这篇教程pytorch版本PSEnet训练并部署方式写得很实用,希望能帮到您。
概述源码地址 torch版本 训练环境没有按照torch的readme一样的环境,自己部署环境为: torch==1.9.1torchvision==0.10.1python==3.8.0cuda==10.2mmcv==0.2.12editdistance==0.5.3Polygon3==3.0.9.1pyclipper==1.3.0opencv-python==3.4.2.17Cython==0.29.24
制作数据集
1、训练的数据集采用的是rolabelimg进行标注,需要转换为ic2015格式的数据。 转换代码: import osfrom lxml import etreeimport numpy as npimport mathsrc_xml = "ANN"txt_dir = "gt"xml_listdir = os.listdir(src_xml)xml_listpath = [os.path.join(src_xml,xml_listdir1) for xml_listdir1 in xml_listdir]def xml_out(xml_path): gt_lines = [] ET = etree.parse(xml_path) objs = ET.findall("object") for ix,obj in enumerate(objs): name = obj.find("name").text robox = obj.find("robndbox") cx = int(float(robox.find("cx").text)) cy = int(float(robox.find("cy").text)) w = int(float(robox.find("w").text)) h = int(float(robox.find("h").text)) angle = float(robox.find("angle").text) # angle = math.degrees(angle1) wx1 = cx - int(0.5 * w) wy1 = cy - int(0.5 * h) wx2 = cx + int(0.5 * w) wy2 = cy - int(0.5 * h) wx3 = cx - int(0.5 * w) wy3 = cy + int(0.5 * h) wx4 = cx + int(0.5 * w) wy4 = cy + int(0.5 * h) x1 = int((wx1 - cx) * np.cos(angle) - (wy1 - cy) * np.sin(angle) + cx) y1 = int((wx1 - cx) * np.sin(angle) - (wy1 - cy) * np.cos(angle) + cy) x2 = int((wx2 - cx) * np.cos(angle) - (wy2 - cy) * np.sin(angle) + cx) y2 = int((wx2 - cx) * np.sin(angle) - (wy2 - cy) * np.cos(angle) + cy) x3 = int((wx3 - cx) * np.cos(angle) - (wy3 - cy) * np.sin(angle) + cx) y3 = int((wx3 - cx) * np.sin(angle) - (wy3 - cy) * np.cos(angle) + cy) x4 = int((wx4 - cx) * np.cos(angle) - (wy4 - cy) * np.sin(angle) + cx) y4 = int((wx4 - cx) * np.sin(angle) - (wy4 - cy) * np.cos(angle) + cy) lines = str(x1)+","+str(y1)+","+str(x2)+","+str(y2)+","+/ str(x3)+","+str(y3)+","+str(x4)+","+str(y4)+","+str(name)+"/n" gt_lines.append(lines) return gt_linesdef main(): count = 0 for xml_dir in xml_listdir: gt_lines = xml_out(os.path.join(src_xml,xml_dir)) txt_path = "gt_" + xml_dir[:-4] + ".txt" with open(os.path.join(txt_dir,txt_path),"a+") as fd: fd.writelines(gt_lines) count +=1 print("Write file %s" % str(count))if __name__ == "__main__": main()rolabelimg标注后的xml文件和labelimg的xml有些区别,根据不同的标注软件,转换代码略有区别。 转换后的格式为x1,y1,x2,y2,x3,y3,x4,y4,"classes",此处classes为检测的类别,如果是模糊训练的话,classes为“###”。 但是重点,这个源代码对于模糊训练,loss一直为1。
2、将数据集分成训练集和测试集
这里可以按照源码路径存放数据集,也可以修改源码存放位置。 PSENet-python3/dataset/psenet/psenet_ic15.py 修改下述代码为自己文件夹 
3、训练CUDA_VISIBLE_DEVICES=0,1,2,3 python train.py config/psenet/psenet_r50_ic15_736.py 其中根据源码中的readme, 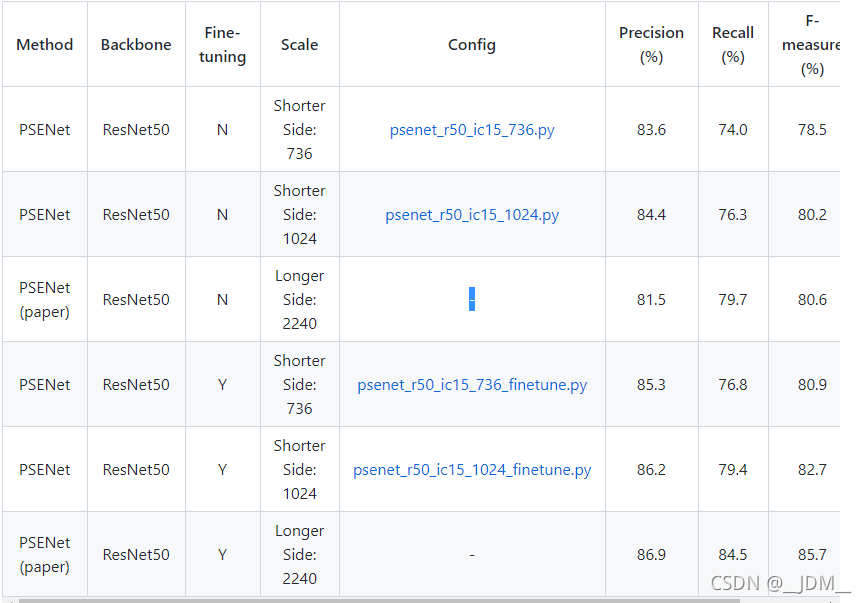
可以根据自己的需要,自行选择配置文件。 
4、部署测试import torchimport numpy as npimport argparseimport osimport os.path as ospimport sysimport timeimport jsonfrom mmcv import Configimport cv2from torchvision import transformsfrom dataset import build_data_loaderfrom models import build_modelfrom models.utils import fuse_modulefrom utils import ResultFormat, AverageMeterdef prepare_image(image, target_size): """Do image preprocessing before prediction on any data. :param image: original image :param target_size: target image size :return: preprocessed image """ #assert os.path.exists(img), 'file is not exists' #img = cv2.imread(img) img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # h, w = image.shape[:2] # scale = long_size / max(h, w) img = cv2.resize(img, target_size) # 将图片由(w,h)变为(1,img_channel,h,w) tensor = transforms.ToTensor()(img) tensor = tensor.unsqueeze_(0) tensor = tensor.to(torch.device("cuda:0")) return tensordef report_speed(outputs, speed_meters): total_time = 0 for key in outputs: if 'time' in key: total_time += outputs[key] speed_meters[key].update(outputs[key]) print('%s: %.4f' % (key, speed_meters[key].avg)) speed_meters['total_time'].update(total_time) print('FPS: %.1f' % (1.0 / speed_meters['total_time'].avg))def load_model(cfg): model = build_model(cfg.model) model = model.cuda() model.eval() checkpoint = "psenet_r50_ic15_1024_finetune/checkpoint_580ep.pth.tar" if checkpoint is not None: if os.path.isfile(checkpoint): print("Loading model and optimizer from checkpoint '{}'".format(checkpoint)) sys.stdout.flush() checkpoint = torch.load(checkpoint) d = dict() for key, value in checkpoint['state_dict'].items(): tmp = key[7:] d[tmp] = value model.load_state_dict(d) else: print("No checkpoint found at") raise # fuse conv and bn model = fuse_module(model) return modelif __name__ == '__main__': src_dir = "testimg/" save_dir = "test_save/" if not os.path.exists(save_dir): os.makedirs(save_dir) cfg = Config.fromfile("PSENet/config/psenet/psenet_r50_ic15_1024_finetune.py") for d in [cfg, cfg.data.test]: d.update(dict( report_speed=False )) if cfg.report_speed: speed_meters = dict( backbone_time=AverageMeter(500), neck_time=AverageMeter(500), det_head_time=AverageMeter(500), det_pse_time=AverageMeter(500), rec_time=AverageMeter(500), total_time=AverageMeter(500) ) model = load_model(cfg) model.eval() count = 0 for img_name in os.listdir(src_dir): img = cv2.imread(src_dir + img_name) tensor = prepare_image(img, target_size=(1376, 1024)) data = dict() img_metas = dict() data['imgs'] = tensor img_metas['org_img_size'] = torch.tensor([[img.shape[0], img.shape[1]]]) img_metas['img_size'] = torch.tensor([[1376, 1024]]) data['img_metas'] = img_metas data.update(dict( cfg=cfg )) with torch.no_grad(): outputs = model(**data) if cfg.report_speed: report_speed(outputs, speed_meters) for bboxes in outputs['bboxes']: x1 = bboxes[0] y1 = bboxes[1] x2 = bboxes[4] y2 = bboxes[5] cv2.rectangle(img, (x1, y1), (x2, y2), (0, 0, 255), 3) count = count + 1 cv2.imwrite(save_dir + img_name, img) print("img test:", count)from dataset import build_data_loaderfrom models import build_modelfrom models.utils import fuse_modulefrom utils import ResultFormat, AverageMeter 训练代码里含有。
总结以上为个人经验,希望能给大家一个参考,也希望大家多多支持wanshiok.com。
详解OpenCV-Python
Tensorflow训练模型默认占满所有GPU的解决方案 |



