这篇教程python爬取网易云音乐排行榜实例代码写得很实用,希望能帮到您。
网易云音乐排行榜歌曲及评论爬取主要注意问题:selenium 模拟登录、iframe标签定位、页面元素提取。
在利用selenium定位元素并取值的过程中遇到问题。比如xpath正确但无法定位,在进行翻页提取评论的过程中,利用selenium似乎不能提取不同页的数据,比如,明明定位的第三页的评论数据,而只能返回第一页的评论数据。
一、模拟登录selenium 定位元素模拟人的操作进行登录,直接上代码: //模拟登录import pandas as pdfrom selenium import webdriverfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.chrome.options import Optionsfrom selenium.webdriver import ActionChainsfrom lxml import etreeimport timefrom datetime import datetime,timedeltawyy_url = 'https://music.163.com/'driver = webdriver.Chrome()driver.get(wyy_url)driver.maximize_window() #全屏time.sleep(2)driver.find_element_by_xpath("//a[@class = 'link s-fc3']").click()time.sleep(2)driver.find_element_by_xpath("//a[@class='u-btn2 other']").click() #选择其他方式登录#账号、密码登录driver.find_element_by_xpath("//input[@type='checkbox']").click() #同意条款time.sleep(0.5)driver.find_element_by_xpath("//a[@class='u-btn2 u-btn2-2']").click()#选择手机号密码登录driver.find_element_by_xpath("//a[@class='f-fr s-fc3 pwdlogin']").click()time.sleep(1)driver.find_element_by_id("p").send_keys('xxx') #这里输入你的iddriver.find_element_by_id("pw").send_keys('xxx') #这里输入密码time.sleep(1)#点击登录driver.find_element_by_xpath("//a[@class='j-primary u-btn2 u-btn2-2']").click()time.sleep(1)
二、排行榜数据爬取当时尝试直接用selenium定位标签取值,并没有返回有效结果。在后面爬取评论时,也遇到此问题。于是先获取页面内容在进行分析。 // 排行榜base_url = "https://music.163.com/#/discover/toplist?id="bang_typical = {'飙升榜':19723756,'新歌榜':3779629,'原创榜':2884035,'热歌榜':3778678}#选择榜单bang = input('请输入榜单:')#构造榜单对应的链接url = base_url + str(bang_typical[bang]) print('开始分析:-%s' %(bang))#进入榜单driver.get(url) time.sleep(3) #iframe标签定位,必要的,否则无法定位其他标签_iframe = driver.find_element_by_xpath("//iframe[@id='g_iframe']") # 找到iframe标签driver.switch_to.frame(_iframe)time.sleep(1)page_text = driver.execute_script("return document.documentElement.outerHTML")#获取页面html = etree.HTML(page_text) trs = html.xpath('//tbody/tr')rank_list = []title_list = []span_list = []singer_list = []for tr in trs: rank = tr.xpath(".//span[@class='num']/text()")[0] #注意xpath获取到的是列表,需提取其元素 title = tr.xpath(".//b/@title")[0] span = tr.xpath(".//td[@class=' s-fc3']/span[@class='u-dur ']/text()")[0] singer = tr.xpath(".//div[@class='text']/span/@title")[0] rank_list.append(rank) title_list.append(title) span_list.append(span) singer_list.append(singer)#输出榜单结果df_bang = pd.DataFrame({'排名':rank_list,'歌名':title_list,'时长':span_list,'歌手':singer_list})
三、排行榜评论获取主要是评论日期的格式转换,评论内容的清洗 // 评论# 日期清洗函数def change_time(time): now = datetime.now() day_y = datetime.strftime(now - timedelta(1),'%Y-%m-%d') #计算昨天 day = now.strftime('%Y-%m-%d') year = now.strftime('%Y') if '年' in time: #非今年 new_time = time.replace('年','-').replace('月','-').replace('日','') elif '昨天' in time: new_time = time.replace('昨天',day_y+' ') elif '前' in time: #前天 minut = int(time[:time.index('分')]) new_time = (now + timedelta(minutes=-minut)).strftime('%Y-%m-%d %H:%M') elif len(time) == 5: #今天 new_time = day + ' ' + time else: #最近 **月**日 **:** y = '2021-' time = time.replace('月','-').replace('日','') new_time = y + time return new_time #评论清洗def change_review(r): if ':' in r: r_ = r.split(':')[1] else: r_ = r return r_#评论点赞def change_likes(l): if l != []: l_ = int(l.split('(')[1].split(')')[0]) else: l_ = 0 return l_#拉动滚动条至翻页按钮处driver.execute_script("window.scrollTo(0,document.body.scrollHeight)") #获取页面信息num = input('请输入需要爬取的页面总数:') #想要爬取评论的页数,#这里的思路是先通过翻页将获取到的所有页面的所有内容存至列表,再对列表遍历。#因为当时直接用selenium 定位返回结果不对,当然你们也可以用selenium直接试试。html_list=[] for i in range(int(num)): page_text = driver.execute_script("return document.documentElement.outerHTML") html = etree.HTML(page_text)#获取页面 html_list.append(html) #翻页 driver.find_elements_by_xpath("//div[contains(@class,'u-page')]/a")[-1].click() time.sleep(4) WebDriverWait(driver, 300, 0.1).until(EC.presence_of_element_located((By.XPATH, "//div[@class='cmmts j-flag']"))) print(f'第{i+1}页爬取成功')rev_list=[] #所有评论的列表dat_list=[] #对应日期的列表for review_page in html_list: raw_reviews = review_page.xpath("//div[@class='cmmts j-flag']//div[@class='cnt f-brk']/text()")#提取页面所有评论 raw_reviews_ = [i for i in raw_reviews if ":" in i] #保证长度一致 rv_date = review_page.xpath("//div[@class='cmmts j-flag']//div[@class='cntwrap']/div[@class='rp']/div[@class='time s-fc4']/text()") review_list = [change_review(r) for r in raw_reviews_] date_list = [change_time(d) for d in rv_date] rev_list.extend(review_list) dat_list.extend(date_list) print('分析完成')driver.quit()运行结果: 1、排行榜: 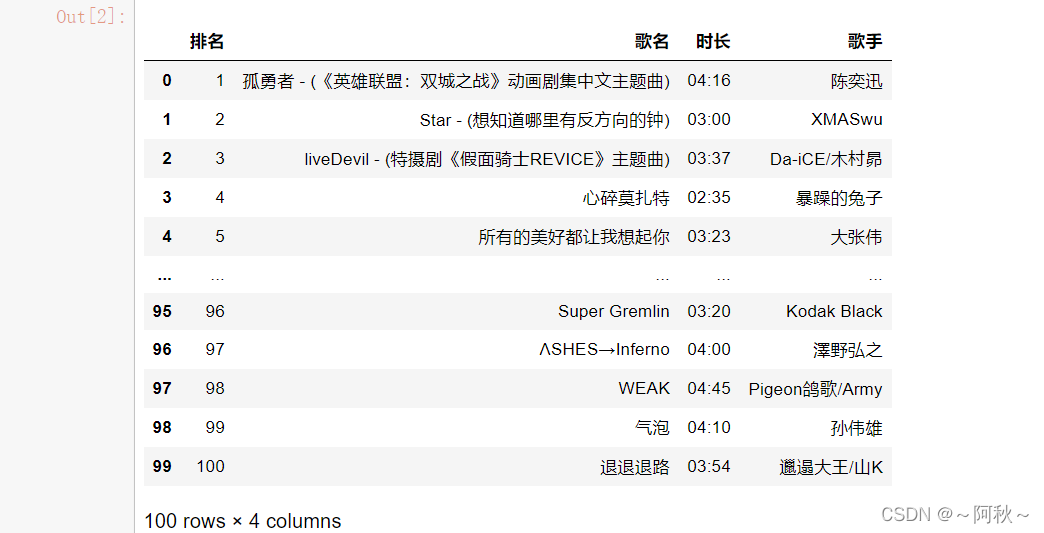
2、评论: 

总结哈哈,用了快两年的csdn, 光顾着白嫖文章。这也是我的第一个帖子,也没啥经验,有啥问题的,还请各位指正! 到此这篇关于python爬取网易云音乐排行榜数据代码的文章就介绍到这了,更多相关python爬取网易云内容请搜索51zixue.net以前的文章或继续浏览下面的相关文章希望大家以后多多支持51zixue.net!
详解Python之可迭代对象,迭代器和生成器
基于Python实现简易文档格式转换器 |


