这篇教程Python爬虫分析汇总写得很实用,希望能帮到您。
Python爬虫分析前言:
计算机行业的发展太快了,有时候几天不学习,就被时代所抛弃了,因此对于我们程序员而言,最重要的就是要时刻紧跟业界动态变化,学习新的技术,但是很多时候我们又不知道学什么好,万一学的新技术并不会被广泛使用,太小众了对学习工作也帮助不大,这时候我们就想要知道大佬们都在学什么了,跟着大佬学习走弯路的概率就小很多了。现在就让我们看看C站大佬们平时都收藏了什么,大佬学什么跟着大佬的脚步就好了!
一、程序说明通过爬取 “CSDN” 获取全站排名靠前的博主的公开收藏夹,写入 csv 文件中,根据所获取数据分析领域大佬们的学习趋势,并通过可视化的方式进行展示。
二、数据爬取使用 requests 库请求网页信息,使用 BeautifulSoup4 和 json 库解析网页。
1、获取 CSDN 作者总榜数据首先,我们需要获取 CSDN 中在榜的大佬,获取他/她们的相关信息。由于数据是动态加载的 (因此使用开发者工具,在网络选项卡中可以找到请求的 JSON 数据: 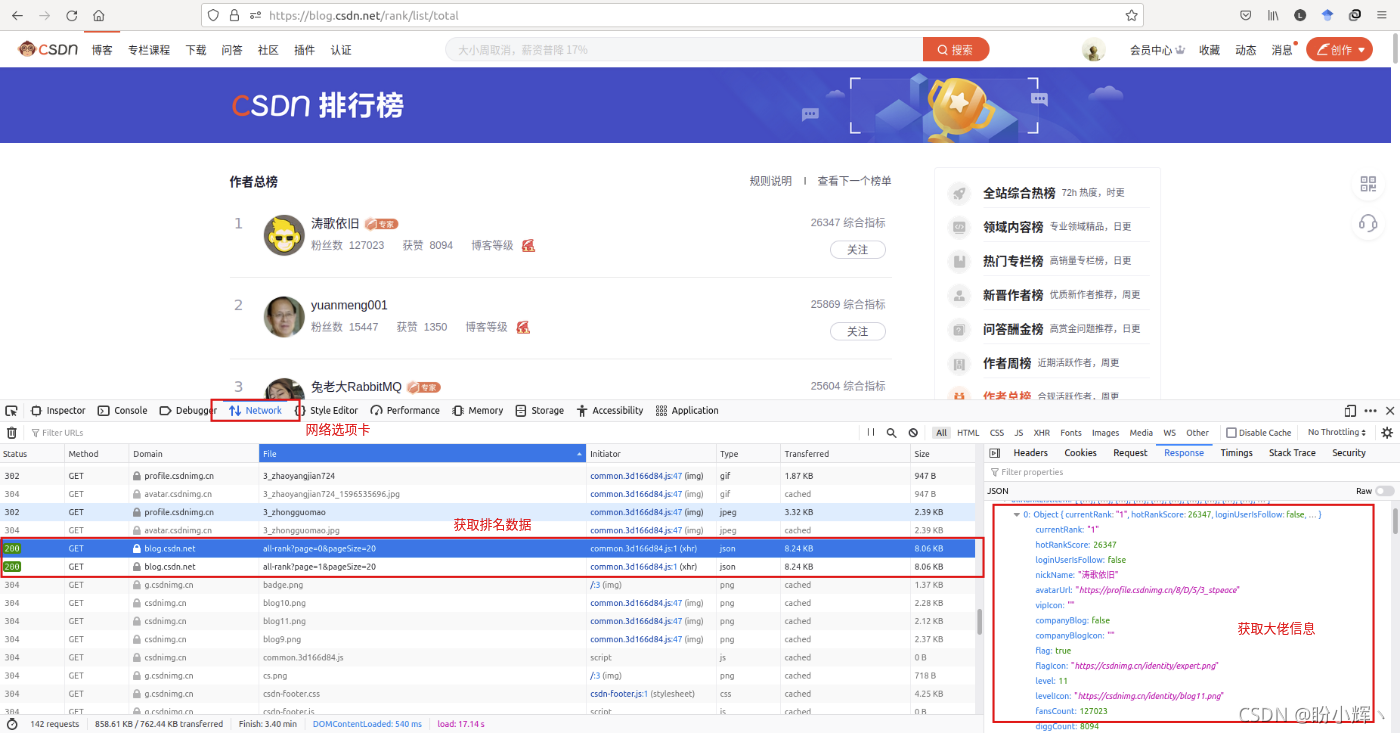
观察请求链接: https://blog.csdn.net/phoenix/web/blog/all-rank?page=0&pageSize=20https://blog.csdn.net/phoenix/web/blog/all-rank?page=1&pageSize=20... 可以发现每次请求 JSON 数据时,会获取20个数据,为了获取排名前100的大佬数据,使用如下方式构造请求: url_rank_pattern = "https://blog.csdn.net/phoenix/web/blog/all-rank?page={}&pageSize=20"for i in range(5): url = url_rank_pattern.format(i) #声明网页编码方式 response = requests.get(url=url, headers=headers) response.encoding = 'utf-8' response.raise_for_status() soup = BeautifulSoup(response.text, 'html.parser')请求得到 Json 数据后,使用 json 模块解析数据(当然也可以使用 re 模块,根据自己的喜好选择就好了),获取用户信息,从需求上讲,这里仅需要用户 userName,因此仅解析 userName 信息,也可以根据需求获取其他信息: userNames = []information = json.loads(str(soup))for j in information['data']['allRankListItem']: # 获取id信息 userNames.append(j['userName'])
2、获取收藏夹列表获取到大佬的 userName 信息后,通过主页来观察收藏夹列表的请求方式,本文以自己的主页为例(给自己推广一波),分析方法与上一步类似,在主页中切换到“收藏”选项卡,同样利用开发者工具的网络选项卡:

观察请求收藏夹列表的地址: https://blog.csdn.net/community/home-api/v1/get-favorites-created-list?page=1&size=20&noMore=false&blogUsername=LOVEmy134611 可以看到这里我们上一步获取的 userName 就用上了,可以通过替换 blogUsername 的值来获取列表中大佬的收藏夹列表,同样当收藏夹数量大于20时,可以通过修改 page 值来获取所有收藏夹列表: collections = "https://blog.csdn.net/community/home-api/v1/get-favorites-created-list?page=1&size=20&noMore=false&blogUsername={}"for userName in userNames: url = collections.format(userName) #声明网页编码方式 response = requests.get(url=url, headers=headers) response.encoding = 'utf-8' response.raise_for_status() soup = BeautifulSoup(response.text, 'html.parser')请求得到 Json 数据后,使用 json 模块解析数据,获取收藏夹信息,从需求上讲,这里仅需要收藏夹 id,因此仅解析 id 信息,也可以根据需求获取其他信息(例如可以获取关注人数等信息,找到最受欢迎的收藏夹): file_id_list = []information = json.loads(str(soup))# 获取收藏夹总数collection_number = information['data']['total']# 获取收藏夹idfor j in information['data']['list']: file_id_list.append(j['id']) 这里大家可能会问,现在 CSDN 不是有新旧两种主页么,请求方式能一样么?答案是:不一样,在浏览器端进行访问时,旧版本使用了不同的请求接口,但是我们同样可以使用新版本的请求方式来进行获取,因此就不必区分新、旧版本的请求接口了,获取收藏数据时情况也是一样的。
3、获取收藏数据最后,单击收藏夹展开按钮,就可以看到收藏夹中的内容了,然后同样利用开发者工具的网络选项卡进行分析: 
观察请求收藏夹的地址: https://blog.csdn.net/community/home-api/v1/get-favorites-item-list?blogUsername=LOVEmy134611&folderId=9406232&page=1&pageSize=200 可以看到刚刚获取的用户 userName 和收藏夹 id 就可以构造请求获取收藏夹中的收藏信息了: file_url = "https://blog.csdn.net/community/home-api/v1/get-favorites-item-list?blogUsername={}&folderId={}&page=1&pageSize=200"for file_id in file_id_list: url = file_url.format(userName,file_id) #声明网页编码方式 response = requests.get(url=url, headers=headers) response.encoding = 'utf-8' response.raise_for_status() soup = BeautifulSoup(response.text, 'html.parser')最后用 re 模块解析: user = user_dict[userName] user = preprocess(user) # 标题 title_list = analysis(r'"title":"(.*?)",', str(soup)) # 链接 url_list = analysis(r'"url":"(.*?)"', str(soup)) # 作者 nickname_list = analysis(r'"nickname":"(.*?)",', str(soup)) # 收藏日期 date_list = analysis(r'"dateTime":"(.*?)",', str(soup)) for i in range(len(title_list)): title = preprocess(title_list[i]) url = preprocess(url_list[i]) nickname = preprocess(nickname_list[i]) date = preprocess(date_list[i])
4、爬虫程序完整代码import timeimport requestsfrom bs4 import BeautifulSoupimport osimport jsonimport reimport csvif not os.path.exists("col_infor.csv"): #创建存储csv文件存储数据 file = open('col_infor.csv', "w", encoding="utf-8-sig",newline='') csv_head = csv.writer(file) #表头 header = ['userName','title','url','anthor','date'] csv_head.writerow(header) file.close()headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}def preprocess(string): return string.replace(',',' ')url_rank_pattern = "https://blog.csdn.net/phoenix/web/blog/all-rank?page={}&pageSize=20"userNames = []user_dict = {}for i in range(5): url = url_rank_pattern.format(i) #声明网页编码方式 response = requests.get(url=url, headers=headers) response.encoding = 'utf-8' response.raise_for_status() soup = BeautifulSoup(response.text, 'html.parser') information = json.loads(str(soup)) for j in information['data']['allRankListItem']: # 获取id信息 userNames.append(j['userName']) user_dict[j['userName']] = j['nickName']def get_col_list(page,userName): collections = "https://blog.csdn.net/community/home-api/v1/get-favorites-created-list?page={}&size=20&noMore=false&blogUsername={}" url = collections.format(page,userName) #声明网页编码方式 response = requests.get(url=url, headers=headers) response.encoding = 'utf-8' response.raise_for_status() soup = BeautifulSoup(response.text, 'html.parser') information = json.loads(str(soup)) return informationdef analysis(item,results): pattern = re.compile(item, re.I|re.M) result_list = pattern.findall(results) return result_listdef get_col(userName, file_id, col_page): file_url = "https://blog.csdn.net/community/home-api/v1/get-favorites-item-list?blogUsername={}&folderId={}&page={}&pageSize=200" url = file_url.format(userName,file_id, col_page) #声明网页编码方式 response = requests.get(url=url, headers=headers) response.encoding = 'utf-8' response.raise_for_status() soup = BeautifulSoup(response.text, 'html.parser') user = user_dict[userName] user = preprocess(user) # 标题 title_list = analysis(r'"title":"(.*?)",', str(soup)) # 链接 url_list = analysis(r'"url":"(.*?)"', str(soup)) # 作者 nickname_list = analysis(r'"nickname":"(.*?)",', str(soup)) # 收藏日期 date_list = analysis(r'"dateTime":"(.*?)",', str(soup)) for i in range(len(title_list)): title = preprocess(title_list[i]) url = preprocess(url_list[i]) nickname = preprocess(nickname_list[i]) date = preprocess(date_list[i]) if title and url and nickname and date: with open('col_infor.csv', 'a+', encoding='utf-8-sig') as f: f.write(user + ',' + title + ',' + url + ',' + nickname + ',' + date + '/n') return informationfor userName in userNames: page = 1 file_id_list = [] information = get_col_list(page, userName) # 获取收藏夹总数 collection_number = information['data']['total'] # 获取收藏夹id for j in information['data']['list']: file_id_list.append(j['id']) while collection_number > 20: page = page + 1 collection_number = collection_number - 20 information = get_col_list(page, userName) # 获取收藏夹id for j in information['data']['list']: file_id_list.append(j['id']) collection_number = 0 # 获取收藏信息 for file_id in file_id_list: col_page = 1 information = get_col(userName, file_id, col_page) number_col = information['data']['total'] while number_col > 200: col_page = col_page + 1 number_col = number_col - 200 get_col(userName, file_id, col_page) number_col = 0
5、爬取数据结果展示部分爬取结果: 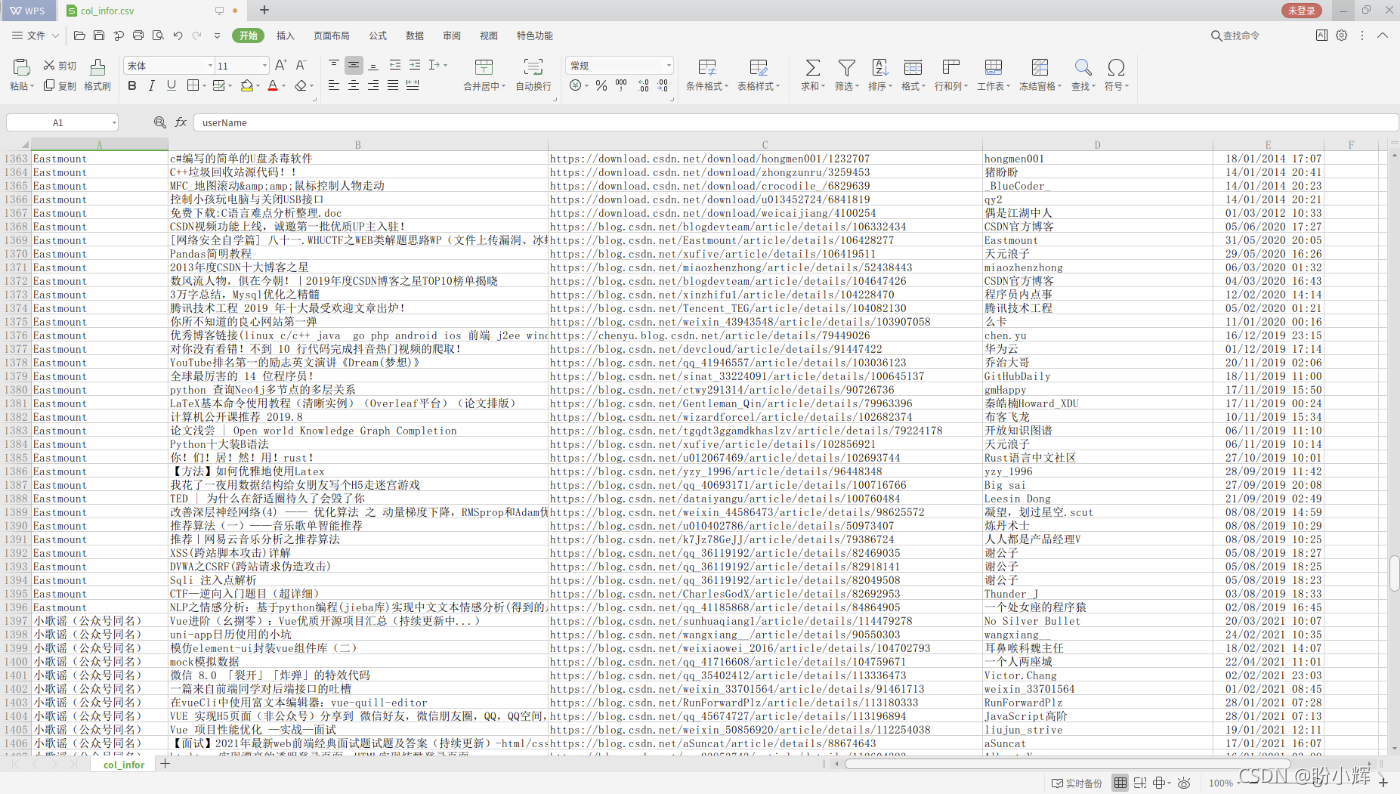
三、数据分析及可视化最后使用 wordcloud 库,绘制词云展示大佬收藏。
from os import pathfrom PIL import Imageimport matplotlib.pyplot as pltimport jiebafrom wordcloud import WordCloud, STOPWORDSimport pandas as pdimport matplotlib.ticker as tickerimport numpy as npimport mathimport redf = pd.read_csv('col_infor.csv', encoding='utf-8-sig',usecols=['userName','title','url','anthor','date'])place_array = df['title'].valuesplace_list = ','.join(place_array)with open('text.txt','a+') as f: f.writelines(place_list)###当前文件路径d = path.dirname(__file__)# Read the whole text.file = open(path.join(d, 'text.txt')).read()##进行分词#停用词stopwords = ["的","与","和","建议","收藏","使用","了","实现","我","中","你","在","之"]text_split = jieba.cut(file) # 未去掉停用词的分词结果 list类型#去掉停用词的分词结果 list类型text_split_no = []for word in text_split: if word not in stopwords: text_split_no.append(word)#print(text_split_no)text =' '.join(text_split_no)#背景图片picture_mask = np.array(Image.open(path.join(d, "path.jpg")))stopwords = set(STOPWORDS)stopwords.add("said")wc = WordCloud( #设置字体,指定字体路径 font_path=r'C:/Windows/Fonts/simsun.ttc', # font_path=r'/usr/share/fonts/wps-office/simsun.ttc', background_color="white", max_words=2000, mask=picture_mask, stopwords=stopwords) # 生成词云wc.generate(text)# 存储图片wc.to_file(path.join(d, "result.jpg"))到此这篇关于Python爬虫分析汇总的文章就介绍到这了,更多相关Python爬虫内容请搜索51zixue.net以前的文章或继续浏览下面的相关文章希望大家以后多多支持51zixue.net!
Python贪吃蛇小游戏实例分享
利用Python进行数据可视化的实例代码 |



