这篇教程神经网络梯度消失和梯度爆炸及解决办法写得很实用,希望能帮到您。
神经网络梯度消失和梯度爆炸及解决办法
一、神经网络梯度消失与梯度爆炸
(1)简介梯度消失与梯度爆炸
层数比较多的神经网络模型在训练的时候会出现梯度消失(gradient vanishing problem)和梯度爆炸(gradient exploding problem)问题。梯度消失问题和梯度爆炸问题一般会随着网络层数的增加变得越来越明显。
例如,对于图1所示的含有3个隐藏层的神经网络,梯度消失问题发生时,靠近输出层的hidden layer 3的权值更新相对正常,但是靠近输入层的hidden layer1的权值更新会变得很慢,导致靠近输入层的隐藏层权值几乎不变,扔接近于初始化的权值。这就导致hidden layer 1 相当于只是一个映射层,对所有的输入做了一个函数映射,这时此深度神经网络的学习就等价于只有后几层的隐藏层网络在学习。梯度爆炸的情况是:当初始的权值过大,靠近输入层的hidden layer 1的权值变化比靠近输出层的hidden layer 3的权值变化更快,就会引起梯度爆炸的问题。

(2)梯度不稳定问题
在深度神经网络中的梯度是不稳定的,在靠近输入层的隐藏层中或会消失,或会爆炸。这种不稳定性才是深度神经网络中基于梯度学习的根本问题。
梯度不稳定的原因:前面层上的梯度是来自后面层上梯度的乘积。当存在过多的层时,就会出现梯度不稳定场景,比如梯度消失和梯度爆炸。
(3)产生梯度消失的根本原因
我们以图2的反向传播为例,假设每一层只有一个神经元且对于每一层都可以用公式1表示,其中σ为sigmoid函数,C表示的是代价函数,前一层的输出和后一层的输入关系如公式1所示。我们可以推导出公式2。

而sigmoid函数的导数如图3所示。
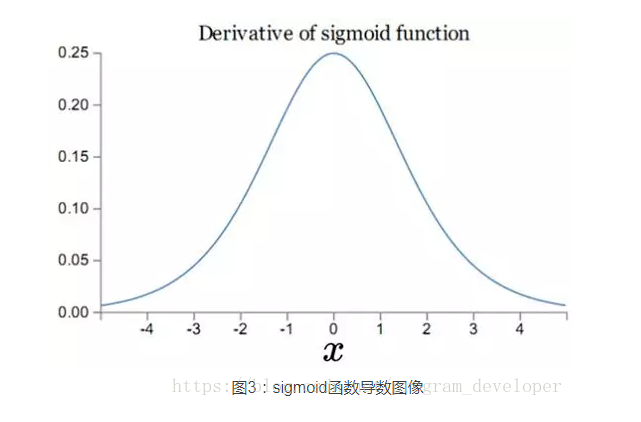
可见,的最大值为,而我们一般会使用标准方法来初始化网络权重,即使用一个均值为0标准差为1的高斯分布。因此,初始化的网络权值通常都小于1,从而有。对于2式的链式求导,层数越多,求导结果越小,最终导致梯度消失的情况出现。

图4:梯度变化的链式求导分析
对于图4,和有共同的求导项。可以看出,前面的网络层比后面的网络层梯度变化更小,故权值变化缓慢,从而引起了梯度消失问题。
(4)产生梯度爆炸的根本原因
当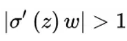 ,也就是w比较大的情况。则前面的网络层比后面的网络层梯度变化更快,引起了梯度爆炸的问题。 ,也就是w比较大的情况。则前面的网络层比后面的网络层梯度变化更快,引起了梯度爆炸的问题。
(5)当激活函数为sigmoid时,梯度消失和梯度爆炸哪个更容易发生?
结论:梯度爆炸问题在使用sigmoid激活函数时,出现的情况较少,不容易发生。
量化分析梯度爆炸时x的取值范围:因导数最大为0.25,故>4,才可能出现;按照可计算出x的数值变化范围很窄,仅在公式3范围内,才会出现梯度爆炸。画图如5所示,可见x的数值变化范围很小;最大数值范围也仅仅0.45,当=6.9时出现。因此仅仅在此很窄的范围内会出现梯度爆炸的问题。
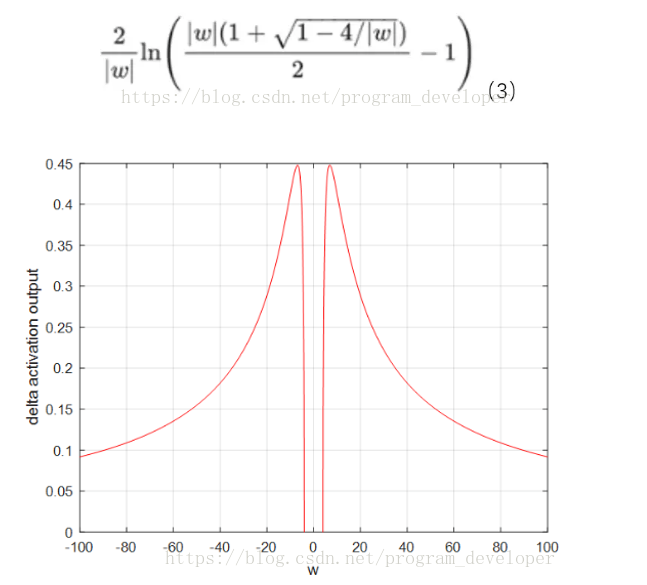
图5:x的数值变化范围
(6)如何解决梯度消失和梯度爆炸
梯度消失和梯度爆炸问题都是因为网络太深,网络权值更新不稳定造成的,本质上是因为梯度反向传播中的连乘效应。对于更普遍的梯度消失问题,可以考虑一下三种方案解决:
1. 用ReLU、Leaky-ReLU、P-ReLU、R-ReLU、Maxout等替代sigmoid函数。
2. 用Batch Normalization。
3. LSTM的结构设计也可以改善RNN中的梯度消失问题。
二、几种激活函数的比较
由于使用sigmoid激活函数会造成神经网络的梯度消失和梯度爆炸问题,所以许多人提出了一些改进的激活函数,如:用ReLU、Leaky-ReLU、P-ReLU、R-ReLU、Maxout等替代sigmoid函数。下面我们具体来分析一下这几个激活函数的区别。
(1) Sigmoid
Sigmoid是常用的非线性的激活函数,它的数学形式如公式4:
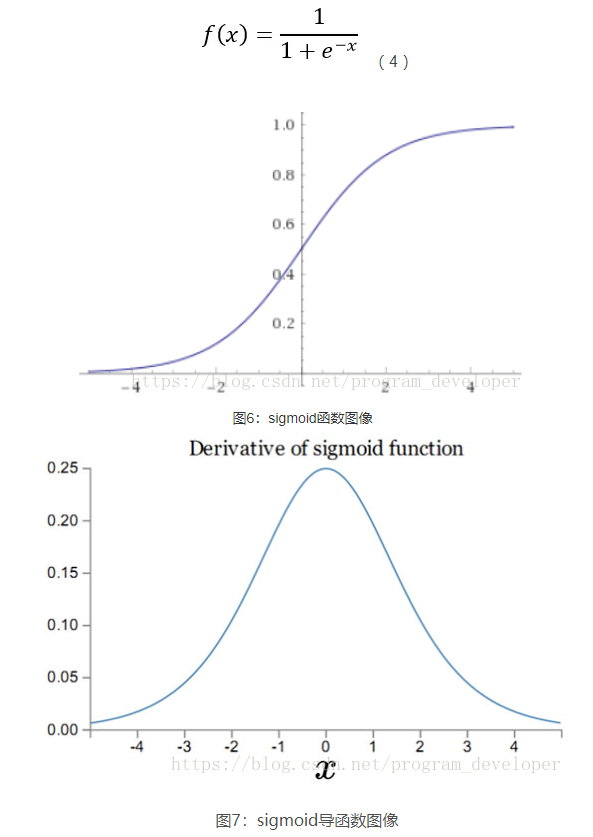
Sigmoid函数在历史上曾经非常的常用,输出值范围为[0,1]之间的实数。然而现在它已经不太受欢迎,实际中很少使用。原因是sigmoid存在3个问题:
1.sigmoid函数饱和使梯度消失(Sigmoidsaturate and kill gradients)。
我们从图7可以看到sigmoid的导数都是小于0.25的,那么在进行反向传播的时候,梯度相乘结果会慢慢的趋近于0。这样,几乎就没有梯度信号通过神经元传递到前面层的梯度更新中,因此这时前面层的权值几乎没有更新,这就叫梯度消失。除此之外,为了防止饱和,必须对于权重矩阵的初始化特别留意。如果初始化权重过大,可能很多神经元得到一个比较小的梯度,致使神经元不能很好的更新权重提前饱和,神经网络就几乎不学习。
2.sigmoid函数输出不是“零为中心”(zero-centered)。
一个多层的sigmoid神经网络,如果你的输入x都是正数,那么在反向传播中w的梯度传播到网络的某一处时,权值的变化是要么全正要么全负。

解释下:当梯度从上层传播下来,w的梯度都是用x乘以f的梯度,因此如果神经元输出的梯度是正的,那么所有w的梯度就会是正的,反之亦然。在这个例子中,我们会得到两种权值,权值范围分别位于图8中一三象限。当输入一个值时,w的梯度要么都是正的要么都是负的,当我们想要输入一三象限区域以外的点时,我们将会得到这种并不理想的曲折路线(zig zag path),图中红色曲折路线。假设最优化的一个w矩阵是在图8中的第四象限,那么要将w优化到最优状态,就必须走“之字形”路线,因为你的w要么只能往下走(负数),要么只能往右走(正的)。优化的时候效率十分低下,模型拟合的过程就会十分缓慢。
如果训练的数据并不是“零为中心”,我们将多个或正或负的梯度结合起来就会使这种情况有所缓解,但是收敛速度会非常缓慢。该问题相对于神经元饱和问题来说还是要好很多。具体可以这样解决,我们可以按batch去训练数据,那么每个batch可能得到不同的信号或正或负,这个批量的梯度加起来后可以缓解这个问题。
3.指数函数的计算是比较消耗计算资源的。
(2) tanh
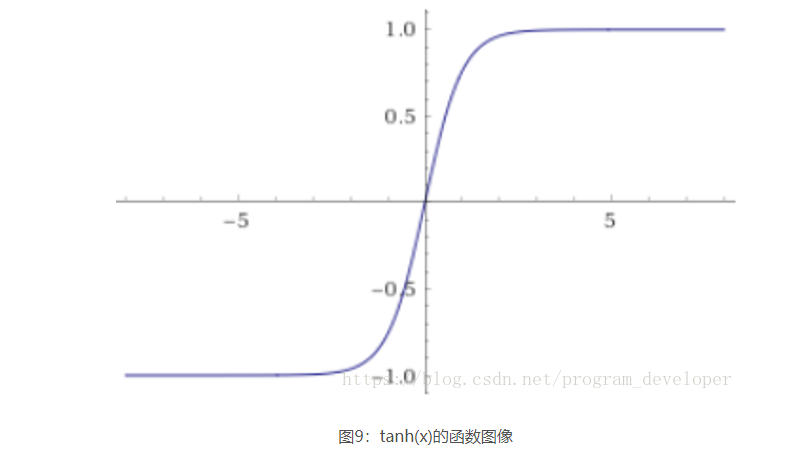
tanh函数跟sigmoid还是很像的,实际上,tanh是sigmoid的变形如公式5所示。tanh的具体公式如公式6所示。
tanh与sigmoid不同的是,tanh是“零为中心”的。因此,实际应用中,tanh会比sigmoid更好一些。但是在饱和神经元的情况下,还是没有解决梯度消失问题。
优点:
1.tanh解决了sigmoid的输出非“零为中心”的问题。
缺点:
1.依然有sigmoid函数过饱和的问题。
2.依然指数运算。
(3) ReLU
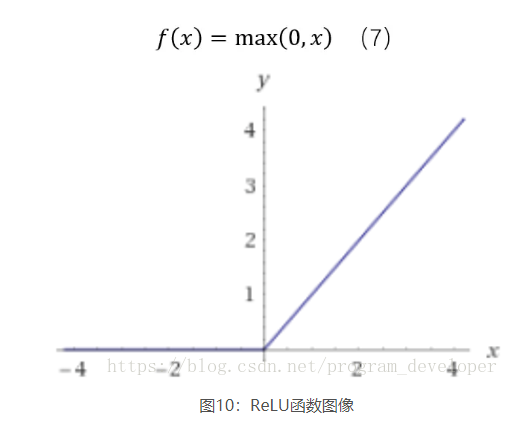
近年来,ReLU函数变得越来越受欢迎。全称是Rectified Linear Unit,中文名字:修正线性单元。ReLU是Krizhevsky、Hinton等人在2012年《ImageNet Classification with Deep Convolutional Neural Networks》论文中提出的一种线性且不饱和的激活函数。它的数学表达式如7所示:
优点:
1.ReLU解决了梯度消失的问题,至少x在正区间内,神经元不会饱和。
2.由于ReLU线性、非饱和的形式,在SGD中能够快速收敛。
3.计算速度要快很多。ReLU函数只有线性关系,不需要指数计算,不管在前向传播还是反向传播,计算速度都比sigmoid和tanh快。
缺点:
1.ReLU的输出不是“零为中心”(Notzero-centered output)。
2.随着训练的进行,可能会出现神经元死亡,权重无法更新的情况。这种神经元的死亡是不可逆转的死亡。
解释:训练神经网络的时候,一旦学习率没有设置好,第一次更新权重的时候,输入是负值,那么这个含有ReLU的神经节点就会死亡,再也不会被激活。因为:ReLU的导数在x>0的时候是1,在x<=0的时候是0。如果x<=0,那么ReLU的输出是0,那么反向传播中梯度也是0,权重就不会被更新,导致神经元不再学习。
也就是说,这个ReLU激活函数在训练中将不可逆转的死亡,导致了训练数据多样化的丢失。在实际训练中,如果学习率设置的太高,可能会发现网络中40%的神经元都会死掉,且在整个训练集中这些神经元都不会被激活。所以,设置一个合适的较小的学习率,会降低这种情况的发生。为了解决神经元节点死亡的情况,有人提出了Leaky ReLU、P-ReLu、R-ReLU、ELU等激活函数。
(4) Leaky ReLU
ReLU是将所有的负值设置为0,造成神经元节点死亡情况。相反,Leaky ReLU是给所有负值赋予一个非零的斜率。Leaky ReLU激活函数是在声学模型(2013)中首次提出来的。它的数学表达式如公式8所示。
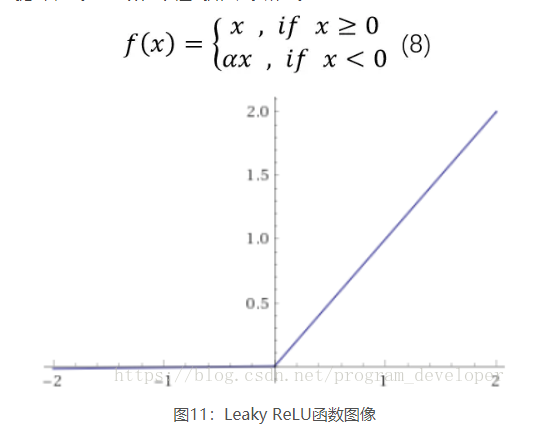
Leaky ReLU很好的解决了“dead ReLU”的问题。因为Leaky ReLU保留了x小于0时的梯度,在x小于0时,不会出现神经元死亡的问题。对于Leaky ReLU给出了一个很小的负数梯度值α,这个值是很小的常数。比如:0.01。这样即修正了数据分布,又保留了一些负轴的值,使得负轴信息不会全部丢失。但是这个α通常是通过先验知识人工赋值的。
优点:
1.神经元不会出现死亡的情况。
2.对于所有的输入,不管是大于等于0还是小于0,神经元不会饱和。
2.由于Leaky ReLU线性、非饱和的形式,在SGD中能够快速收敛。
3.计算速度要快很多。Leaky ReLU函数只有线性关系,不需要指数计算,不管在前向传播还是反向传播,计算速度都比sigmoid和tanh快。
缺点:
1.Leaky ReLU函数中的α,需要通过先验知识人工赋值。
扩展材料:
1.Andrew L. Maas, Awni Y. Hannum and Andrew Y. Ng. Rectified NonlinearitiesImprove Neural Network Acoustic Models (PDF). ICML.2013. 该论文提出了Leaky ReLU函数。
2.He K, Zhang X, Ren S, et al. Delving deepinto rectifiers: Surpassing human-level performance on imagenetclassification[C]//Proceedings of the IEEE international conference on computervision. 2015: 1026-1034. 该论文介绍了用Leaky ReLU函数的好处。
(5) PReLU
PReLU的英文全称为“Parametric ReLU”,我翻译为“带参数的线性修正单元”。我们观察Leaky ReLU可知,在神经网络中通过损失函数对α求导数,我们是可以求得的。那么,我们可不可以将它作为一个参数进行训练呢?在Kaiming He的论文《Delving deepinto rectifiers: Surpassing human-level performance on imagenet classification》中指出,α不仅可以训练,而且效果更好。

公式9非常简单,,表示还未经过激活函数的神经元输出。论文中指出,使用了Parametric ReLU后,最终效果比不用提高了1.03%。
扩展材料:
He K, Zhang X, Ren S, et al. Delving deepinto rectifiers: Surpassing human-level performance on imagenetclassification[C]//Proceedings of the IEEE international conference on computervision. 2015: 1026-1034. 该论文作者对比了PReLU和ReLU在ImageNet model A的训练效果。
(6) RReLU
RReLU的英文全称是“Randomized Leaky ReLU”,中文名字叫“随机修正线性单元”。RReLU是Leaky ReLU的随机版本。它首次是在Kaggle的NDSB比赛中被提出来的。
图13:Randomized Leaky ReLU函数图像
RReLU的核心思想是,在训练过程中,α是从一个高斯分布中随机出来的值,然后再在测试过程中进行修正。数学表达式如10式所示。
在测试阶段,把训练过程中所有的取个平均值。NDSB冠军的α是从中随机出来的。那么在测试阶段,激活函数就是公式11。
特点:
1.RReLU是Leaky ReLU的random版本,在训练过程中,α是从一个高斯分布中随机出来的,然后再测试过程中进行修正。
2.数学形式与PReLU类似,但RReLU是一种非确定性激活函数,其参数是随机的。
(7)ReLU、Leaky ReLU、PReLU和RReLU的比较
图14:ReLU、Leaky ReLU、PReLU、RReLU函数图像
PReLU中的α是根据数据变化的;
Leaky ReLU中的α是固定的;
RReLU中的α是一个在给定范围内随机抽取的值,这个值在测试环节就会固定下来。
扩展材料:
Xu B, Wang N, Chen T, et al. Empiricalevaluation of rectified activations in convolutional network[J]. arXiv preprintarXiv:1505.00853, 2015. 在这篇论文中作者对比了ReLU、LReLU、PReLU、RReLU在CIFAR-10、CIFAR-100、NDSB数据集中的效果。
(8)ELU
ELU的英文全称是“Exponential Linear Units”,中文全称是“指数线性单元”。它试图将激活函数的输出平均值接近零,从而加快学习速度。同时,它还能通过正值的标识来避免梯度消失的问题。根据一些研究显示,ELU分类精确度是高于ReLU的。公式如12式所示。
图15:ELU与其他几种激活函数的比较图
优点:
ELU包含了ReLU的所有优点。
神经元不会出现死亡的情况。
ELU激活函数的输出均值是接近于零的。
缺点:
计算的时候是需要计算指数的,计算效率低的问题。
扩展材料:
Clevert D A, Unterthiner T, Hochreiter S. Fastand accurate deep network learning by exponential linear units (elus)[J]. arXivpreprint arXiv:1511.07289, 2015. 这篇论文提出了ELU函数。
(9)Maxout
Maxout “Neuron” 是由Goodfellow等人在2013年提出的一种很有特点的神经元,它的激活函数、计算的变量、计算方式和普通的神经元完全不同,并有两组权重。先得到两个超平面,再进行最大值计算。激活函数是对ReLU和Leaky ReLU的一般化归纳,没有ReLU函数的缺点,不会出现激活函数饱和神经元死亡的情况。Maxout出现在ICML2013上,作者Goodfellow将maxout和dropout结合,称在MNIST,CIFAR-10,CIFAR-100,SVHN这4个数据集上都取得了start-of-art的识别率。Maxout公式如13所示。
其中,假设w是2维的,那么我们可以得出公式14。
分析公式14可以注意到,ReLU和Leaky ReLU都是它的一个变形。比如的时候,就是ReLU。Maxout的拟合能力非常强,它可以拟合任意的凸函数。Goodfellow在论文中从数学的角度上也证明了这个结论,只需要2个Maxout节点就可以拟合任意的凸函数,前提是“隐含层”节点的个数足够多。
优点:
Maxout具有ReLU的所有优点,线性、不饱和性。
同时没有ReLU的一些缺点。如:神经元的死亡。
缺点:
从这个激活函数的公式14中可以看出,每个neuron将有两组w,那么参数就增加了一倍。这就导致了整体参数的数量激增。
扩展材料:
Goodfellow I J, Warde-Farley D, Mirza M, et al.Maxout networks[J]. arXiv preprint arXiv:1302.4389, 2013. Goodfellow的这篇论文提出了Maxout,感兴趣可以了解一下。
总结:怎么选择激活函数?
关于激活函数的选取,目前还不存在定论,在实践过程中更多还是需要结合实际情况,考虑不同激活函数的优缺点综合使用。我在这里给大家一点在训练模型时候的建议。
1.通常来说,不会把各种激活函数串起来在一个网络中使用。
2.如果使用ReLU,那么一定要小心设置学习率(learning rate),并且要注意不要让网络中出现很多死亡神经元。如果死亡神经元过多的问题不好解决,可以试试Leaky ReLU、PReLU、或者Maxout。
3.尽量不要使用sigmoid激活函数,可以试试tanh,不过个人感觉tanh的效果会比不上ReLU和Maxout。
Reference:
1.Andrew L. Maas, Awni Y. Hannum and Andrew Y. Ng. Rectified NonlinearitiesImprove Neural Network Acoustic Models (PDF). ICML.2013. 该论文提出了Leaky ReLU函数。
2.He K, Zhang X, Ren S, et al. Delving deepinto rectifiers: Surpassing human-level performance on imagenetclassification[C]//Proceedings of the IEEE international conference on computervision. 2015: 1026-1034. 该论文介绍了用Leaky ReLU函数的好处。
3.He K, Zhang X, Ren S, et al. Delving deepinto rectifiers: Surpassing human-level performance on imagenetclassification[C]//Proceedings of the IEEE international conference on computervision. 2015: 1026-1034. 该论文作者对比了PReLU和ReLU在ImageNet model A的训练效果。
4.Xu B, Wang N, Chen T, et al. Empiricalevaluation of rectified activations in convolutional network[J]. arXiv preprintarXiv:1505.00853, 2015. 在这篇论文中作者对比了ReLU、LReLU、PReLU、RReLU在CIFAR-10、CIFAR-100、NDSB数据集中的效果。
5.Clevert D A, Unterthiner T, Hochreiter S. Fastand accurate deep network learning by exponential linear units (elus)[J]. arXivpreprint arXiv:1511.07289, 2015. 这篇论文提出了ELU函数。
6.Goodfellow I J, Warde-Farley D, Mirza M, et al.Maxout networks[J]. arXiv preprint arXiv:1302.4389, 2013. Goodfellow的这篇论文提出了Maxout,感兴趣可以了解一下。
返回列表
batch size选多少合适? |