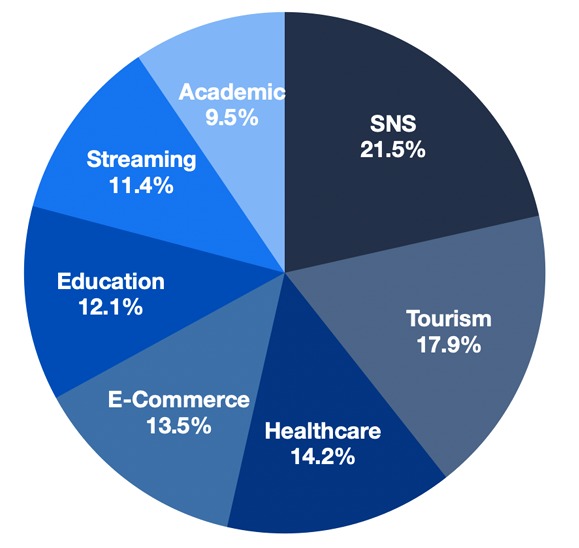
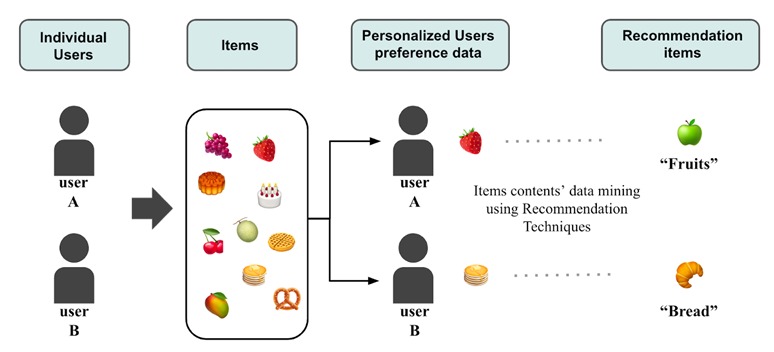
这篇教程推荐系统基础Fundamentals of Recommendation Systems写得很实用,希望能帮到您。 在本课程中,我们将探索推荐系统的迷人世界。我们将从学习这些系统的基本知识开始,然后详细研究一些最流行的系统。 随着互联网的兴起和智能设备的日益使用,了解用户偏好并提供个性化内容和服务变得比以往任何时候都更重要。网络应用程序可以通过提供个性化服务来保持用户的参与度,这是由推荐引擎实现的。 这些引擎利用用户数据(例如,关注者、推特、图片、喜欢和不喜欢、评级等)来提供个性化推荐。了解用户的品味对于成功推荐商品至关重要,而各种技术(例如,机器学习、统计学、概率和代数)都被用来实现这一点。 推荐系统已经成为许多服务和网络应用程序不可或缺的一部分(图1),包括Netflix、亚马逊、领英和YouTube。每项服务都使用独特的技术和算法来分析用户数据,并提供建议,让我们不断获得更多信息。 Figure 1: Distribution of applications of recommendation systems (source: Ko et al., 2022). 本课旨在让读者全面了解如何使用各种工具(如机器学习、统计学、概率和代数)来推荐我们流行的日常应用程序。在课程结束时,读者将牢牢掌握使这些应用程序能够根据数据分析提出建议的基本原理。
Figure 2: Recommendation System (source: Accenture).
基于内容的推荐
基于内容的推荐(图3)依赖于根据特定用户对类似项目的偏好来估计项目对特定用户的效用函数。这使得系统能够建议符合用户兴趣的项目,从而更容易发现他们喜欢的新内容。 关于推荐系统,可能的项目的空间可能相当大,在某些情况下有数十万甚至数百万个项目。效用函数通常表示预测用户喜欢某个特定项目的可能性的评级。例如,如果用户喜欢动作惊悚片,如果推荐的话,他可能会喜欢汤姆·克鲁斯的电影。 每个用户都有一个具有各种特征的个人资料(例如,年龄、婚姻状况、观看历史、最近的查询、评级等)。同样,一个项目(例如电影)可以用类型、年份、导演、演员阵容、IMDB评级等特征来表示。效用函数测量用户个人资料和项目特征之间的相似性。 创建推荐系统的最大挑战是效用函数,它需要为所有用户项目组合定义。此外,用户和项目空间也在不断增长和变化。这就是机器学习、统计学和代数发挥作用的地方。通过分析用户过去如何与物品互动,我们可以使用算法来近似效用函数,并做出用户会喜欢的个性化推荐。 Figure 3: Content-based recommendation system (source: Ko et al., 2022). 例如,如果用户喜欢恐怖电影(例如《招魂记》或《修女》),基于内容的推荐系统会推荐其他恐怖电影(如《安娜贝尔》)。最终,该系统旨在找到符合用户偏好和兴趣的项目,为他们提供个性化推荐。 计算项目c对用户u的效用的最著名的度量之一是余弦相似度。为了理解这一点假设每个项c可以表示为特征向量,
where represents the weight of the feature (e.g., Whether the movie is a horror or not? Does the film have Tom Cruise as a leading actor?). Note that the weights can be binary or continuous depending on the nature of the feature.
Given these item feature vectors, the user profile vector can be computed as the average of feature vectors of items (total items) liked or rated by that user in the past. In other words,
Once we have the user profile vector, we can use cosine similarity to compute the similarity between the user profile and a new item . This can be done using the following equation:
where denotes the dot product operation and denotes the norm of a vector.
It is important to consider certain limitations when utilizing content-based recommendations. 由于关于新用户兴趣的信息有限,新用户可能会发现建立用户简档向量很困难。这可能会导致提出意义不大的建议。
此外,基于内容的推荐可能与用户已经参与的项目过于相似,导致过度专业化和对新兴趣的探索有限。
合作推荐 与基于内容的推荐不同,协作系统(图4)旨在根据其他用户提供的评分来预测项目对用户的有用性。这意味着系统可以建议与给定用户具有相似兴趣的用户喜欢或评价很高的项目。例如,如果两个用户,迈克和约翰,都喜欢恐怖电影,而迈克喜欢《招魂记》。那么,协作系统也会向约翰推荐《招魂》。 Figure 4: Collaborative recommendation system (source: KDnuggets).
To predict the utility of an un-rated item for a user , we define a set consisting of users that are most similar to user and have already rated the item . We can find these -closest users by measuring the cosine similarity between them and the given user .
The utility can thus be estimated as the average of utilities as follows:
Here, we have chosen a simple function-like average to aggregate the utilities . In general, the aggregator can be any function. 与基于内容的推荐一样,协作系统也有其局限性:
Hybrid systems are becoming increasingly popular in recommendation engines as they offer the benefits of both content-based and collaborative methods while avoiding some of their limitations. There are different ways to combine both of these methods, which can be classified as follows:
Ensembling the predictions of both content-based and collaborative systems (e.g., a linear combination of ratings and a voting scheme)
Incorporating content-based characteristics into a collaborative approach and vice-versa (e.g., collaborative systems can also maintain content-based profiles for each user, which can be used to provide recommendations for uncommonly rated items)
A unified recommendation system that incorporates both content and collaborative aspects of the recommendation
Establishing the qualities that make a recommendation system great is crucial when assessing its effectiveness. In addition, various metrics can be employed to evaluate a recommendation system, and it’s essential to delve into these metrics and understand how they can be used for evaluation purposes.
Root mean square error (RMSE) is one of the simplest ways to evaluate a recommendation engine. RMSE measures how good the predicted utility of an item for user is compared to the user’s actual ratings. Mathematically,
where is the rating given by user to item and is the set of users and items for which we already have the ratings.
Precision measures the efficiency of a machine learning algorithm. For a recommendation system, Precision@K measures the fraction of top- recommendations which are actually relevant to the user. Relevant recommendations are those the user will probably like the recommended item.
Suppose, the recommendation system recommends top- items to a user based on their utilities. And assume that the set represents the top- items that are actually relevant for the user (i.e., ground-truth recommendations). The Precision@K is then defined as
Recall measures the effectiveness of a machine learning system. For a recommendation system, Recall@K measures the fraction of relevant items covered in the top- recommendations.
Suppose, the recommendation system recommends top- items to a user based on their utilities. And assume that the set represents the top- items that are actually relevant for the user (i.e., ground-truth recommendations). Recall@K is then defined as
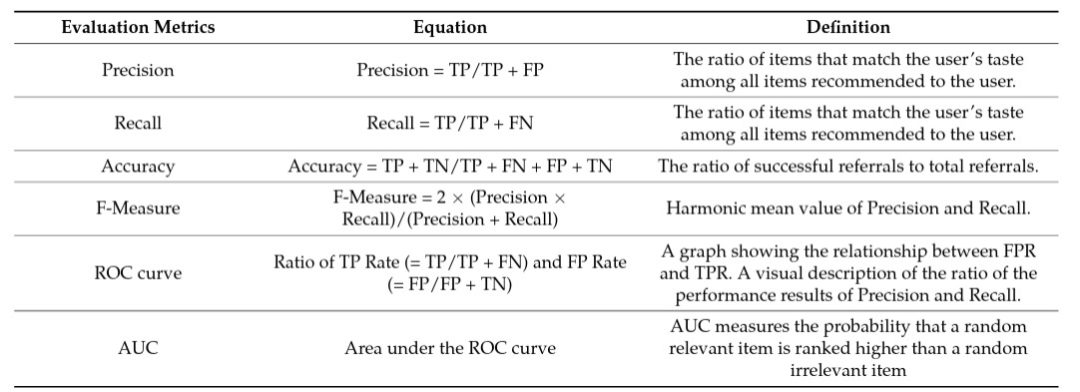
We can define several other metrics based on precision-recall (e.g., F-score, ROC (receiver operator characteristic) curve, AUC (area under the curve), etc.). This is described in Table 1.
Table 1: Summary of various evaluation metrics for recommendation systems (source: Ko et al., 2022).
Suppose the item is the topmost relevant item in the ground-truth recommendations and ranks in the top- recommendations provided by the recommendation engine. Then, the mean reciprocal rank (MRR) is defined as the “multiplicative inverse” of the rank of the most relevant item :
where is the number of users for which we have provided recommendations.
Data mining techniques are incredibly valuable for uncovering patterns and correlations within data. This information can then be used to make recommendations (e.g., suggesting similar items or grouping users with similar interests). Figure 5 provides an overview of the various data mining techniques commonly used in recommendation engines today, and we’ll delve into each of these techniques in more detail.
Figure 5: Overview of recommendation techniques (source: Ko et al. 2022).
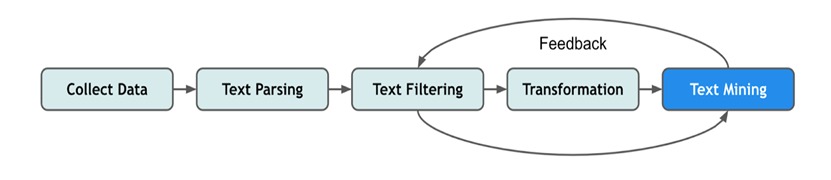
Text mining (Figure 6) is a powerful tool for extracting valuable information from textual data. This can be especially useful when recommending blogs, news articles, and other text-based content. For example, with a content-based recommendation system, text mining can help to identify and recommend similar items by analyzing the underlying semantic structure of each piece. Similarly, for collaborative recommendation models, text mining can help to evaluate the semantic knowledge of information data between users, enabling the system to make more accurate item recommendations based on similarity.
Figure 6: Illustration of how text mining works (source: Ko et al., 2022).
For example, term frequency–inverse document frequency (TF-IDF) (Figure 7) is a popular text-mining technique in content-based recommendations. The TF-IDF algorithm assigns weight to different keywords in a text according to the number of repetitions and the whole corpus. It comprises the following:
Term frequency (TF) assigns weight proportional to the times a keyword occurs in a text. In other words, more repetitions mean that the keyword is essential in the given text.
Inverse document frequency (IDF) assigns weight inversely proportional to the times the keyword occurs in the whole corpus. It is less important if a keyword is present in most of the text corpus.
This technique expresses a text item as a feature vector, which can be used to compute cosine similarity with other item feature vectors.
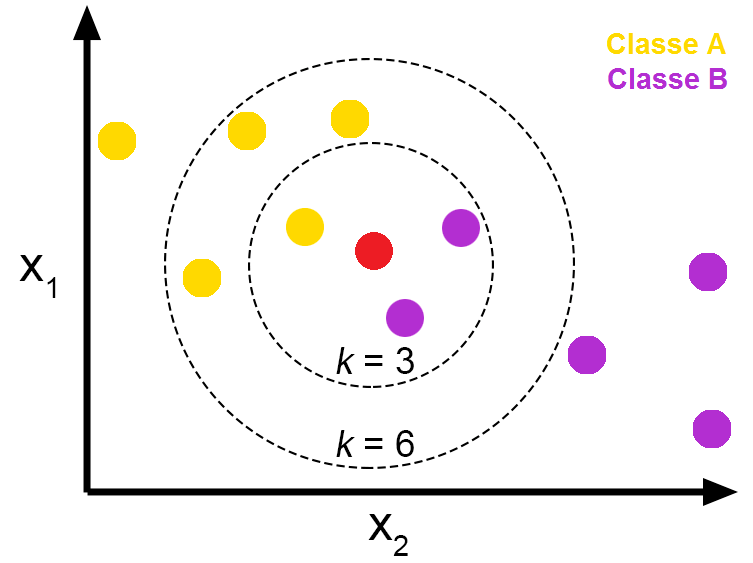
K-nearest neighbor (KNN) (Figure 8) is an algorithm that can be used to find the closest points for a data point based on a distance measure (e.g., Euclidean distance, cosine similarity, or Pearson correlation). In a collaborative recommendation model, the KNN algorithm can identify the -closest users to a given user. The item ratings of these -closest neighbors are then used to recommend items to the given user. For a content-based recommendation, the algorithm can find -similar items for a particular item previously rated by the user.
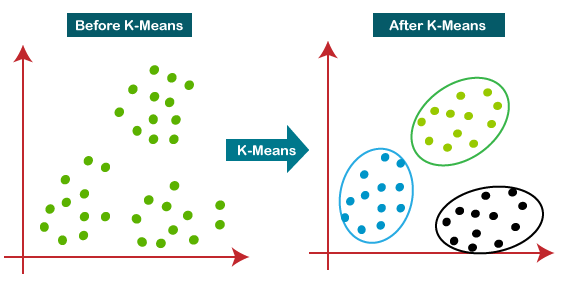
Clustering is a class of algorithms that segregates the data into a set of definite clusters such that similar points lie in the same cluster and dissimilar points lie in different clusters. Several clustering algorithms (e.g., -means and spectral clustering) can be used in recommendation engines.
For example, -means (Figure 9) works by first selecting random points as cluster centers. Then, it assigns each data point in the data to the nearest cluster center. After that, it calculates the mean of all data points assigned to each cluster and moves the cluster center to that mean. This process is repeated until the cluster centers no longer move.
Clustering is mainly used in collaborative settings to segregate users into similar interest groups. This way, the recommendation problem boils down to finding relevant items for a cluster rather than for each user separately.
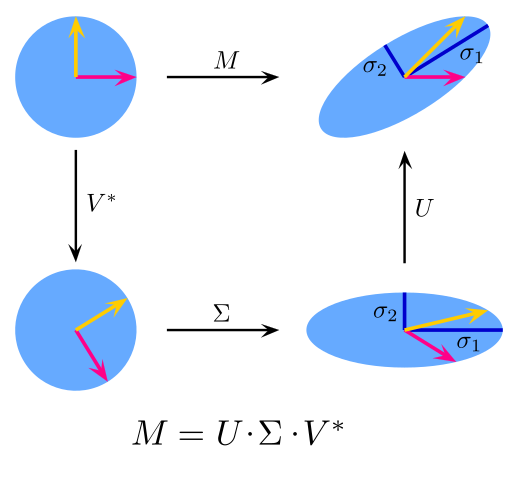
Matrix factorization is a technique used to find the transformation that expresses the user information and preference into the same latent space by decomposing the user’s evaluation data stored in a rating matrix. Singular value decomposition (SVD) is a popular matrix factorization method that transforms the user and selected items into a space of the same latent factor.
To understand this, assume a rating matrix (of size ) whose entry is
1 if user rated the item and 0 if it is unrated. Now, given this user-item matrix , the SVD (Figure 10) decomposes that matrix so that you have a user matrix and an item matrix independently. In other words,
where is a user matrix of size , is a diagonal matrix consisting of singular values along the principal diagonal, and is the item matrix of size . This way, the SVD decomposes the original matrix into a user and an item matrix that transforms the user and items into the same latent factor of dimension . Note that in Figure 10, .
Figure 10: Singular value decomposition (SVD) (source: Wikipedia).
SVD is popularly used in recommendation engines to find similar items and users via their respective user and item matrices.
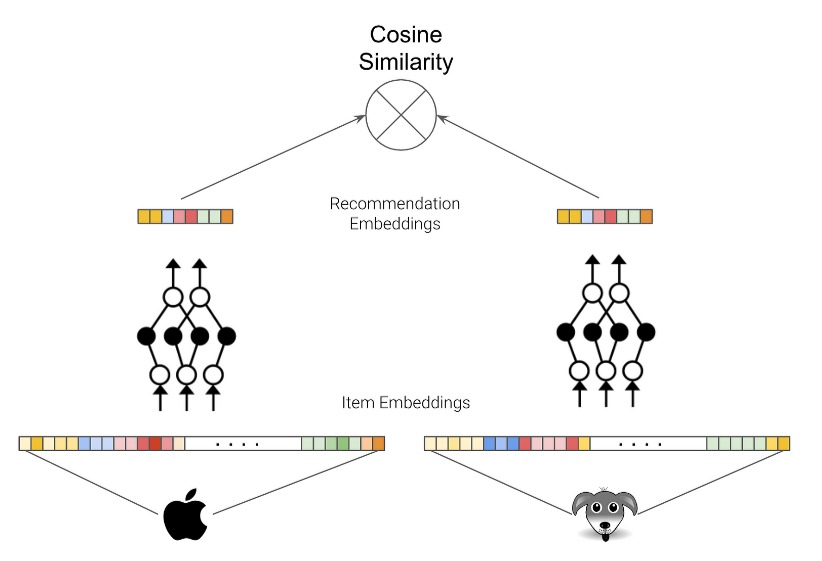
Neural networks have become increasingly popular in recommendation engines due to their ability to capture complex patterns in user-item data. They can now process various data (e.g., speech, text, images, tables, and graphs), making them suitable for various recommendation settings.
Deep neural networks (Figure 11) are used to learn user and item embeddings, which are vectors representing entity features. These embeddings help ensure that similar entities (e.g., users or items) have similar distances in the vector space. Neural networks can also be trained on multiple objectives simultaneously, making them a highly effective data mining technique.
Figure 11: Neural networks in recommendation engines (source: Towards Data Science).
An active area of research in recommendation systems is a bandit-based algorithm, a form of reinforcement learning that tries to balance exploring and exploiting possibilities. These algorithms can consider multiple objectives and metrics related to user satisfaction. For example, an additional objective in a music recommender system can be to provide “fairness” for new and long-tailed artists.
Graph neural networks (GNNs) are another area of active research, as they can extract information from graphs that capture the interactions between customers and items. GNNs have an advantage over sequence-based neural nets as there is no necessarily fixed order of items a user might like.
 ,
, ,")
") 是衡量项目c对用户u的有用性的效用函数。.
是衡量项目c对用户u的有用性的效用函数。.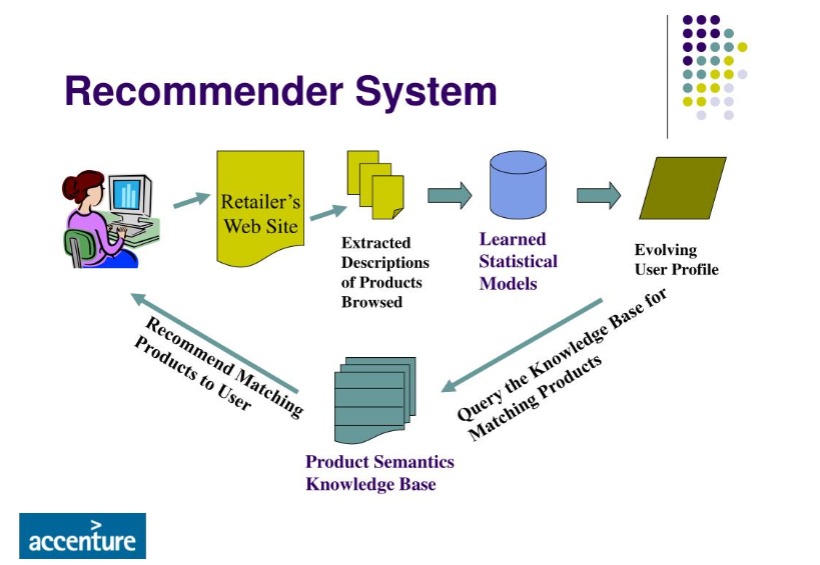
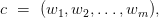
 represents the weight of the
represents the weight of the  feature (e.g., Whether the movie is a horror or not? Does the film have Tom Cruise as a leading actor?). Note that the weights
feature (e.g., Whether the movie is a horror or not? Does the film have Tom Cruise as a leading actor?). Note that the weights  can be computed as the average of feature vectors of items
can be computed as the average of feature vectors of items  (total
(total  items) liked or rated by that user in the past. In other words,
items) liked or rated by that user in the past. In other words,
 . This can be done using the following equation:
. This can be done using the following equation: \ = \ \displaystyle\frac{\langle c_j, u \rangle}{\Vert c_j \Vert \cdot \Vert u \Vert},")
 denotes the dot product operation and
denotes the dot product operation and  denotes the norm of a vector.
denotes the norm of a vector.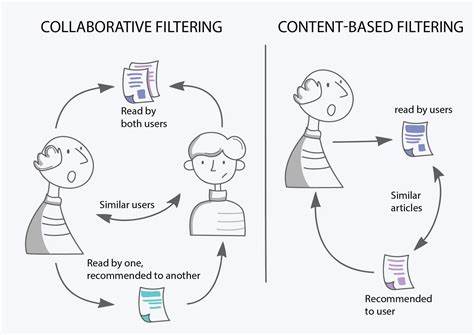
 for a user
for a user  consisting of
consisting of  users that are most similar to user
users that are most similar to user ")
") as follows:
as follows: \ = \ \displaystyle\frac{\sum\limits_{i=1}^{K} f(c, u_i)}{K}.")
 \in R} (f(c, u) - r_{cu})^2}{\vert R \vert}},")
 is the rating given by user
is the rating given by user  is the set of users and items for which we already have the ratings.
is the set of users and items for which we already have the ratings. to a user
to a user  represents the top-
represents the top-
 to a user
to a user 
 in the top-
in the top-
 is the number of users for which we have provided recommendations.
is the number of users for which we have provided recommendations.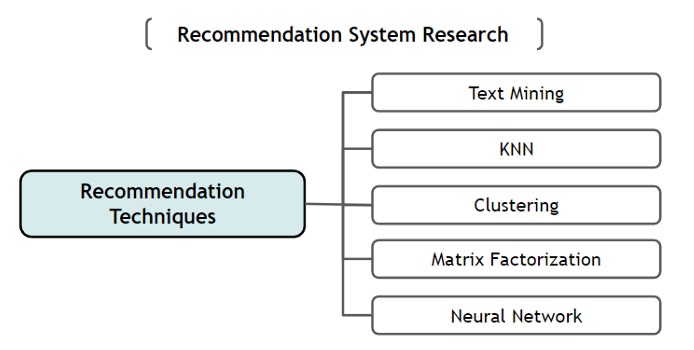

 (of size
(of size  ) whose
) whose  entry
entry ") is
is  rated the item
rated the item  and
and 
 is a user matrix of size
is a user matrix of size  ,
,  is a
is a  diagonal matrix consisting of singular values along the principal diagonal, and
diagonal matrix consisting of singular values along the principal diagonal, and  is the item matrix of size
is the item matrix of size  . This way, the SVD decomposes the original matrix
. This way, the SVD decomposes the original matrix  .
.