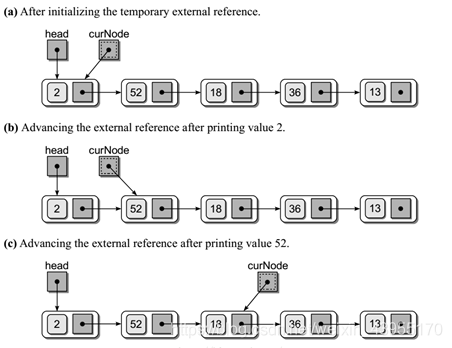
# 节点定义:class Node( object ): def __init__( self ,item): self .item = item # 数据域 self . next = None # 指针域 n1 = Node( 1 )n2 = Node( 2 )n3 = Node( 3 ) n1. next = n2n2. next = n3# 通过 n1 找到n3的值print (n1. next . next .item)
只保留头结点,执行第一个位置,剩下的都是next去指定。
2、链表遍历:(头节点的变动)
# 节点定义:class Node( object ): def __init__( self ,item): self .item = item # 数据域 self . next = None # 指针域 n1 = Node( 1 )n2 = Node( 2 )n3 = Node( 3 ) n1. next = n2n2. next = n3# 通过 n1 找到n3的值print (n1. next . next .item)
3、链表节点的插入和删除操作(非常方便,时间复杂度低)
插入:
p = Node( 5 ) # 要插入的值curNode = Node( 1 ) # 标志位# 顺序不能乱,否则就找不到原链表中的下一个值p. next = curNode. next # 指定插入值之后的值为标志位之后的值curNode. next = p # 然后再把原先的链next指向改成插入的值
删除:
curNode 代表当前值p = curNode. next # 表示要删除的数curNode. next = p. next # 重新指定建立链表del p 删除数
4、建立链表(单链表)
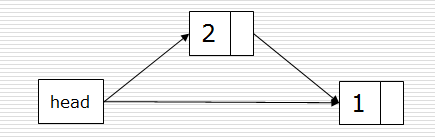
1)头插法:是在head头节点的位置后插入数;得到的链表与原先的列表顺序是相反的。
def createLinkListF(li): l = Node() # 始终指向头节点 for num in li: s = Node(num) s. next = l. next l. next = s return l
2)尾插法:在链表的尾巴上插入。相当于是追加,必须时刻记住尾巴在哪儿
def createLinkListR(li): l = Node() r = l # r指向尾节点 for num in li: s = Node(num): r. next = s r = s # 重新指定尾节点
p = Node( 2 ) # 要插入的数p. next = curNode. next # 指定插入数的next 是 当前数的nextcurNode. next .prior = p # 指定插入数的下一个数的 前置数为当前的数值p.prior = curNode # 插入数的前置数为 标志位curNode. next = p # 指定,标志位的next数是当前要插入的数
2)删除:
p = curNode. next # 标志位的下一个数,要删除的数curNode. next = p. next # 将next指向下一个数p. next .prior = curNode # 将要删除数的下一个数的前置数改为标志位del p # 删除当前数
3、建立双链表
尾插法:def createLinkListR(li): l = Node() r = l for num in li: s = Node(num) r. next = s s.prior = r r = s return l,r
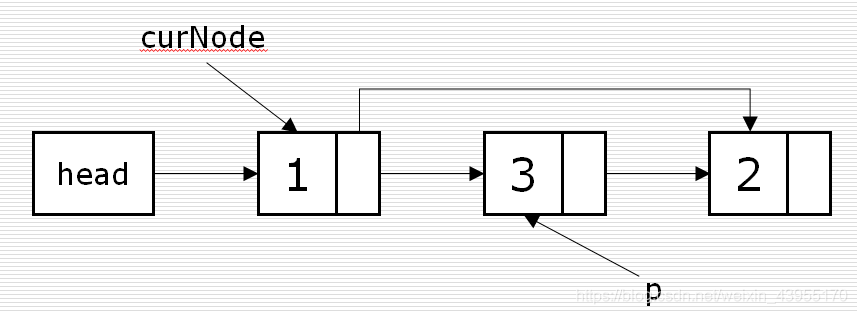
# 创建节点 class Node( object ): def __init__( self ,item = None , next = None ): self .item = item # 数据域 self . next = next # 指针域 # 循环逆置方法def revLinkList(link): if link is None or link. next is None : return link pre = link # 记录当前节点的值 cur = link. next # 记录下一节点的值 pre. next = None # 先将当前节点的next指向定为None while cur: # 链表中一直有值 tmp = cur. next # 获取cur的下一个值,临时赋值给tmp cur. next = pre # 将cur值指向pre pre = cur # 重新指定 cur = tmp return pre # 把当前值返回 #应用link = Node( 1 , Node( 2 , Node( 3 , Node( 4 , Node( 5 , Node( 6 , Node( 7 , Node( 8 , Node( 9 )))))))))r = revLinkList(link): # 链表逆置之后,得到的head值while r: print ( "{0}---->" . format (r.item)) # 输出逆置后的当前值 r = r. next # 获取下一个,重新赋给r,然后交给上边输出
列表的实现机制
Python 标准类型 list 就是一种元素个数可变的线性表,可以加入和删除元素,并在各种操作中维持已有元素的顺序(即保序),而且还具有以下行为特征:
基于下标(位置)的高效元素访问和更新,时间复杂度应该是O(1);为满足该特征,应该采用顺序表技术,表中元素保存在一块连续的存储区中。允许任意加入元素,而且在不断加入元素的过程中,表对象的标识(函数id得到的值)不变。为满足该特征,就必须能更换元素存储区,并且为保证更换存储区时 list 对象的标识 id 不变,只能采用分离式实现技术。
列表的实现是基于数组或者基于链表结构,当使用列表迭代器的时候,双向链表结构比单链表结构更快。 Python 中的列表英文名是 list,因此很容易与 C 语言中的链表搞混了,因为在 C 语言中大家经常给链表命名为 list。事实上 CPython,也是我们常见的用 C 语言开发的 Python 解释器,Python 语言底层是 C 语言实现的)中的列表根本不是列表。在 CPython 中列表被实现为长度可变的数组。