这篇教程python百行代码实现汉服圈图片爬取写得很实用,希望能帮到您。
平时旅游的时候,在旅游景区我们经常可以看到穿各种服饰去拍照的游客,也不会刻意多关注。前两天浏览网页无意看到一个网站,看到穿汉服的女孩是真的很好看。无论是工作需要还是创作文案,把这么漂亮的图片来当作素材都是一个很好的idea。有需要,我们就爬它,爬它,爬它! 话不多说,我们下面详细介绍图片爬取。
分析网站网址如下: https://www.aihanfu.com/zixun/tushang-1/ 这是第一页的网址,根据观察,第二页网址也就是上述网站序号1变成了2,依次类推,就可以访问全部页数。 
根据图示,我们需要获得每个子网站的链接,也就是href中网址,然后进入每个网址,寻找图片网址,在下载就行了。
子链接获取为了获取上图中的数据,我们可以用soup或者re或者xpath等方法都可以,本文中小编使用xpath来定位,编写定位函数,获得每个子网站链接,然后返回主函数,这里使用了一个技巧,在for循环中,可以看看! def get_menu(url, heades): """ 根据每一页的网址 获得每个链接对应的子网址 params: url 网址 """ r = requests.get(url, headers=headers) if r.status_code == 200: r.encoding = r.apparent_encoding html = etree.HTML(r.text) html = etree.tostring(html) html = etree.fromstring(html) # 查找每个子网址对应的链接, 然后返回 children_url = html.xpath('//div[@class="news_list"]//article/figure/a/@href') for _ in children_url: yield _
获取标题和图片地址为了尽量多的采集数据,我们把标签和图片地址采集一下,当然如果其他项目需要采集发布者和时间,也是可以做到多的,本篇就不再展开。 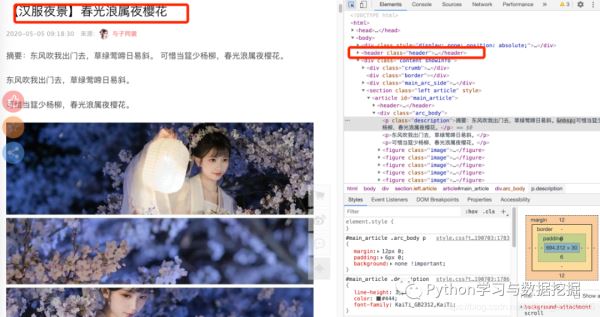
我们点开一个网址链接,如上图所示,可以发现标题在head的节点里面,获取标题是为创建文件夹时使用。 代码如下: def get_page(url, headers): """ 根据子页链接,获得图片地址,然后打包下载 params: url 子网址 """ r = requests.get(url, headers=headers) if r.status_code == 200: r.encoding = r.apparent_encoding html = etree.HTML(r.text) html = etree.tostring(html) html = etree.fromstring(html) # 获得标题 title = html.xpath(r'//*[@id="main_article"]/header/h1/text()') # 获得图片地址 img = html.xpath(r'//div[@class="arc_body"]//figure/img/@src') # title 预处理 title = ''.join(title) title = re.sub(r'【|】', '', title) print(title) save_img(title, img, headers)
保存图片在翻转每一页时我们都需要把子链接对应的图片保存下来,此处需要注意对请求的状态判断、路径判断。 def save_img(title, img, headers): """ 根据标题创建子文件夹 下载所有的img链接,选择更改质量大小 params:title : 标题 params: img : 图片地址 """ if not os.path.exists(title): os.mkdir(title) # 下载 for i, j in enumerate(img): # 遍历该网址列表 r = requests.get(j, headers=headers) if r.status_code == 200: with open(title + '//' + str(i) + '.png', 'wb') as fw: fw.write(r.content) print(title, '中的第', str(i), '张下载完成!')
主函数if __name__ == '__main__': """ 一页一页查找 params : None """ path = '/Users/********/汉服/' if not os.path.exists(path): os.mkdir(path) os.chdir(path) else: os.chdir(path) # url = 'http://www.aihanfu.com/zixun/tushang-1/' headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)' ' AppleWebKit/537.36 (KHTML, like Gecko)' ' Chrome/81.0.4044.129 Safari/537.36'} for _ in range(1, 50): url = 'http://www.aihanfu.com/zixun/tushang-{}/'.format(_) for _ in get_menu(url, headers): get_page(_, headers) # 获得一页至此我们已经完成了所有环节,关于爬虫的文章,小编已经不止一次的介绍了,一方面是希望大家可以多多熟悉爬虫技巧,另外一方面小编认为爬虫是数据分析、数据挖掘的基础。没有爬虫获取数据,何来数据分析。 以上就是python百行代码实现汉服圈图片爬取的详细内容,更多关于python爬取汉服圈图片的资料请关注51zixue.net其它相关文章!
python可视化大屏库big_screen示例详解
python 实现mysql增删查改示例代码 |

