����֤���ܵķ�λ�����ֱ�����������ݼ���457��361�����������㡣
ʹ����Щ�㷨�������㷨�ҵ������ģ�͵ķ����������ڱ�2�С���convex���ݼ��������ࣩ�ϣ������㷨��������13��������֤�������ܵ���˵��TPE�����ģ����14.1��������GP�����ģ����16.7����TPE�����Ч�����������ֶ�������19�������������200�����飨17��������MRBI���ݼ���ʮ���ࣩ�ϣ���������DZ������ģ�50������GP�������ֶ�����������أ�47��������TPE�㷨�������µ���ѽ����44���������ر���TPE�㷨�ҵ���ģ�ͱ���ǰ���������ݼ����ҵ���ģ�Ͷ�Ҫ�á�GP��TPE�㷨��Ч���Ե����ֶ�������GP��EI��80�������дﵽ�����ֶ������൱�����ܣ�[1]���ֶ�����ʹ����82��convex�����27��MRBI���顣
TPE���������������ݼ��еı�������GP�����м��ֿ��ܵ�ԭ��Ҳ�� p ( x �O y ) p(x|y) p(x�Oy) ����ֽ�ȸ�˹�����е� p ( y �O x ) p(y|x) p(y�Ox) ��ȷ���������෴��TPEȱ��ȷ��������̽�����֤����һ�ֺܺõ���������ʽ�㷨��Ҳ��GP���������ij�����û������Ϊ��DBN���ÿռ�����ȷ��Ȩ�����ú�̽������Ҫ�����ʵ֤�о���������Щ���衣Ȼ����������Ҫ���ǣ������ĸ�SMBO���ж�ƥ����������������ϸ���˹�������������Щ����Ŀǰ�dz������Ż������Ƚ�������
GP��TPE�㷨�������������ж��������ã�������Щ�㷨��ҪһЩ��ȷ�����ã�ʵ����SMBO�㷨һ�㲻��ܺá�˳���Ż��㷨ͨ�����ù۲쵽�� ( x , y ) (x,y) (x,y) ���еĽṹ������������ p ( y �O x ) p(y|x) p(y�Ox) �Ĵ���ѡ��SMBO���������ⲻ�õġ�������� H \mathcal{H} H ����ȡ�����¾ֲ����ŵĽṹ�����ڷ��־������Ժõ� p ( y �O x ) p(y|x) p(y�Ox) ��ȫ������ʱ��Ҳ���ܱ������������
8 ����
���Ľ��������������ij������Ż��㷨����֤���������漰DBN���������ѵij������Ż�������������˵����ܺ�����������������ܡ������������ռ��Ϸſ��˱�Լ�������磬���в��ϵ����ͼ���С���������˵�32��������������ɢ�����������������ĸ���Ȼ�ij������ռ䣬�������������ʱ����أ�����ȡ��������������ֵ������������������32ά���������У�������ܵ�TPE�㷨�Ѿ������������ݼ��Ϸ������µ���ѽ������Щ�����������֮ǰ��Ϊ��DBN�����⣬GP��TPE�㷨��ʵ�õģ�ÿ�����ݼ����Ż���ʹ��5��GPU��������24Сʱ����ɡ���Ȼ���ǵĽ����������DBN�������ǵķ����dz�ͨ�ã�������Ȼ����չ���κγ������Ż����⣬���г������Ǵӿɲ����ļ�������ȡ�ġ�
����ϣ�����ǵĹ������Լ�������ѧϰ�������о���Ա���������Ż�������Ϊ����ѧϰ�㷨��һ����Ȥ����Ҫ����ɲ��֡�“DBN��convex�����Ч����Σ�”������Ⲣ����һ����ȫ����ġ������Ͽɻش������——�������Ż��IJ�ͬ�����������ͬ�Ĵ𰸡��������Ż����㷨����ʹ����ѧϰ��������״��������ֺ�ת�Ƶ������������ڴ�����ľ����㷨������ijЩ�����Ҳ�ܹ��ҵ�����ǰ��֪�ĸ��õĽ�������ǿ��ij������Ż��㷨�ؿ��˿���ʵ���о���ģ�͵ķ�Χ���о���Ա����Ҫ���Լ�������һЩ�����ֶ������ı���ϵͳ��
�������������TPE�㷨�Լ��������������ܹ�����ΪBSD���ɵ���ѿ�Դ�����ṩ����������������������������ֽ�������һ����Դٽ���Щ���������������Ż��������Ƶ��㷨��
Hyperopt��https://github.com/jaberg/hyperopt
��л
������õ��˼��ô���ҿ�ѧ�빤���о�ίԱ�ᣬCompute Canada�Լ����������о�������ANR-2010-COSI-002������ DBNģ�͵�GPUʵ����Theano [23]�ṩ��
�����
[1] H. Larochelle, D. Erhan, A. Courville, J. Bergstra, and Y. Bengio. An empirical evaluation of deep architectures on problems with many factors of variation. In ICML 2007, pages 473–480, 2007.
[2] G. E. Hinton, S. Osindero, and Y. Teh. A fast learning algorithm for deep belief nets. Neural omputation, 18:1527–1554, 2006.
[3] P. Vincent, H. Larochelle, I. Lajoie, Y. Bengio, and P. A. Manzagol. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. Machine Learning
Research, 11:3371–3408, 2010.
[4] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, November 1998.
[5] Nicolas Pinto, David Doukhan, James J. DiCarlo, and David D. Cox. A high-throughput screening approach to discovering good forms of biologically inspired visual representation. PLoS Comput Biol, 5(11):e1000579, 11 2009.
[6] A. Coates, H. Lee, and A. Ng. An analysis of single-layer networks in unsupervised feature learning.
NIPS Deep Learning and Unsupervised Feature Learning Workshop, 2010.
[7] A. Coates and A. Y. Ng. The importance of encoding versus training with sparse coding and vector quantization. In Proceedings of the Twenty-eighth International Conference on Machine Learning (ICML-11), 2010.
[8] F. Hutter. Automated Configuration of Algorithms for Solving Hard Computational Problems. PhD thesis, University of British Columbia, 2009.
[9] F. Hutter, H. Hoos, and K. Leyton-Brown. Sequential model-based optimization for general algorithm configuration. In LION-5, 2011. Extended version as UBC Tech report TR-2010-10.
[10] D.R. Jones. A taxonomy of global optimization methods based on response surfaces. Journal of Global Optimization, 21:345–383, 2001.
[11] J. Villemonteix, E. Vazquez, and E. Walter. An informational approach to the global optimization of
expensive-to-evaluate functions. Journal of Global Optimization, 2006.
[12] N. Srinivas, A. Krause, S. Kakade, and M. Seeger. Gaussian process optimization in the bandit setting:
No regret and experimental design. In ICML, 2010.
[13] J. Mockus, V. Tiesis, and A. Zilinskas. The application of Bayesian methods for seeking the extremum.
In L.C.W. Dixon and G.P. Szego, editors, Towards Global Optimization, volume 2, pages 117–129. North
Holland, New York, 1978.
[14] C.E. Rasmussen and C. Williams. Gaussian Processes for Machine Learning.
[15] D. Ginsbourger, D. Dupuy, A. Badea, L. Carraro, and O. Roustant. A note on the choice and the estimation of kriging models for the analysis of deterministic computer experiments. 25:115–131, 2009.
[16] R. Bardenet and B. K´egl. Surrogating the surrogate: accelerating Gaussian Process optimization with
mixtures. In ICML, 2010.
[17] P. Larra˜naga and J. Lozano, editors. Estimation of Distribution Algorithms: A New Tool for Evolutionary Computation. Springer, 2001.
[18] N. Hansen. The CMA evolution strategy: a comparing review. In J.A. Lozano, P. Larranaga, I. Inza, and
E. Bengoetxea, editors, Towards a new evolutionary computation. Advances on estimation of distribution
algorithms, pages 75–102. Springer, 2006.
[19] J. Bergstra and Y. Bengio. Random search for hyper-parameter optimization. The Learning Workshop
(Snowbird), 2011.
[20] A. Hyv¨arinen and E. Oja. Independent component analysis: Algorithms and applications. Neural Networks, 13(4–5):411–430, 2000.
[21] J. Bergstra and Y. Bengio. Random search for hyper-parameter optimization. JMLR, 2012. Accepted.
[22] C. Bishop. Neural networks for pattern recognition. 1995.
[23] J. Bergstra, O. Breuleux, F. Bastien, P. Lamblin, R. Pascanu, G. Desjardins, J. Turian, and Y. Bengio.
Theano: a CPU and GPU math expression compiler. In Proceedings of the Python for Scientific Computing
Conference (SciPy), June 2010.
���ѧϰ���������ܼ����β���
ʲô�dz�����������������Щ�� |