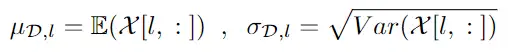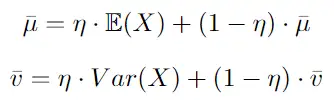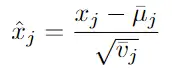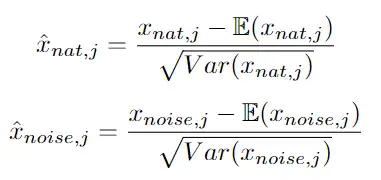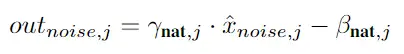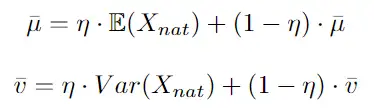在现实世界中高度不平衡的长尾数据使得网络不能很好的泛化。
因此,本文直接使用纯噪声图像数据进行训练,而不是使用加性噪声或对抗噪声。另外,本文提出DAR-BN,可以在同一个网络中既训练自然数据又训练纯噪声图像,使得网络泛化能力增强并抑制过拟合。
本文提出的方法可以作为数据增广的其中一种通用方法,加入到任何网络训练中去以提升效果。通过DAR-BN以及加入纯噪声图像进行训练,可以为不平衡数据的学习以及数据增广等提供更好的解决方案。
1.Paper profile
Pure Noise to the Rescue of Insufficient Data: Improving Imbalanced Classification by Training on Random Noise Images
论文地址:https:// export.arxiv.org/pdf/21 12.08810.pdf
代码地址:https:// github.com/shiranzada/p ure-noise
2.Motivation
虽然许多公开数据集是类平衡的,但在现实世界中,大部分数据类别是极为不平衡的。例如在医学图像领域,常见病的图像数据会很多,而许多罕见病的数据可能会相当稀少。在不平衡的数据上训练,网络会更加偏向多数类,而少数类的泛化能力会很差。
基于此,本文提出了给类别少的类进行过采样并加入纯噪声图像进行训练。此外,本文不使用原始BN,而是使用新提出的DAR-BN(Distribution-Aware Routing Batch Normalization layer)来代替BN层,DAR-BN 专门设计用于减轻两个不同输入域(即自然图像和纯噪声图像)之间的分布偏移,且DAR-BN可以用作通用归一化方式运用到其他网络中去。实验表明,使用纯噪声图像加DAR-BN的方法要优于使用加性噪声或乘性噪声,也优于使用BN的方法。
3.Related Work
3.1 Imbalanced Classification
一般情况下有四类办法解决不平衡分类:
(1)re-weighting:对loss重新加权,给少数样本的loss给予更高的权重。
(2)re-sampling:重新采样数据集以在训练期间重新平衡类分布,比如对多数类进行欠采样,或对少数类进行过采样。
但re-weighting和re-sampling的问题在于,重新加权方法(re-weighting)通常会过度拟合少数类,重采样方法(re-sampling)由于信息丢失,对多数类的欠采样可能会损害分类准确性,而过采样会导致对少数类的过拟合。
另外还有两种解决不平衡分类的方法为:
(1)边际损失:使用使决策边界远离少数类样本的损失函数来解决不平衡数据。
(2)解耦训练:将特征表示学习与最终分类任务分开可能有利于不平衡分类。
本文基于的是对不平衡分类数据的重新平衡来解决痛点,即数据重采样(re-sampling)。
3.2 Noise-Based Augmentation
使用噪声的数据增广方面,一般情况下会使用加性噪声或乘性噪声。
加入加性或乘性噪声,可以提高模型对噪声输入的鲁棒性,并通过随机“遮挡”其中的一部分来防止其对特定输入特征的固定。
但对数据图像应用小剂量的加性或乘性噪声会产生与原始图像非常接近的样本,从而限制了数据的可变性,并且由于自然图像的分布变化很大,会降低模型的性能。此外,虽然能改善过拟合,但是训练期间是使用的特定的噪声来改进的,这不利于网络拥有更强的泛化能力。
另外一种使用噪声的方式是使用对抗训练的加性噪声,其旨在通过用小的优化噪声扰乱图像来“欺骗”深度模型。特别相关的是 M2m(Kim 等人,2020),它建议在不平衡的分类设置中使用对抗性噪声将图像从主要类别“转移”到次要类别。同样,AdvProp(Xie等人, 2020)建议利用对抗性示例来提高一般(平衡)分类设置中的准确性和鲁棒性。目的是为了弥合两种输入(真实图像和对抗图像)之间的分布差距,为此他们使用了一个辅助的批量归一化层。
而在本文中,训练数据是使用纯噪声图像而不是对抗样本来丰富的。此外,AdvProp 学习了两组完全独立的批规范参数,而在DAR-BN 中,参数仅仅基于真实图像学习,不基于纯噪声图像,然后将参数应用于两个数据源。
3.3 Normalization Layers
无论是BN、LN还是GN,所有这些层的共同点是,它们基于整个训练集的一组统计数据(即均值和方差)对特征图进行归一化。当所有数据样本都来自相同的基础分布时,这可能会很好地工作,但当数据是多模态的或来自多个不同的域时,它是次优的。使用带有标准 BN 层的噪声图像会导致分类结果显著下降,甚至低于完全不使用噪声的baseline。
数据是多模态或者来自不同的域时,一般会通过调整内容和样式输入的统计数据,为样式迁移引入了自适应实例规范化,或者为不同域保留单独的归一化项集来减轻域偏移。
在本文使用的DAR-BN中,DAR-BN 使用自然特征图学习的仿射参数来缩放和移动噪声特征图。最后,由于在测试时输入仅从自然图像域中采样,因此 DAR-BN 仅使用自然数据图像的特征图更新批量统计信息。
4.Method
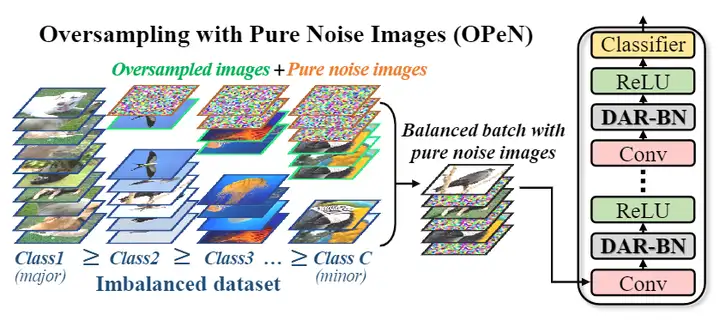
4.1 Oversampling with Pure Noise Images (OPeN)
本文提出了一种新的框架OPeN,用于进行图像过采样和生成纯随机噪声。
首先需要将部分过采样图像替换为纯随机噪声图像,概率如下:
其中 ci 是图像 x 的相关类标签,ρi 是类 ci 的表示比率(即当前类别图像数量与最大类别图像数量之间的比值),xnoise 是使用数据集中所有图像的均值和方差从正态分布中随机采样的。δ ∈ [0, 1] 是定义纯噪声图像和自然图像之间比率的超参数。较低的 ρi 导致用纯随机噪声图像替换来自类别 ci 的样本的概率更高,反之亦然。
纯随机噪声图像生成如下。设 X 为数据集 D 中的训练图像集。我们首先计算每个颜色通道 l ∈ {1, 2, 3} 的均值和标准差:
然后从遵循正态分布的噪声图像中采样并裁剪到可行域[0,1]:
每个epoch都要随机采样新的噪声图像,因为这有助于网络避免过拟合特定的噪声图像。OPeN整体的算法伪代码如下图所示。
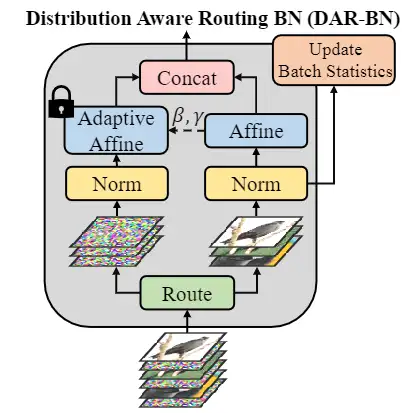
4.2 Distribution-Aware Routing Batch Norm (DAR-BN)
本文提出的DAR-BN,可以分别对噪声特征图和自然特征图进行归一化。
首先参考BN。BN层通过首先在特征空间和批量维度上对输入进行归一化,然后应用具有可训练参数的仿射层来独立地作用于每个通道。形式上,对于每个通道:
βj , γj 是每个通道的可训练参数。
在推理时,使用批量统计数据的指数移动平均值 (EMA) 在训练期间计算的running mean和running variance对输入进行归一化:
其中 η 是动量参数。
然后,在测试时,数据通过running mean和running variance进行归一化:
受BN启发,改良版的DAR-BN需要分别对噪声图像和自然数据图像进行归一化,具体如下。
对于噪声通道和自然数据图像通道做如下操作:
然后使用由自然数据特征图学习的仿射参数来缩放和偏移噪声特征图:
这里需要注意的是,噪声通道与自然数据图像的可训练参数βj , γj,均使用自然数据图像的迭代来进行更新,而不采用噪声通道的参数。
最后,由于在测试时输入仅从自然数据图像域中采样,因此DAR-BN仅使用自然数据图像的特征图更新批量统计信息。
DAR-BN整体的伪代码如下:
5.Experiment
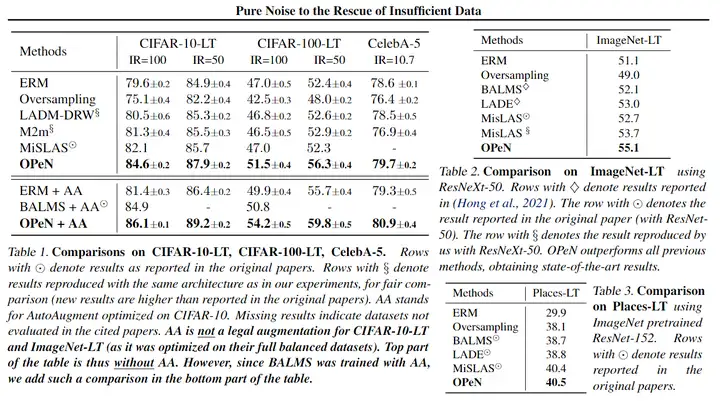
本文在五个用于不平衡分类的基准数据集上评估方法:CIFAR-10-LT、CIFAR-100-LT、ImageNet-LT、Places-LT 和 CelebA-5。并且训练时在类不平衡的数据集上进行训练,但测试时在类平衡的数据集上测试。 实验结果如下。
其中长尾数据集的不平衡比(IR)定义为 IR=nmax/nmin,其中 nmax 和 nmin 分别是训练集中最大类和最小类中的训练图像数。AA 代表 AutoAugment 在 CIFAR-10 上优化。缺失的结果表明被引用论文中未评估的数据集。由于 BALMS 是用 AA 训练的,所以在表的底部添加了这样的比较。
可以看出,OPeN在所有基准数据集的各个baseline上都取得了SOTA的结果。实验表明,向少数类添加纯噪声(而不是仅增加现有的训练图像)显著减少了过拟合问题并提高了泛化能力。
5.1 Ablation Studies
为了严谨,证明各个parts是有效的,本文进行了消融实验。
对于单使用纯噪声的消融实验结果如下:
与ERM baseline和单纯的过采样(Oversampling)相比较,可以发现OPeN的的效果最好。
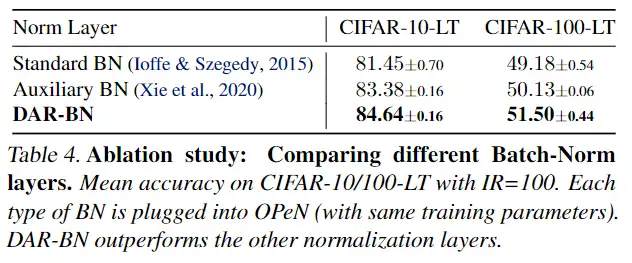
DAR-BN方面,与各种其他BN相比,消融实验结果如下:
可以发现,DAR-BN在CIFAR-10-LT、CIFAR-100-LT两个数据集上的效果也优于其他BN。
5.2 Pure Noise Images – a General Useful Augmentation
为了证明纯噪声可以用做一般的数据增广使用,且DAR-BN可以用做一般的BN层在各个网络中使用,本文也在标准非不平衡数据集CIFAR-10和CIFAR-100上进行了测试。
使用 Wide-ResNet-28-10 架构(Zagoruyko & Komodakis,2016)对类平衡的 CIFAR10 和 CIFAR-100 进行实验,所有模型都使用 Adam 优化器训练了 200 个 epoch,β1 = 0.9 和 β2 = 0.999,并具有标准的交叉熵损失。噪声图像是从具有相应训练集的均值和方差的高斯分布中采样的,并且每批中的噪声与真实比率为1:4,结果如下:
实验结果表明,适当地利用纯噪声图像(使用DAR-BN)通常可以作为一种额外的有用的增强方法,而无需任何详细的数据创建方案 。它具有进一步提高分类准确性的潜力,即使在高度复杂的增强方法(如 AutoAugment)之上使用也是如此。
5.3 Generalization as a Function of the Class Size
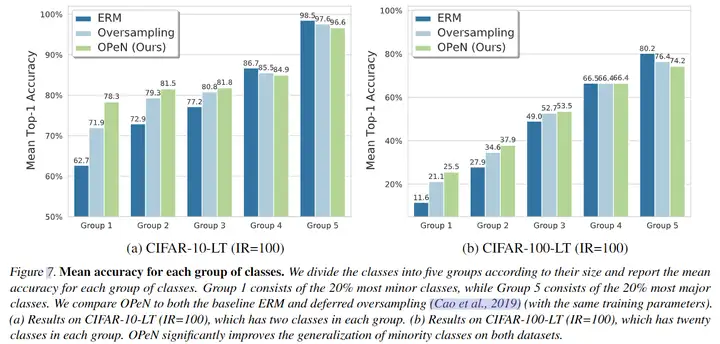
为了证明本文是对少数类的泛化能力有明显增强,设计了如下实验。
本文将类(根据不同数据集的样本类大小)分成五个大小相等的非重叠组,即每组包含 20% 的类。例如,对于 CIFAR-100-LT,第 1 组由训练集中的 20 个最小的类组成,而第 5 组由 20 个最大的类组成。相似的,对于 CIFAR-10-LT,每组由两个类组成。测试结果如下:
实验表明,在两个数据集上,第1、2、3组(即相对小的类)使用OPeN的效果要好于ERM baseline和过采样,而第4、5组(相对而言较大的类)的效果不如ERM baseline和过采样,即OPeN确实是对少数类的泛化能力有了增强 。
6.Why it works
通读文章,我认为纯噪声能work的关键有以下几点:
(1)对纯噪声图像进行过采样也会增加少数梯度分量的幅度,但同时会增加其方向的随机性。
(2)通过使用随机噪声图像,生成的新的训练样本不受数据中现有样本种类的限制。通过这种方式绕过了少数样本带来的限制,并明确地教导网络处理明显超出其训练集分布的输入。
(3)使用噪声图像的一个关键影响是影响网络学习的先验类概率,由于在所提出的重采样方案中,更多的噪声图像被分配给少数类,我们假设网络学习隐式地编码这些先验概率并相应地修正其预测。
而纯噪声在这之前,并不被大家作为一般的数据增广使用的原因,可能是由于当训练数据稀缺时,这些方法显示出轻微的改进,应用小剂量的噪声产生接近原始图像的新图像,从而提供有限的数据可变性。
并且从实验上看,对分布外的纯噪声图像进行训练在抑制过拟合方面具有重要的附加价值,而不仅仅是对现有训练图像的增强 。如果将添加纯噪声图像作为一种通用的数据增广方法是有效的,它补充了现有的增强方法,即使在标准的平衡数据集中也是如此 。
7.Conclusion
本文提出了一个用于不平衡图像分类的新框架 OPeN,通过使用纯噪声图像作为额外的训练样本以及DAR-BN来重新平衡训练集。这些方法在各种不平衡的分类基准上实现了 SOTA 结果。特别是,它显著提高了少数类的泛化能力。这些方法可以作为一种通用的方法运用到数据增广和各个网络中去提升性能。本文还开发了DAR-BN来弥合真实和纯噪声图像之间的分布差距,但它可能可以作为一个新的BN层来弥合神经网络中不同输入域对之间的差距。本文的工作可能会为利用噪声以及其他类型的分布外数据开辟新的研究方向,既用于不平衡分类,也用于一般数据增广。