这篇教程KNN的原理及Python实现写得很实用,希望能帮到您。KNN的原理及Python实现
完整实现代码请参考本人的p...哦不是...github:knn_base.py
knn_classifier.py
knn_regressor.py
knn_classifier_example.py
knn_regressor_example.py
1. 原理篇
我们用大白话讲讲KNN是怎么一回事。
1.1 渣男识别
如果有一个男生叫子馨,我们如何识别子馨这个家伙是不是渣男呢?首先,我们得了解一下这个子馨的基本信息。比如身高180cm,体重180磅,住宅180平米,眼镜180度。那么,我们可以从记忆里搜寻一下这样的男生,发现梓馨、紫欣和子昕都基本符合这些信息,而且这三个男生都是渣男。综上,我们基本可以断定子馨也是渣男。这就是KNN算法的核心思想。
1.2 欧式距离
如果你深深的脑海里有好多男生的信息,怎么判定这些男生与子馨是否相似呢?一个比较简单的方式就是用欧式距离,公式如下:
1.3 KNN
总结一下,K最近邻(k-Nearest Neighbor,KNN)的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
1.4 算法复杂度
假设我们有m个男生的信息,n种特征(身高、体重、颜值、才华……),要找到与子馨最相似的k个男生,需要进行多少次计算呢?如果用比较暴力的方式,只要要m * n * k次计算,这可不是一个好消息。等计算完毕,子馨的孩子都退休了。
1.5 降低算法复杂度
首先这是一个寻找TOP K的问题,解决这类问题的经典套路就是利用大顶堆。其次,这是一个多维数组的查找的问题,KD-Tree也是解决这类问题的一个不错的方式。对这两个算法不了解的同学可以参考我之前的文章。如何将二者结合起来用呢,其实很简单。KD-Tree只能找到最近邻,而我们需要找到k近邻。所以当找到最近邻的时候,让算法不要退出循环,继续查找,直到我们的大顶堆中堆顶也比未被查找的邻居们都近时,再退出循环。相信会有人觉得不知所云,所以还是看看我之前的文章吧:)
1.6 大顶堆
之前的一篇文章曾经讲过大顶堆的原理和实现。链接如下:
李小文:大顶堆的原理及Python实现 zhuanlan.zhihu.com 1.7 KD-Tree
之前的一篇文章曾经讲过KD-Tree的原理和实现。链接如下:
李小文:KD Tree的原理及Python实现 zhuanlan.zhihu.com 2. 实现篇
本人用全宇宙最简单的编程语言——Python实现了KNN算法,没有依赖任何第三方库,便于学习和使用。简单说明一下实现过程,更详细的注释请参考本人github上的代码。
2.1 导入大顶堆和KD-Tree
这两个类在我github上可以找到,链接如下:max_heap.py kd_tree.py
from ..utils.kd_tree import KDTree
from ..utils.max_heap import MaxHeap
2.2 创建KNeighborsBase类
k_neighbors存储k值,tree用来存储kd_tree。
class KNeighborsBase ( object ):
def __init__ ( self ):
self . k_neighbors = None
self . tree = None
2.3 训练KNN模型
设定k值,并建立kd-Tree。
def fit ( self , X , y , k_neighbors = 3 ):
self . k_neighbors = k_neighbors
self . tree = KDTree ()
self . tree . build_tree ( X , y )
2.4 创建KDTree类
寻找Xi的k近邻,代码看不懂没关系。慢慢来,毕竟我自己回过头来看这段代码也是一言难尽。
2. 建立大顶堆
3. 建立队列
4. 外层循环更新大顶堆
5. 内层循环遍历kd_Tree
6. 满足堆顶是第k近邻时退出循环
def _knn_search ( self , Xi ):
tree = self . tree
heap = MaxHeap ( self . k_neighbors , lambda x : x . dist )
nd = tree . _search ( Xi , tree . root )
que = [( tree . root , nd )]
while que :
nd_root , nd_cur = que . pop ( 0 )
nd_root . dist = tree . _get_eu_dist ( Xi , nd_root )
heap . add ( nd_root )
while nd_cur is not nd_root :
nd_cur . dist = tree . _get_eu_dist ( Xi , nd_cur )
heap . add ( nd_cur )
if nd_cur . brother and \
( not heap or
heap . items [ 0 ] . dist >
tree . _get_hyper_plane_dist ( Xi , nd_cur . father )):
_nd = tree . _search ( Xi , nd_cur . brother )
que . append (( nd_cur . brother , _nd ))
nd_cur = nd_cur . father
return heap
2.5 分类问题的预测方法
找到k近邻,取众数便是预测值。这里的写法仅针对二分类问题。
def _predict ( self , Xi ):
heap = self . _knn_search ( Xi )
n_pos = sum ( nd . split [ 1 ] for nd in heap . _items )
return int ( n_pos * 2 > self . k_neighbors )
2.6 回归问题的预测方法
找到k近邻,取均值便是预测值。
def _predict ( self , Xi ):
heap = self . _knn_search ( Xi )
return sum ( nd . split [ 1 ] for nd in heap . _items ) / self . k_neighbors
2.7 多个样本预测
_predict只是对单个样本进行预测,所以还要写个predict方法。
def predict ( self , X ):
return [ self . _predict ( Xi ) for Xi in X ]
3 效果评估
3.1 分类问题
使用著名的乳腺癌数据集,按照7:3的比例拆分为训练集和测试集,训练模型,并统计准确度。(注意要对数据进行归一化)
@run_time
def main ():
print ( "Tesing the performance of KNN classifier..." )
X , y = load_breast_cancer ()
X = min_max_scale ( X )
X_train , X_test , y_train , y_test = train_test_split ( X , y , random_state = 20 )
clf = KNeighborsClassifier ()
clf . fit ( X_train , y_train , k_neighbors = 21 )
model_evaluation ( clf , X_test , y_test )
3.2 回归问题
使用著名的波士顿房价数据集,按照7:3的比例拆分为训练集和测试集,训练模型,并统计准确度。(注意要对数据进行归一化)
@run_time
def main ():
print ( "Tesing the performance of KNN regressor..." )
X , y = load_boston_house_prices ()
X = min_max_scale ( X )
X_train , X_test , y_train , y_test = train_test_split (
X , y , random_state = 10 )
reg = KNeighborsRegressor ()
reg . fit ( X = X_train , y = y_train , k_neighbors = 3 )
get_r2 ( reg , X_test , y_test )
3.3 效果展示
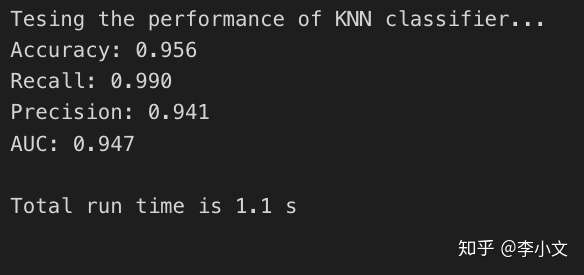
分类模型AUC 0.947,运行时间1.1秒;
回归模型R2 0.780,运行时间212毫秒;
效果还算不错~
3.4 工具函数
本人自定义了一些工具函数,可以在github上查看:
tushushu/imylu github.com 1. run_time - 测试函数运行时间
2. load_breast_cancer - 加载乳腺癌数据
3. train_test_split - 拆分训练集、测试集
4. min_max_scale - 归一化
5. model_evaluation - 分类模型的acc,precision,recall,AUC
6. get_r2 - 回归模型的r2
7. load_boston_house_prices - 加载波士顿房价数据
总结
KNN分类的原理:用KD-Tree和大顶堆寻找最k近邻
全连接神经网络的原理及Python实现 高斯朴素贝叶斯的原理及Python实现