етЦЊНЬГЬЛљгкOpenCVЪЕЯжаЁаЭЕФЭМЯёЪ§ОнПтМьЫїЙІФмаДЕУКмЪЕгУЃЌЯЃЭћФмАяЕНФњЁЃ
БОЮФЖдЧАУцЕФМИЦЊЮФеТНјааИізмНсЃЌЪЕЯжвЛИіаЁаЭЕФЭМЯёМьЫїгІгУЁЃ вЛИіаЁаЭЕФЭМЯёМьЫїгІгУПЩвдЗжЮЊСНВПЗжЃК - trainЃЌЙЙНЈЭМЯёМЏЕФЬиеїЪ§ОнПтЁЃ
- retrievalЃЌМьЫїЃЌИјЖЈЭМЯёЃЌДгЭМЯёПтжаЗЕЛизюРрЫЦЕФЭМЯё
ЙЙНЈЭМЯёЪ§ОнПтЕФЙ§ГЬШчЯТЃК - ЩњГЩЭМЯёМЏЕФЪгОѕДЪЛуБэ(Vocabulary)
ЬсШЁЭМЯёМЏЫљгаЭМЯёЕФsiftЬиеї ЖдЕУЕНЕФsifteЬиеїМЏКЯНјааОлРрЃЌОлРржааФОЭЪЧVocabulary - ЖдЭМЯёМЏжаЕФЭМЯёжиаТБрТыБэЪОЃЌПЩЪЙгУBoWЛђепVLADЃЌетРябЁдёVLAD.
- НЋЭМЯёМЏжаЫљгаЭМЯёЕФVLADБэЪОзщКЯЕНвЛЦ№ЕУЕНвЛИіVLADБэЃЌетОЭЪЧВщбЏЭМЯёЕФЪ§ОнПтЁЃ
ЕУЕНЭМЯёМЏЕФВщбЏЪ§ОнКѓЃЌЖдШЮвЛЭМЯёВщевЦфдкЪ§ОнПтжаЕФзюЯрЫЦЭМЯёЕФСїГЬШчЯТЃК - ЬсШЁЭМЯёЕФsiftЬиеї
- МгдиVocabularyЃЌЪЙгУVLADБэЪОЭМЯё
- дкЭМЯёЪ§ОнПтжаВщевгыИУVLADзюЯрЫЦЕФЯђСП
ЙЙНЈЭМЯёМЏЕФЬиеїЪ§ОнПтЕФСїГЬЭЈГЃЪЧofflineЕФЃЌВщбЏЕФЙ§ГЬдђашвЊЪЧЪЕЪБЕФЃЌЛљБОСїГЬВЮМћЯТЭМЃК 
гЩСНВПЗжЙЙГЩЃКofflineЕФбЕСЗЙ§ГЬвдМАonlineЕФМьЫїВщев ИїИіЙІФмФЃПщЕФЪЕЯжЯТУцОЭЪЙгУVLADБэЪОЭМЯёЃЌЪЕЯжвЛИіаЁаЭЕФЭМЯёЪ§ОнПтЕФМьЫїГЬађЁЃЯТУцЪЕЯжашвЊЕФЙІФмФЃПщ - ЬиеїЕуЬсШЁ
- ЙЙНЈVocabulary
- ЙЙНЈЪ§ОнПт
ЕквЛВНЃЌЬиеїЕуЕФЬсШЁВЛЙмЪЧBoWЛЙЪЧVLADЃЌЖМЪЧЛљгкЭМЯёЕФОжВПЬиеїЕФЃЌБОЮФбЁдёЕФОжВПЬиеїЪЧSIFTЃЌЪЙгУЦфРЉеЙRootSiftЁЃЬсШЁЕНЮШЖЈЕФЬиеїЕугШЮЊЕФживЊЃЌБОЮФЪЙгУOpenCVЬхХЖФЧИіЕФSiftDetecotrЃЌЪЕР§ЛЏШчЯТЃК auto fdetector = xfeatures2d::SIFT::create(0,3,0.2,10); createЕФЩљУїШчЯТЃК
static Ptr<SIFT> cv::xfeatures2d::SIFT::create ( int nfeatures = 0, int nOctaveLayers = 3, double contrastThreshold = 0.04, double edgeThreshold = 10, double sigma = 1.6 ) - nfeatures ЩшжУЬсШЁЕНЕФЬиеїЕуЕФИіЪ§ЃЌУПИіsiftЕФЬиеїЕуЖМИљОнЦфЖдБШЖШ(local contrast)МЦЫуГіРДвЛИіЗжЪ§ЁЃЩшжУСЫИУжЕКѓЃЌЛсИљОнЗжЪ§ХХађЃЌжЛБЃСєЧАnfeaturesИіЗЕЛи
- nOctaveLayers УПИіoctaveжаЕФВуЪ§ЃЌИУжЕПЩвдИљОнЭМЯёЕФЗжБцТЪДѓаЁМЦЫуГіРДЁЃD.LoweТлЮФжаИУжЕЮЊЃГ
- contrastThresholdЁЁЙ§ТЫЕєЕЭЖдБШЖШЕФВЛЮШЖЈЬиеїЕуЃЌИУжЕдНДѓЃЌЬсШЁЕНЕФЬиеїЕудНЩй
- edgeThresholdЁЁЙ§ТЫБпдЕДІЕФЬиеїЕуЃЌИУжЕдНДѓЃЌЬсШЁЕНЕФЬиеїЕуОЭдНЖр
- sigma ИпЫЙТЫВЈЦїЕФВЮЪ§ЃЌИУТЫВЈЦїгІгУгкЕк0ИіOctave
ИіШЫЕФвЛаЉМћНтЁЃ ЩшжУВЮЪ§ЪБЃЌжївЊЪЧЩшжУcontrastThresholdКЭedgeThresholdЁЃcontrastThresholdЪЧЙ§ТЫЕєЦНЛЌЧјгђЕФвЛаЉВЛЮШЖЈЕФЬиеїЕуЃЌedgeThresholdЪЧЙ§ТЧРрЫЦБпдЕЕФВЛЮШЖЈЙиМќЕуЁЃЩшжУВЮЪ§ЪБЃЌгІОЁСПБЃжЄЬсШЁЕФЬиеїЕуИіЪ§ЪЪжаЃЌВЛвзЙ§ЖрЃЌвВВЛвЊЙ§ЩйЁЃСэЭтЃЌcontrastThresholdКЭedgeThresholdЕФЦНКтЃЌгІИљОнвЊЬсШЁЕФФПБъЪЧБШНЯЦНЛЌЕФЧјгђЛЙЪЧЮЦРэНЯЖрЕФЧјгђЃЌРДЦНКтетСНИіВЮЪ§ЕФЩшжУЁЃ ЖдгкгааЉЭМЯёЃЌПЩФмЩшжУЕФЬсШЁЬиеїЕуЕФВЮЪ§НабЯИёЃЌЬсШЁЬиеїЕуЕФИіЪ§Й§ЩйЃЌетЪБКђПЩИФБфПэЫЩвЛаЉЕФВЮЪ§ЁЃ auto fdetector = xfeatures2d::SIFT::create(0,3,0.2,10);fdetector->detectAndCompute(img,noArray(),kpts,feature);if(kpts.size() < 10){ fdetector = xfeatures2d::SIFT::create(); fdetector->detectAndCompute(img,noArray(),kpts,feature);}уажЕ10ЃЌПЩИљОнОпЬхЕФЧщПіНјааЕїНкЁЃ ИќЖрЙигкsiftЕФФкШнПЩвдВЮПДЮФеТЃК ЙигкRootSiftКЭVLADПЩвдВЮПМЧАУцЕФЮФеТwww.jb51.net/article/231900.htm ЕкЖўВНЃЌЙЙНЈVocabularyVocabularyЕФЙЙНЈЙ§ГЬЃЌЪЕМЪОЭЪЧЖдЬсШЁЕНЕФЭМЯёЬиеїЕуЕФОлРрЁЃЪзЯШЬсШЁЭМЯёПтЭМЯёsiftЬиеїЃЌВЂНЋЦфРЉеЙЮЊRootSiftЃЌШЛКѓЖдЬсШЁЕНЕФRootSiftНјааОлРрЕУЕНVocabularyЁЃ
етРяДДНЈclass VocabularyЃЌжївЊвдЯТЗНЗЈЃК create ДгЬсШЁЕНЕФЬиеїЕуЙЙНЈОлРрЕУЕНЪгОѕДЪЛуБэVocabulary
void Vocabulary::create(const std::vector<cv::Mat> &features,int k){ Mat f; vconcat(features,f); vector<int> labels; kmeans(f,k,labels,TermCriteria(TermCriteria::COUNT + TermCriteria::EPS,100,0.01),3,cv::KMEANS_PP_CENTERS,m_voc); m_k = k;} loadКЭsaveЃЌЮЊСЫЪЙгУЗНБуЃЌашвЊФмЙЛНЋЩњГЩЕФЪгОѕДЪЛуБэVocabularyБЃДцЮЪЮФМў(.yml)tranform_vladЃЌНЋЪфШыЕФЭМЯёНјаазЊЛЛЮЊvladБэЪО void Vocabulary::transform_vlad(const cv::Mat &f,cv::Mat &vlad){ // Find the nearest center Ptr<FlannBasedMatcher> matcher = FlannBasedMatcher::create(); vector<DMatch> matches; matcher->match(f,m_voc,matches); // Compute vlad Mat responseHist(m_voc.rows,f.cols,CV_32FC1,Scalar::all(0)); for( size_t i = 0; i < matches.size(); i++ ){ auto queryIdx = matches[i].queryIdx; int trainIdx = matches[i].trainIdx; // cluster index Mat residual; subtract(f.row(queryIdx),m_voc.row(trainIdx),residual,noArray()); add(responseHist.row(trainIdx),residual,responseHist.row(trainIdx),noArray(),responseHist.type()); } // l2-norm auto l2 = norm(responseHist,NORM_L2); responseHist /= l2; //normalize(responseHist,responseHist,1,0,NORM_L2); //Mat vec(1,m_voc.rows * f.cols,CV_32FC1,Scalar::all(0)); vlad = responseHist.reshape(0,1); // Reshape the matrix to 1 x (k*d) vector}class VocabularyгавдЯТЗНЗЈЃК
- ДгЭМЯёСаБэжаЙЙНЈЪгОѕДЪЛуБэ
Vocabulary - НЋЩњГЩЕФ
VocabularyБЃДцЕНБОЕиЃЌВЂЬсЙЉСЫloadЗНЗЈ - НЋЭМЯёБэЪОЮЊVLAD
ЕкШ§ВНЃЌДДНЈЭМЯёЪ§ОнПтЭМЯёЪ§ОнПтвВОЭЪЧНЋЭМЯёVLADБэЪОЕФМЏКЯЃЌдкИУЪ§ОнПтМьЫїЪБЃЌЗЕЛигыqueryЭМЯёЯрЫЦЕФVLADЫљЖдгІЕФЭМЯёЁЃ
БОЮФЪЙгУOpenCVЬсЙЉЕФMatЙЙНЈвЛИіМђЕЅЕФЪ§ОнПтЃЌMatБЃДцЫљгаЭМЯёЕФvladЯђСПзщГЩЕФОиеѓЃЌдкМьЫїЪБЃЌЪЕМЪОЭЪЧЖдИУMatЕФМьЫїЁЃ
ЩљУїРрclass DatabaseЃЌЦфОпгавдЯТЙІФмЃК add ЬэМгЭМЯёЕНЪ§ОнПтsaveКЭload НЋЪ§ОнПтБЃДцЮЊЮФМў(.yml)retrieval МьЫїЃЌЖдБЃДцЕФvaldЯђСПЕФMatДДНЈЫїв§ЃЌЗЕЛизюЯрЫЦЕФНсЙћЁЃ ЕкЫФВНЃЌTrainerдкЩЯУцЪЕЯжСЫЬиеїЕуЕФЬсШЁЃЌЙЙНЈЪгОѕДЪЛуБэЃЌЙЙНЈЭМЯёБэЪОЮЊVLADЕФЪ§ОнПтЃЌетРяНЋЦфзщКЯЕНвЛЦ№ЃЌДДНЈTrainerРрЃЌЗНБубЕСЗЪЙгУЁЃ class Trainer{public: Trainer(); ~Trainer(); Trainer(int k,int pcaDim,const std::string &imageFolder, const std::string &path,const std::string &identifiery,std::shared_ptr<RootSiftDetector> detector); void createVocabulary(); void createDb(); void save();private: int m_k; // The size of vocabulary int m_pcaDimension; // The retrain dimensions after pca Vocabulary* m_voc; Database* m_db;private: /* Image folder */ std::string m_imageFolder; /* training result identifier,the name suffix of vocabulary and database voc-identifier.yml,db-identifier.yml */ std::string m_identifier; /* The location of training result */ std::string m_resultPath;};ЪЙгУTrainer ашвЊХфжУ - ЭМЯёМЏЫљдкЕФФПТМЪгОѕ
- ДЪЛуБэЕФДѓаЁЃЈОлРржааФЕФИіЪ§ЃЉ
- PCAКѓVLADБЃСєЕФЮЌЖШЃЌПЩЯШВЛЙмЩшжУЮЊ0ЃЌВЛНјааPCAбЕСЗКѓЪ§ОнЕФБЃДцТЗОЖЁЃ
- бЕСЗКѓЕФЪ§ОнБЃДцЮЊ
ymlаЮЪНЃЌУќУћЙцдђЪЧvoc-m_identifier.ymlКЭdb-m_identifier.ymlЁЃ ЮЊСЫЗНБуВтЪдВЛЭЌВЮЪ§ЕФЪ§ОнЃЌетРяЩшжУвЛИіКѓзКВЮЪ§m_identifier,РДЧјЗжВЛЭЌЕФВЮЪ§ЕФбЕСЗЪ§ОнЁЃ ЦфЪЙгУДњТыШчЯТЃК int main(int argc, char *argv[]){ const string image_200 = "/home/test/images-1"; const string image_6k = "/home/test/images/sync_down_1"; auto detector = make_shared<RootSiftDetector>(5,5,10); Trainer trainer(64,0,image_200,"/home/test/projects/imageRetrievalService/build","test-200-vl-64",detector); trainer.createVocabulary(); trainer.createDb(); trainer.save(); return 0;}ЭЕРСЃЌУЛгаХфжУЮЊВЮЪ§ЃЌЪЙгУЪБашвЊЩшжУКУЭМЯёЕФТЗОЖЃЌвдМАбЕСЗКѓЪ§ОнЕФБЃДцЪ§ОнЁЃ ЕкЮхВНЃЌSearcherдкDatabaseжаЃЌвбОЪЕЯжСЫretrievalЕФЗНЗЈЁЃ етРяжЎЫљвддйЗтзАвЛВуЃЌЪЧЮЊСЫИќКУЕФЦѕКЯвЕЮёЩЯЕФвЛаЉашЧѓЁЃБШШчЃЌЭМЯёЕФвЛаЉдЄДІРэЃЌЗжПщЃЌЖрЯпГЬДІРэЃЌВщбЏНсЙћЕФЙ§ТЫЕШЕШЁЃЙигкSearcherКЭОпЬхЕФгІгУёюКЯБШНЯЩюЃЌетРяжЛЪЧМђЕЅЕФЪЕЯжСЫИіretrievalЗНЗЈКЭВщбЏВЮЪ§ЕФХфжУЁЃ class Searcher{public: Searcher(); ~Searcher(); void init(int keyPointThreshold); void setDatabase(std::shared_ptr<Database> db); void retrieval(cv::Mat &query,const std::string &group,std::string &md5,double &score); void retrieval(std::vector<char> bins,const std::string &group,std::string &md5,double &score);private: int m_keyPointThreshold; std::shared_ptr<Database> m_db;};ЪЙгУвВКмМђЕЅСЫЃЌДгЮФМўжаМгдиVaocabularyКЭDatabaseЃЌЩшжУSearcherЕФВЮЪ§ЁЃ Vocabulary voc; stringstream ss; ss << path << "/voc-" << identifier << ".yml"; cout << "Load vocabulary from " << ss.str() << endl; voc.load(ss.str()); cout << "Load vocabulary successful." << endl; auto detector = make_shared<RootSiftDetector>(5,0.2,10); auto db = make_shared<Database>(detector); cout << "Load database from " << path << "/db-" << identifier << ".yml" << endl; db->load1(path,identifier); db->setVocabulary(voc); cout << "Load database successful." << endl; Searcher s; s.init(10); s.setDatabase(db); Summary 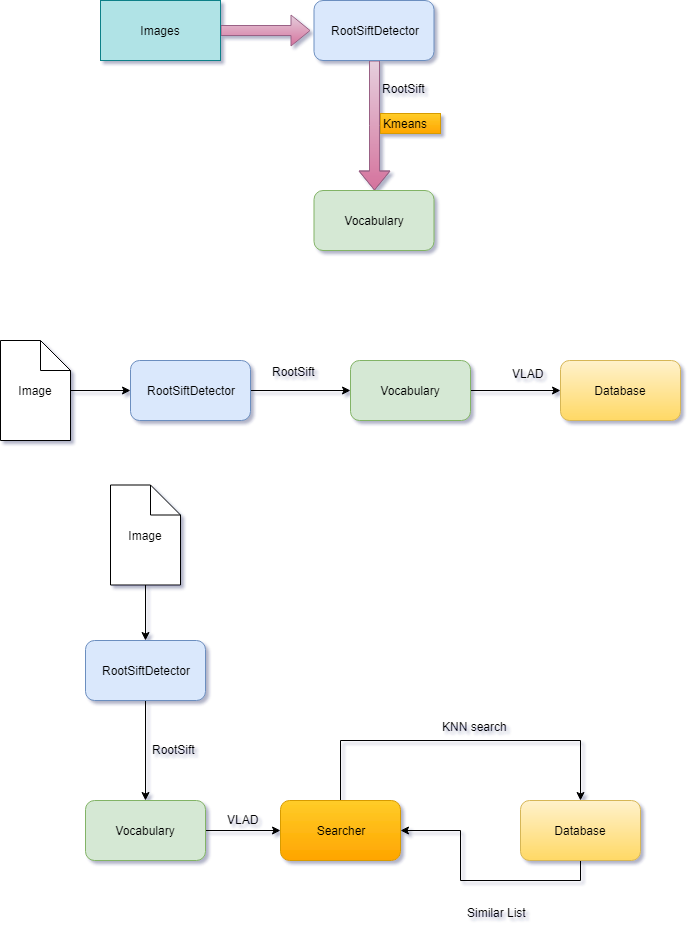
ЩЯЭМРДзмНсЯТећИіСїГЬ - ДДНЈ
Vocabulary - ДДНЈ
Database - Search Similary list
ЕНДЫетЦЊЙигкЛљгкOpenCVЪЕЯжаЁаЭЕФЭМЯёЪ§ОнПтМьЫїЕФЮФеТОЭНщЩмЕНетСЫ,ИќЖрЯрЙиOpenCVЭМЯёЪ§ОнПтМьЫїФкШнЧыЫбЫї51zixue.netвдЧАЕФЮФеТЛђМЬајфЏРРЯТУцЕФЯрЙиЮФеТЯЃЭћДѓМввдКѓЖрЖржЇГж51zixue.netЃЁ
pythonЛљДЁжЎФфУћКЏЪ§НщЩм
ЩюШыСЫНтpythonЕФКЏЪ§ВЮЪ§ |

