��������һ��ƽʱ���õĶ�ģ̬���ݼ��Ա�֮�ã���Ҫ��Ϊ
�����ϵ�ȥ���ӣ�Ҳϣ���ܹ��ﵽ�����ˣ���ӭ��Ҳ��䡣
��0��.��ģ̬�Լ���������������Ż��߲������ݼ���
�����������кܶ�С���Զ�ģ̬���治֪����ô���ţ���֪��ʹ����Щ���ݼ�����ķ�������һƪ�����������ط���Ķ�ģ̬���ģ�ͨ��related work�����˽��������ķ�չ��ͨ��experiment�˽��������Ƚ��ܻ�ӭ��һЩ���ݼ������Ŀ�����googleѧ������arxiv�����������ܲ鵽Ŀǰ�ֵ����ġ�
https://www.aclweb.org/anthology/ �����վ�кܶ�������ģ�����ACL��EMNLP�ȵ�
https://papers.nips.cc/ �����վ��Ӱ�����ر���Nips��������
�������Ӿ���������ݲ�ѯ��ͨ����ݿ����ҵ���Ӧ��ݵ����л������ģ��dz�����Ŷ��
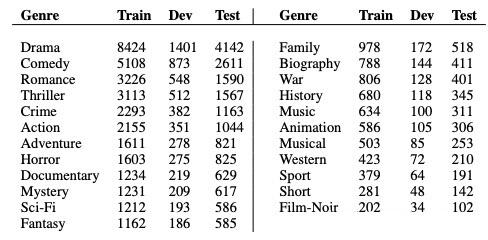
��1��.��ģ̬�������ݼ�(������з��ࡢӰ�ӷ���)
һ��˫ģ̬��һ�����ı���ͼ���������������ϣ�
1.��Multi-Modal Sarcasm Detection in Twitter with Hierarchical Fusion Model��--����ģ̬����ʶ�� 2019�ꡣ�����н��������ݼ��������ı���ͼ������ģ̬��������˵������ģ̬���ı����ְ����������棺һ�����������ı�ģ̬������һ����ͼ������ԣ���ͼ�������Щ������������������Ҳ���Թ���Ϊ����ģ̬�������ݼ��Ϻ�֮���Ǹ�����ԭʼ���ݣ�����ԭʼ���ı���ԭʼ��ͼ��������������������������ʵ����������ݼ��ʹ���������https://github.com/headacheboy/data-of-multimodal-sarcasm-detection
2.��Towards Multimodal Sarcasm Detection(An Obviously Perfect Paper)��--����ģ̬����ʶ��2019�ꡣ���ĸ�����ͼ����ı�˫ģ̬������Ƶ������ÿ����ǩ��Ӧ��ͼ������������Ӧ���ı���һ��Ի�����������ͼ��ʾ��
���ݼ������ǣ�https://github.com/soujanyaporia/MUStARD
������ģ̬��һ�����ı���ͼ���������
1.��Multimodal Language Analysis in the Wild_ CMU-MOSEI Dataset and Interpretable Dynamic Fusion Graph��--����ģ̬��к�����������2018�ꡣ������������CMU-MOSEI���ݼ���ģ������ģ̬���ݼ�֮һ���Ҿ�����к�����������ǩ����д�negative��positiveһ����7���������������ŭ�����ġ����ˡ����ȡ����º����6����𣬱�ǩ����ֵ��[-3~3]֮�䡣���ݼ�������ԭʼ���ݣ����ǹ���ԭʼ�������������ı�����Ƶ����Ƶ�ļ���ͼ���Լ�ȥ�Թ̶�Ƶ�ʲ����Һ��ı��������仹�DZȽ��鷳�ġ����ʵ�鶼ʹ�ô����õ�ʵ�����ݡ����ݼ��������ǣ�http://immortal.multicomp.cs.cmu.edu/raw_datasets/processed_data/
2.��UR-FUNNY: A Multimodal Language Dataset for Understanding Humor��--����ģ̬��Ĭ������2019�ꡣ��������������UR-FUNNY���ݼ��������ı�����ͼ������ģ̬��������Ĭ��С�����Ŀǰû�õ�û��ϸ�����պ��ٲ��䡣���ݼ��ʹ��������ǣ�https://github.com/ROC-HCI/UR-FUNNY
����ͬѧ����ʧ�ܣ�����������������ӣ�
���ӣ�https://pan.baidu.com/s/1iOwSmlaQeTo3NH95LnPl0A
��ȡ�룺5z4o
3.��MOSI: Multimodal Corpus of Sentiment Intensity and Subjectivity Analysis in Online Opinion Videos��--����ģ̬��������������������������CMU-MOSI���ݼ�����������CMU-MOSEI���ݼ����ֺ����Ƿ������磬��ģС��ֻ�������ı�ǩ�����ݼ���MOSEIһ�����д����õ�ʵ�����ݣ�����Ҳ�в���ԭʼ���ݣ�video������Ȼ����Ƶ�����Ѿ�����õ�ͼ�����ݼ��������ǣ�http://immortal.multicomp.cs.cmu.edu/raw_datasets/processed_data/
4.��CH-SIMS: A Chinese Multimodal Sentiment Analysis Dataset with Fine-grained Annotations of Modality��--�����Ķ�ģ̬������2020�ꡣ�����и���������ı���ͼƬ�����������ݽ��ж�ģ̬�������࣬���б�ǩ����ϸ�£����������յı�ǩ�����и���ģ̬�ı�ǩ��
������ͼ��ʾ�������Լ����ݼ������һ�û�����պ���Ҫ�ҽ��ĸ���ϸ�����ݼ������ǣ� https://github.com/thuiar/MMSA
5.��Iemocap: interactive emotional dyadic motion capture database��--����ģ̬��Ƶ��з�����2008�����ļ�����һ�º���ҪǮ����������ժҪ���Կ���IEMOCAP���ݿ������Լ12Сʱ���������ݣ�������Ƶ���������沿�˶������ı�ת¼��IEMOcap���ݿ��з�ŭ�����֡����ˡ�������ǩ��
���ݼ��ο����CSDN����https://blog.csdn.net/qq_33472146/article/details/90665196 ����Ҫ��дһ����������������£�
���ݼ���ȡ��ʽ��
��Ҫ��һ������������û��������Ƿ����ʼ������ݺܴ��18G���ң�������Chrome���ع��������ء�
������κ����������ϵ�����Anil Ramakrishna (akramakr@usc.edu)
�������ʼ���������ֱ�Ӱ����ݼ��������������ã���Ҫ�������������
6.��GATED MULTIMODAL UNITS FOR INFORMATION FUSION��--����ģ̬Ӱ�����ͷ��ࡿ
�����ݼ���MM-IMDB����Ҫ�ǽ���Ӱ�Ӷ̾�Ķ��࣬����ϲ�磬��ͥ��ȵȣ�����ֲ�����ͼ��ʾ��
���ݼ�MM-IMDB��������https://archive.org/details/mmimdb
��2��.��ģ̬�ʴ����ݼ�
һ��˫ģ̬��һ�����ı�+ͼƬ��
�� Making the v in vqa matter: Elevating the role of image understanding in visual question answering��--����ģ̬�ʴ�2017�ꡣ��������VQA���ݼ�������ԭʼ��ͼƬ���ʴ��ı��ȸ������ԡ����ǼĿ���ͨ��word2vec����Glove����bert��ȡ�ı���embedding��ͨ��Resnet����ȡͼƬ��feature��ͼƬ����ͻش���������ͨ����Ӧ��id����ϵ
���ݼ�����������https://visualqa.org/download.html
��3��.��ģ̬����(ƥ��)���ݼ�
һ��˫ģ̬��һ�����ı�+ͼ��
1.��Microsoft COCO Captions Data Collection and Evaluation Server��--����ģ̬ͼƬ��Ļ��2015�ꡣ���ĸ������Ǿ����MS COCO���ݼ������ڻ��ڹ㷺ʹ�ã��ҿ�21���������Ȼ����������ݼ����ܳ��������ݼ��ϴ���Ƶ���CV��������ݼ�����עһ����Ϊ5�ࣺĿ����⣬�ؼ����⣬ʵ���ָȫ���ָ��Լ�ͼƬ��ע��ǰ���ĸ�����CV����ģ�����Ȥ��ͬѧ������һ�£��Ķ�ģ̬����ֻ��Ҫ���һ������Ȼ�����Ҫͨ��Ŀ���⸨����ģ̬�����ȵȷ���ǰ�漸����עҲ�����õġ��ģ�����������Ҫ����ͼƬ����Ļ����ģ̬������ע��ÿ��ͼƬ��Ӧ5����Ļ��������������ģ̬ƥ��֮����������ݼ�����2014�귢�����Լ�2017�귢���ģ�ÿ�����г�����ʮ����ͼƬ�ı�ע��ͼƬ��������ԭʼͼƬ����ע�ǻ���JSON�ļ������ģ�Ҳ��ԭʼ���ı����ݣ�����ֻҪд��������Ļ��ȡ�����Ϳ����ˣ���Ļ��ͼƬ֮����id��Ӧ���dz����㡣
���ݼ������ǣ�Common Objects in Context
2.��Nus-wide: A real-world web image database from national university of singapore.��--����ģ̬ͼƬ��Ļƥ�������2009�꣬���ݼ�����269648��ͼƬ��ÿ��ͼƬ����81����ʵ�ı�ǩ�Լ�100���ı�ע�͡����в�����Ǵ�ſ���һ�£�����ֱ����ͼƬ��������Ҳ��û��ԭʼͼƬ��������ĵķ�����Embedding֮�Ͽ���������һ�ԡ�
���ݼ�������:https://lms.comp.nus.edu.sg/wp-content/uploads/2019/research/nuswide/NUS-WIDE.html
����ʹ������������һЩ���ӣ���Ϊ������feature�������Ҿ�û���ˡ����ݼ���ʹ�ÿ��Բο�������ͣ�д�ĺ���ϸ:NUS_WIDE���ݿ�����_LeeWei-CSDN����_nuswide���ݼ�
3.��Flickr30k Entities: Collecting Region-to-Phrase Correspondences for Richer Image-to-Sentence Models��--����ģ̬ͼƬ��Ļƥ�������Flickr30k���ݼ���������31783��ͼ���Լ�158915���ı�ע�ͣ����Կ�����MS COCOһ��һ��ͼƬ��Ӧ5��ע�͡�ֻ����ͼƬ�е�С��ֻ��3���š�����ʹ�ò�����Բο��������:https://blog.csdn.net/gaoyueace/article/details/80564642
���ݼ�������http://shannon.cs.illinois.edu/DenotationGraph/�����������ȡ���ص�ַhttp://shannon.cs.illinois.edu/DenotationGraph/data/index.html�����Ǻ����Ǻ��ȶ���
Ҳ����ֱ��������ٶ��Ƶģ�https://pan.baidu.com/s/1Z4tyzFfbMSkQkjcuTwG5UQ����ȡ���ǣ�bk9l��������������Ч�������ļ����ģ�һ��ͼƬ��һ����Ļ��ͨ��ͼƬid���ж�Ӧ��
��Ӧ��Flickr30k 3����ͼƬ����һ��С�汾Flickr8k��ֻ��8ǧ��ͼƬ��
���ݼ�������:https://pan.baidu.com/s/1PWuBlzLK2bFqkRbaBTqAuw
��ȡ��:txnd
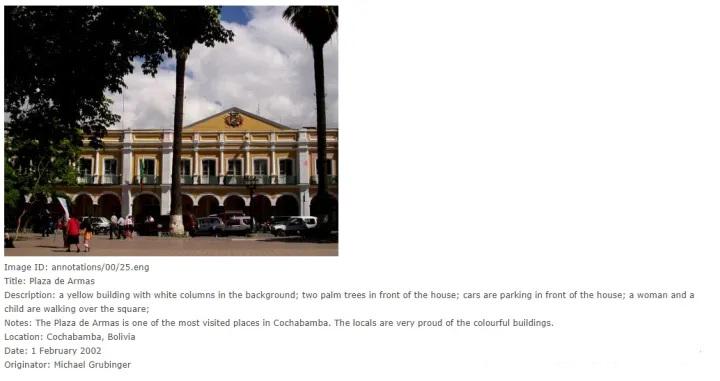
��The IAPR Benchmark: A New Evaluation Resource for Visual Information Systems��--����ģ̬ͼƬ��Ļƥ�������IAPR TC-12���ݼ�������20,000�Ŵ������������ľ�̬��Ȼͼ�������ֲ�ͬ�ľ�̬��Ȼͼ����档�������ͬ�˶��Ͷ�������Ƭ�����������С��羰�͵�����������������������Ƭ��ʹ����������(Ӣ��������������)������ע�͡�
���������ǣ�http://thomas.deselaers.de/publications/papers/grubinger_lrec06.pdf
���ݼ�������:https://www.imageclef.org/photodata
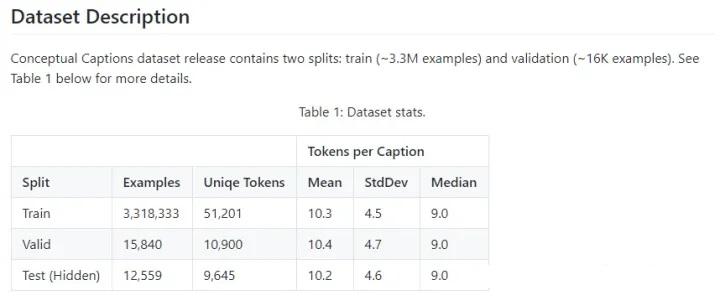
��Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning��--����ģ̬������2018�ꡣ�ϴ�Ķ�ģ̬���ݼ�����������300����ͼƬ�Լ���Ӧ���ı��������������ڶ�ģ̬Ԥѵ��(�������Ǹо������ۣ�����ģ̬������ͼƬ����������ģ̬�ı�ע����̫��ʱ������)����ͼ��ʾ��
���ݼ���ַ:https://github.com/google-research-datasets/conceptual-captions
���ĵ�ַ:https://www.aclweb.org/anthology/P18-1238.pdf
6.��WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training��--����ģ̬���� 2021�����ķ����˳������͵������ı�ͼƬƥ�����ݼ� RUC-CAS-WenLan ����Ԥѵ�������ݼ���ģ��3000��ԡ�ͬʱ����Ҳ�����˴������Ķ�ģ̬����Ԥѵ��ģ�͡�
ģ�ʹ����Լ����ݼ��������������£�https://github.com/BAAI-WuDao/BriVl
���ĵ�ַ��https://arxiv.org/abs/2103.06561
��4����ģ̬�������ݼ�
һ����ģ̬(�ı���ͼ�������)
1.��How2: A Large-scale Dataset for Multimodal Language Understanding��--����ģ̬�Զ�����ʶ�𡢶�ģ̬�������롢�����ı����롢��ģ̬�ܽ�(Summarization)��
How2 ��һ�����ģ�Ķ�ģ̬���ݼ���������80000����ƵƬ��(Լ2000Сʱ)�ĸ�������Ĵ��ͽ�ѧ��Ƶ���ݼ���ʹ�õ��ʼ����ʱ�����Ӣ����Ļ�� ���˶�ģ̬֮�⣬How2Ҳ�Ƕ����Ե�:��ĻҲ����������롣
���ݼ���������https://github.com/srvk/how2-dataset