这篇教程PyTorch模型容器与AlexNet构建示例详解写得很实用,希望能帮到您。
模型容器与AlexNet构建文章和代码已经归档至【Github仓库:https://github.com/timerring/dive-into-AI 】 除了上述的模块之外,还有一个重要的概念是模型容器 (Containers),常用的容器有 3 个,这些容器都是继承自nn.Module。 - nn.Sequetial:按照顺序包装多个网络层
- nn.ModuleList:像 python 的 list 一样包装多个网络层,可以迭代
- nn.ModuleDict:像 python 的 dict 一样包装多个网络层,通过 (key, value) 的方式为每个网络层指定名称。
nn.Sequetial深度学习中,特征提取和分类器这两步被融合到了一个神经网络中。在卷积神经网络中,前面的卷积层以及池化层可以认为是特征提取部分,而后面的全连接层可以认为是分类器部分。比如 LeNet 就可以分为特征提取和分类器两部分,这 2 部分都可以分别使用 nn.Seuqtial 来包装。 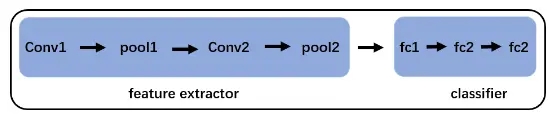
代码如下: class LeNetSequetial(nn.Module): def __init__(self, classes): super(LeNet2, self).__init__() self.features = nn.Sequential( nn.Conv2d(3, 6, 5), nn.ReLU(), nn.MaxPool2d(2, 2), nn.Conv2d(6, 16, 5), nn.ReLU(), nn.MaxPool2d(2, 2) ) self.classifier = nn.Sequential( nn.Linear(16*5*5, 120), nn.ReLU(), nn.Linear(120, 84), nn.ReLU(), nn.Linear(84, classes) ) def forward(self, x): x = self.features(x) x = x.view(x.size()[0], -1) x = self.classifier(x) return x 在初始化时,nn.Sequetial会调用__init__()方法,将每一个子 module 添加到 自身的_modules属性中。这里可以看到,我们传入的参数可以是一个 list,或者一个 OrderDict。如果是一个 OrderDict,那么则使用 OrderDict 里的 key,否则使用数字作为 key。 def __init__(self, *args): super(Sequential, self).__init__() if len(args) == 1 and isinstance(args[0], OrderedDict): for key, module in args[0].items(): self.add_module(key, module) else: for idx, module in enumerate(args): self.add_module(str(idx), module) 网络初始化完成后有两个子 module:features和classifier。 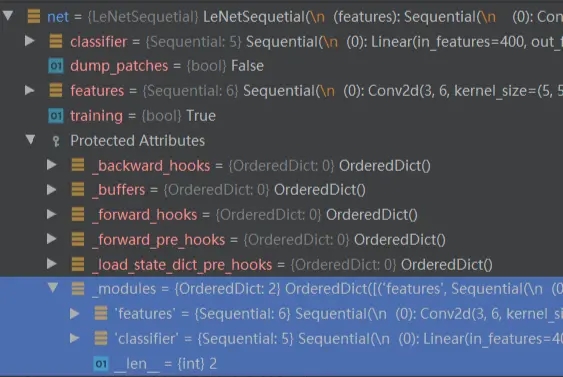
而features中的子 module 如下,每个网络层以序号作为 key: 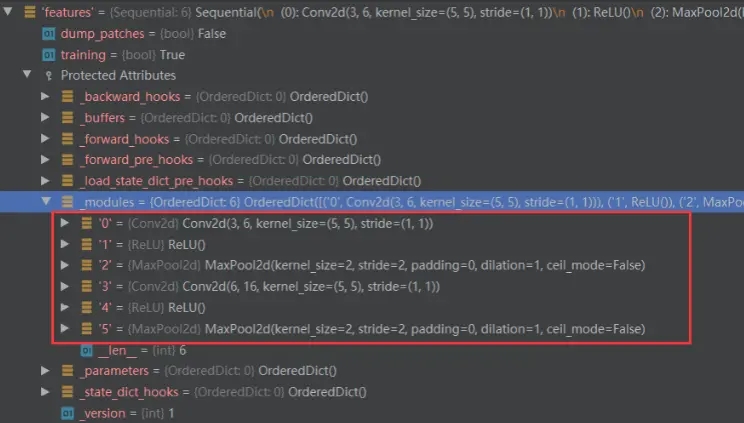
在进行前向传播时,会进入 LeNet 的forward()函数,首先调用第一个Sequetial容器:self.features,由于self.features也是一个 module,因此会调用__call__()函数,里面调用 result = self.forward(*input, **kwargs),进入nn.Seuqetial的forward()函数,在这里依次调用所有的 module。上一个module的输出是下一个module的输入。
def forward(self, input): for module in self: input = module(input) return input 在上面可以看到在nn.Sequetial中,里面的每个子网络层 module 是使用序号来索引的,即使用数字来作为key。 一旦网络层增多,难以查找特定的网络层,这种情况可以使用 OrderDict (有序字典)。可以与上面的代码对比一下 class LeNetSequentialOrderDict(nn.Module): def __init__(self, classes): super(LeNetSequentialOrderDict, self).__init__() self.features = nn.Sequential(OrderedDict({ 'conv1': nn.Conv2d(3, 6, 5), 'relu1': nn.ReLU(inplace=True), 'pool1': nn.MaxPool2d(kernel_size=2, stride=2), 'conv2': nn.Conv2d(6, 16, 5), 'relu2': nn.ReLU(inplace=True), 'pool2': nn.MaxPool2d(kernel_size=2, stride=2), })) self.classifier = nn.Sequential(OrderedDict({ 'fc1': nn.Linear(16*5*5, 120), 'relu3': nn.ReLU(), 'fc2': nn.Linear(120, 84), 'relu4': nn.ReLU(inplace=True), 'fc3': nn.Linear(84, classes), })) ... ... ...
总结nn.Sequetial是nn.Module的容器,用于按顺序包装一组网络层,有以下两个特性。
- 顺序性:各网络层之间严格按照顺序构建,我们在构建网络时,一定要注意前后网络层之间输入和输出数据之间的形状是否匹配
- 自带
forward()函数:在nn.Sequetial的forward()函数里通过 for 循环依次读取每个网络层,执行前向传播运算。这使得我们我们构建的模型更加简洁
nn.ModuleListnn.ModuleList是nn.Module的容器,用于包装一组网络层,以迭代的方式调用网络层,主要有以下 3 个方法:
- append():在 ModuleList 后面添加网络层
- extend():拼接两个 ModuleList
- insert():在 ModuleList 的指定位置中插入网络层
下面的代码通过列表生成式来循环迭代创建 20 个全连接层,非常方便,只是在 forward()函数中需要手动调用每个网络层。 class ModuleList(nn.Module): def __init__(self): super(ModuleList, self).__init__() self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(20)]) def forward(self, x): for i, linear in enumerate(self.linears): x = linear(x) return xnet = ModuleList()print(net)fake_data = torch.ones((10, 10))output = net(fake_data)print(output)
nn.ModuleDictnn.ModuleDict是nn.Module的容器,用于包装一组网络层,以索引的方式调用网络层,主要有以下 5 个方法:
- clear():清空 ModuleDict
- items():返回可迭代的键值对 (key, value)
- keys():返回字典的所有 key
- values():返回字典的所有 value
- pop():返回一对键值,并从字典中删除
下面的模型创建了两个ModuleDict:self.choices和self.activations,在前向传播时通过传入对应的 key 来执行对应的网络层。 class ModuleDict(nn.Module): def __init__(self): super(ModuleDict, self).__init__() self.choices = nn.ModuleDict({ 'conv': nn.Conv2d(10, 10, 3), 'pool': nn.MaxPool2d(3) }) self.activations = nn.ModuleDict({ 'relu': nn.ReLU(), 'prelu': nn.PReLU() }) def forward(self, x, choice, act): x = self.choices[choice](x) x = self.activations[act](x) return xnet = ModuleDict()fake_img = torch.randn((4, 10, 32, 32))output = net(fake_img, 'conv', 'relu')# output = net(fake_img, 'conv', 'prelu')print(output)
容器总结- nn.Sequetial:顺序性,各网络层之间严格按照顺序执行,常用于 block 构建,在前向传播时的代码调用变得简洁
- nn.ModuleList:迭代行,常用于大量重复网络构建,通过 for 循环实现重复构建
- nn.ModuleDict:索引性,常用于可选择的网络层
AlexNet实现AlexNet 特点如下: - 采用 ReLU 替换饱和激活函数,减轻梯度消失
- 采用 LRN (Local Response Normalization) 对数据进行局部归一化,减轻梯度消失
- 采用 Dropout 提高网络的鲁棒性,增加泛化能力
- 使用 Data Augmentation,包括 TenCrop 和一些色彩修改
AlexNet 的网络结构可以分为两部分:features 和 classifier。 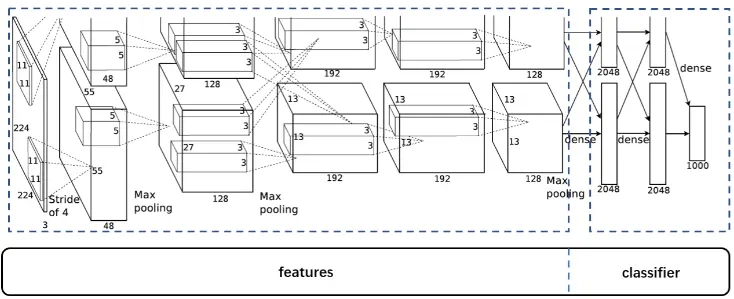
可以在计算机视觉库torchvision.models中找到 AlexNet 的代码,通过看可知使用了nn.Sequential来封装网络层。 class AlexNet(nn.Module): def __init__(self, num_classes=1000): super(AlexNet, self).__init__() self.features = nn.Sequential( nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), nn.Conv2d(64, 192, kernel_size=5, padding=2), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), nn.Conv2d(192, 384, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=3, stride=2), ) self.avgpool = nn.AdaptiveAvgPool2d((6, 6)) self.classifier = nn.Sequential( nn.Dropout(), nn.Linear(256 * 6 * 6, 4096), nn.ReLU(inplace=True), nn.Dropout(), nn.Linear(4096, 4096), nn.ReLU(inplace=True), nn.Linear(4096, num_classes), ) def forward(self, x): x = self.features(x) x = self.avgpool(x) x = torch.flatten(x, 1) x = self.classifier(x) return x 以上就是PyTorch模型容器与AlexNet构建示例详解的详细内容,更多关于PyTorch AlexNet构建的资料请关注wanshiok.com其它相关文章!
python绘制二维直方图的代码实现
深入理解python Matplotlib库的高级特性 |



