这篇教程基于初始残差循环神经网络的乳腺癌组织病理学图像的分类写得很实用,希望能帮到您。
基于初始残差循环神经网络的乳腺癌组织病理学图像的分类(Breast Cancer Classification from Histopathological Images with Inception Recurrent Residual Convolutional Neural Network)
摘要
深度卷积神经网络(DCNN)是最强大和最成功的深度学习方法之一。 DCNNs已经为不同的医学图像模式提供了卓越的性能,包括乳腺癌分类,分割和检测。乳腺癌是影响全球女性的最常见和最危险的癌症之一。在本文中,我们提出了一种使用初始残差循环神经网络(IRRCNN)模型进行乳腺癌分类的方法。 IRRCNN是一个强大的深度卷机神经网络(DCNN)模型,结合了Inception Network (Inception-v4),残差网络(ResNet)和循环卷积神经网络(RCNN)的优势。 IRRCNN针对对象识别任务显示出优于等效的初始网络,残差网络和RCNN的性能。在本文中,IRRCNN方法应用于两个公开可用的数据集上的乳腺癌分类,包括BreakHis和乳腺癌(BC)分类挑战2015。实验结果基于补丁的图像级别和患者级别分类与现有机器学习和基于深度学习的方法相比较。与两种数据集的现有方法相比,IRRCNN模型在灵敏度,曲线下面积(AUC),ROC曲线和全局精度方面提供了卓越的分类性能。
关键词 深度学习 DCNN IRRCNN 计算病理学 医学影像 乳腺癌识别
Introduction
如今,癌症是全世界发病率和死亡率的主要原因之一。大约有1450万人因癌症而死亡,估计到2030年这个数字将超过2800万。根据美国癌症协会(ACS)在美国的一项研究,死于乳腺癌的人数约占所有癌症死亡总人数的14%(2017年共计41,000人),乳腺癌是女性患者继肺癌和支气管癌死亡的第二大原因。此外,乳腺癌占所有新发现的癌症病例的30%。乳腺癌是美国女性中最常诊断的癌症。在诊断乳腺癌时,进行活组织检查,然后再进行显微图像分析[1]。乳房组织活检允许病理学家在组织学上访问乳房组织的微观水平结构和组件。病理学家通过这些组织学图像区分正常组织,非恶性(良性)组织和恶性病变。然后使用得到的信息进行预后评估[2]。
良性病变是指乳腺实质正常组织的变化,与恶性肿瘤的进展无关。存在两种不同的癌组织类型,包括原位癌、浸润性癌。原位组织类型是指包含在乳腺导管 - 小叶内的组织。另一方面,浸润性癌细胞扩散到乳腺导管 - 小叶结构之外。在专家进行视觉分析之前,活组织检查期间收集的组织样本通常用苏木精和伊红(H&E)染色。在诊断过程中,受影响的区域由全切片组织扫描确定[3]。此外,病理学家用不同的放大因子分析来自活组织检查的组织样本的显微图像。如今,为了产生正确的诊断,病理学家考虑图像中的不同特征,包括图案,纹理和不同的形态特征[4]。分析具有不同放大系数的图像需要对每个图像进行整体平移,缩放,聚焦和扫描。这个过程非常耗时且令人厌烦的;因此,这种手动过程有时会导致诊断乳腺癌的诊断不准确。由于数字成像技术在过去十年中的进步,不同的计算机视觉和机器学习技术已应用于分析微观分辨率下的病理图像[4,5]。这些方法可以帮助自动化与诊断系统中的病理工作流程相关的一些任务。然而,在临床实践中使用有效且稳健的图像处理算法是必要的。不幸的是,传统方法无法满足期望。因此,我们基于组织学图像的自动乳腺癌检测的实际应用仍然有一定的距离[5]。
然而,深度学习(DL)的最新发展已经在计算机视觉和图像处理,语音识别和自然语言理解领域的不同识别任务中具有最先进的性能[6]。 这些方法已应用于医学图像的不同模式,包括病理成像,在分类,分割和检测方面具有优越的性能[7]。在某些情况下,基于深度学习的系统已成为病理学家和医生临床实践工作流程的一部分。一些例子包括用于皮肤癌检测的皮肤科医生级表现,糖尿病性视网膜病变,用于分析脑肿瘤和阿尔茨海默病的神经成像,肺癌检测以及乳腺癌检测和分类[7]。尽管这些方法在医学成像方面取得了巨大成功,但它们需要大量的有标签的数据,由于多种原因,这些数据在该应用领域仍然无法获得。最重要的是,它需要很多专业知识来注释非常昂贵的数据集。在本文中,我们使用IRRCNN模型提出了一种基于深度学习的乳腺癌识别系统方法,该模型使用BreakHis和Breast Cancer Classification Challenge 2015数据集进行评估。本文的贡献总结如下:
1.使用IRRCNN模型成功地将放大因子不变的二分类和多分类乳腺癌分类。
2.对最近公布的乳腺癌组织病理学数据集(如BreakHis数据集)进行了实验,我们用不同的放大倍数评估了图像和患者水平的数据(包括×40,×100,×200和×400)。
3.针对BreakHis和2015年乳腺癌分类挑战数据集执行了 image-based和patch-based的评估。
4.将实验结果与最近提出的深度学习和机器学习方法进行比较。与现有的乳腺癌分类算法相比,我们提出的模型具有优越的性能。
本文的结构如下:“Related Works”部分讨论相关工作。 在“IIRRCNN Model for Breast Cancer Recognition.”中讨论IRRCNN模型的体系结构。“Experimental Results and Discussion”解释了数据集,实验设置和结果。 最后,在“Conclusion”中给出结论和未来方向。
Related Works
在过去十年中,从组织学图像中对乳腺癌(BC)识别做出了重大努力,其中大多数的努力是使用计算机辅助诊断(CAD)对两种基本类型的乳腺癌(良性和恶性)进行分类。在深度学习革命之前,使用包括支持向量机(SVM),主成分分析(PCA)和随机森林(RF)在内的机器学习方法来研究采用尺度不变特征转换(SIFT)、局部二值模式(LBP)、局部相位量化(LPQ)、灰度共生矩阵(GLCM)、阈值邻接统计量(TAS)、无参数TAS(PFTAS)等方法提取特征。 2016年,一个非常受欢迎的乳腺癌分类问题的数据库发布,并且一个研究小组报告了利用SVM和PFTAS特征进行患者级别分析的最高准确率大约为85.1%[8]。另一项工作发表于2013年,其中使用不同的算法(包括K均值,模糊C均值,竞争学习神经网络和高斯混合模型)对来自50名患者的500个样本的数据集进行细胞核分类。据报道,二分类类(良性与恶性)的准确性从96%到100%不等[9]。
基于神经网络(NN)和SVM的乳腺癌识别系统于2013年发布,由92个样本组成的数据集的识别准确度为94%[10]。另一种方法是基于级联拒绝选项(base on cascading with a rejection option )提出的,该选项在以色列理工学院的361个样本的数据集上进行了测试,分类准确度大约为97%的[11]。在大多数情况下,该领域的研究是使用来自主要私人数据集的极少数样本进行的。最近,发表了一项关于乳腺癌检测和分类的组织学图像分析的调查,该调查清楚地描述了不同公共可用注释数据集的二元性和局限性[12]。已经提出了一种有效的框架,其具有颜色纹理特征和使用投票技术的多个分类器,患者级别乳腺癌分类的平均识别率约为87.53%。该系统使用SVM,决策树(DT),最近邻分类器(NNC),判别分析(DA)和集合分类器。在2017年之前,该系统实现了所有基于机器学习的方法的最佳识别精度[13]。
此外,许多文章已经发表使用深度学习方法讨论乳腺癌识别,其中卷积神经网络的变体用于分类。其中一些使用BreakHis数据集进行实验。在2016年,独立放大倍数的乳腺癌分类是基于CNN提出的,其使用不同大小的卷积核(7×7,5×5和3×3)。他们用CNN和多任务CNN(MTCNN)模型形成患者级别的乳腺癌分类,识别率为83.25%[14]。在同一年,另一项工作是基于类似于AlexNet的模型发布的不同的融合技术(包括sum,product和max)用于乳腺癌的图像和患者级分类。本文报告平均识别率为90%和85.6%用图像和患者水平的最大融合方法分类[15]。另一个深度学习为基础方法于2017年出版。在这项工作中,经过预先培训CNN用于提取特征向量,最终,特征向量用作分类器的输入。这个方法被称为DeCAF并实现了识别患者水平和图像水平分别为86.3%和84.2%[16]。
在2017年,CNN模型用于来自另一个具有挑战性的数据集的H&E染色的分类乳房活检图像[17]。图像四个不同类别:正常组织,良性病变,原位癌和浸润性癌。图像也被分为两类;癌(包括正常组织和良性组织)和非癌症(包括原位和浸润癌类)。工作[17]提供了基于图像和基于图像块的结果评价。使用基于CNN的方法在2015乳腺癌分类挑战的数据集上进行四分类,近似识别准确率为77.8%,以及二分类达到了约83.3%。最近,乳腺癌病理学图像多分类问题使用称为CSDCNN的结构化深度学习模型。这种新的深度学习架构比其他基于BreakHis数据集的机器学习方法或者深度学习方法表现出色。这个模型显示图像级和患者级分类的最先进性能。已报道乳腺癌分类患者级别的准确率平均为93.2%[18]。 在2017年,不同的SVM技术应用于乳腺癌的识别; 对于具有×40放大倍数的数据,使用自适应稀疏SVM(ASSVM)准确度达到了 94.97%[19]。 但是,我们的工作提出了一个应用新的深度学习模型称为初始循环残差卷积神经网络(IRRCNN)对BreakHis和2015年乳腺癌分类挑战数据集进行了应用。
IRRCNN Model for Breast Cancer Recognition
深度学习方法在有足够标记数据的情况下取得了巨大的成功,而且在过去的几年中,有几个先进的深度学习方法已经在计算机视觉和医学图像领域中显示了不同形式的最新性能[6,7]。 IRRCNN [20,21]是基于inception[22],残差网络[23]和RCNN架构[24]的改进混合DCNN架构中的一个。该模型的主要优点是,与包括inception,RCNN和残差网络的等效可替代的深度学习方法相比,它使用相同或更少数量的网络参数提供更好的识别性能。在该模型中,使用Inception-v4模型的初始 - 残差单元[2]。 IRRCNN已经与等效的初始 - 残差网络相比表现出了更好的性能[20] 。IRRCNN模型由堆栈组成,包括初始循环残差单元(IRRU)和转换单元。整个模型如图1所示。整个模型由几个卷积层,IRRUs, transition blocks和输出层的softmax。IRRU的图示如图2所示。

Fig1:使用IRRCNN模型的乳腺癌识别的实现图。 该图的上半部分显示了用于训练系统的步骤,该图的下半部分显示了使用训练模型的测试阶段。 使用许多不同的性能指标评估这些结果

Fig.2 图中显示初始残差循环单元(IRRU),包括由连接合并的初始单元和循环卷积层,以及残差单位(输入要素与初始单位输出的总和可以在输出块之间看到)
IRRCNN架构中最重要的单元是IRRU,包括循环卷积层(RCLs),inception单元和残差层。输入被送入输入层,然后通过循环卷积层(RCLs)的inception单位传递应用,最后,inception单位的输出是增加了IRRU的输入。循环卷积对inception单元的不同尺寸的内核进行计算。由于循环结构在卷积层内,当前的输出步骤被添加到前一时间步长的输出。然后将当前时间步长的输出用作下一步的输入。针对所考虑的时间步长执行相同的操作。例如,在这里,t = 2(0~2)表示一个前馈卷积沿IRRU中包含2个RCL。 关于不同时间步长的RCL操作(t = 2(0~2)和t = 3(0~3))如图2所示。由于IRRU中的残差连通性,输入和输出尺寸不会改变。IRRU只是执行特征映射关于时间步长的累积。 因此,更好的特征表示确保了这一点,并且该系统在具有相同数量的网络参数的情况下获得了极高的准确度。
RCL( recurrent convolutional layers )的操作是根据[20]中的IRRCNN表示的离散时间步长执行的。 让我们考虑IRRCNN块的第l层中的xl输入样本,以及来自RCL中第k个特征映射中的输入样本的unit(i,j)。另外,让我们假设网络 O i j k l O^l_ {ijk} Oijkl的输出是在时间步长t。 给定此信息,输出可以表示为Eq1(1)
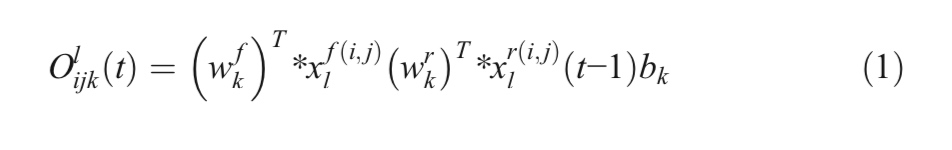
这里, x l f ( i , j ) ( t ) x^{f(i,j)}_ {l}(t) xlf(i,j)(t)和 x l r ( i , j ) ( t − 1 ) x^{r(i,j)}_ {l}(t-1) xlr(i,j)(t−1)分别是标准卷积层和lth层的RCL的输入。 w k f w^f_ k wkf和 w k r w^r_ k wkr值分别是标准卷积层和第k个特征映射的RCL的权重, b k b_ k bk是偏差。
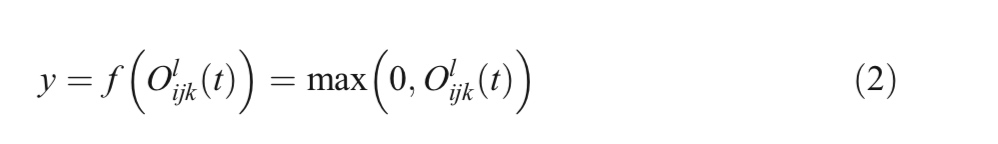
在等式(2),f是标准线性整流单元(ReLU)激活函数。我们还在以下实验中用指数线性单位(ELU)激活函数探索了该模型的性能。不同大小的卷积核和平均池化层的初始单元的输出y分别定义为 y 1 ∗ 1 ( x ) y_ {1*1}(x) y1∗1(x), y 3 ∗ 3 ( x ) y_ {3*3}(x) y3∗3(x)和 y 1 ∗ 1 p ( x ) y^{p}_ {1*1}(x) y1∗1p(x)。 初始循环卷积神经网络(IRCNN)单元的最终输出定义为 F ( F_ ( F(xl , , ,wl ) ) )可以用公式3表示。
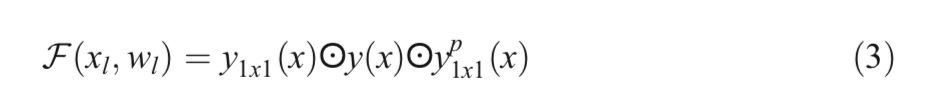
这里,⨀表示关于通道或特征图的级联操作。 然后将IRCNN单元的输出与IRRCNN块的输入相加。 IRRCNN块的残差操作可以用等式(4)表示。

在等式(4), x l + 1 x_ {l+1} xl+1表示紧接的下一个转换块的输入, x l x_ {l} xl表示IRRCNN块的输入样本,wl表示第l个IRRCNN块的卷积核权重,并且 F ( F_ ( F(xl , , ,wl ) ) )表示IRCNN单元的第l层的输出。 然而,残差单元的特征图的数量和特征图的维度与图2中所示的IRRCNN单元中的相同。批量归一化应用于IRRU的输出[25]。 最终,该IRRU的输出被传送到下一个过渡单元的输入。
在转换单元中,根据模型中转换单元的位置,执行包括卷积,池化和dropout在内的不同操作。 初始单元包含在转换单元中。 下采样操作在转换单元中执行,其中我们使用3×3图像块和2×2步长执行最大池化操作。 非重叠最大池化操作对模型正则化有负面影响; 因此,我们使用重叠采样最大池化来规范网络,这在培训深层网络架构时非常重要[22]。 池化层的后期使用有助于增加网络中特征的非线性,因为这导致更高维度的特征图通过网络中的卷积层。 我们在模型中使用了两个特殊的池化层,其中包含三个IRRCNN单元和一个用于此实现的转换单元。
在NiN [26]和Squeeze Net [27]模型的启发下,我们在此实现中仅使用了1×1和3×3卷积滤波器。 这也有助于将网络参数的数量保持在最低限度。 添加1×1滤波器的好处是它有助于增加决策功能的非线性,而不会对卷积层产生任何影响。 由于输入和输出特征的大小在IRRCNN单元中没有变化,因此结果只是在同一维度上的线性投影,并且非线性被添加到RELU和ELU激活功能。 我们在转换块中的每个卷积层之后使用0.5dropout。 最后,我们在架构的最后使用了softmax或归一化指数函数层。 对于输入样本x,权重向量W和K个不同的线性函数,可以为第i个类定义softmax操作,如等式(5)中所示。

通过对不同基准数据集的一系列实验,对提出的IRRCNN模型进行了研究,并对几种不同模型的结果进行了比较。
在卷积块中用不同数量的卷积层评估IRRCNN模型,并且相对于时间步长t确定层数。 在这些实现中,t = 2指的是包含一个前向卷积后跟两个RCT的RCL块[20]。 对于两个乳腺癌识别数据集,我们使用一个开头有两个卷积层的模型,四个IRCNN块,后面是过渡块,一个完全连接的层,以及模型末端的softmax层。 对于这个模型,我们考虑了前三个卷积层的32和64个特征图,我们分别在第一个,第二个,第三个和第四个IRRCNN块中使用了128,256,512和1024个特征图。 批量归一化(BN)用于每个IRCNN块[25]。 该模型包含大约930万个网络参数。
Experimental Results and Discussion
Experimental Setup
为了证明IRRCNN模型的性能,我们在两个不同的乳腺癌数据集上测试了它们:BreakHis数据集和2015年乳腺癌分类挑战数据集,用于二元和多元乳腺癌分类。以下段落详细讨论了这两个数据集。对于这个实现,Keras(https://github.com/keras-team/keras.git)和Tensor Flow [28]框架在具有56G RAM和NVIDIA GEFORCE GTX-980 Ti的单GPU机器上使用。我们在这个实现中考虑了病理图像分析的不同标准。在大多数情况下,全视野数字图像切片(WSI)的尺寸大于典型的数字图像。此外,使用不同的放大倍数获取病理图像。在某些情况下,图像尺寸大于2000×2000像素。然而,在这种情况下,图像通常作为几个补丁馈送到模型。有两种常用的方法用于补丁选择,其中一种是随机裁剪方法,其中从输入样本中的随机位置裁剪补丁。另一种方法是使用顺序和非重叠补丁。我们在这个实现中考虑了两种方法。
Datasets
BreakHis
BreakHis数据集是公开的,通常用于研究乳腺癌分类问题。该数据集包含7909个样本,每个样本属于两个主要类别:良性或恶性。良性子集包含2440个样本,恶性子集包含5429个样本。样本来自82名患者,具有不同的放大倍数,包括×40,×100,×200和×400。具有×400放大系数的一些示例图像如图3所示。每个类具有四个子类;四种类型的良性癌症是腺病(A),纤维腺瘤(F),管状腺瘤(TA)和叶状肿瘤(PT)。恶性肿瘤的四个种类是导管癌(DC),小叶癌(LC),粘液癌(MC)和乳头状癌(PC)。该数据集的统计数据在表1中给出。在该实验中,我们使用70%的样本进行训练,30%的样品进行测试,根据[8,12,18]的工作。为了保证在测试新患者时分类任务能有成功执行,我们保证在测试期间不使用进行训练的患者。根据[12,18]中的实验设计,在成功完成五项实验后,我们报告了平均准确度。

对于数据增强,我们使用不同的增强技术(包括旋转,翻转,剪切和平移)从每个单个输入样本生成21个样本。 因此,样本总数增加了21倍。 例如,在40倍放大率下可用的图像总数现在为41,895。 我们生成了43,401;42273; 来自原始样本的38,220个样本分别为×100,×200和×400放大因子。 因此,所有放大因子的增强样本总数为166,068。 我们评估了二元和多元乳腺癌识别的图像水平和患者水平表现。
BC Classification Challenge 2015
该数据集由极高分辨率(2048×1536)的数字病理图像组成,这些图像是2015年发布的用于乳腺癌分类的注释H&E染色图像[17,29]。 该数据集总共包含249个样本,其中229个样本被分离用于训练,剩余样本被考虑用于[17]中的工作。 这些图像由两位病理学家进行标记,并且在没有指定感兴趣区域的情况下考虑了整体背景。 每个图像分配以下四种类别之一:(a)正常组织,(b)良性(c),原位和(d)浸润性癌。 如图4所示显示四种不同类型乳腺癌样本图像。每个类有大约60个样本,它们解决了分类任务的类不平衡问题。

在该实现中,针对二分类和多分类的乳腺癌分类问题评估模型。在二分类的情况下,正常组织和良性亚群被认为是第一类,原位癌和浸润性癌亚群被认为是第二类的一部分。根据数据集的视觉分析,观察到核半径范围为3至11个像素(或1.26至4.62μm)。因此,尺寸为128×128像素的图像块能够覆盖足够的组织结构(根据[17]中的实验)。我们使用图像方式和图像块方式评估进行了实验。对于图像分类,我们使用了三种不同的方法:首先,我们将输入样本的大小调整为128×128像素,这显着降低了样本中包含的信息。其次,将不同的数据增强技术应用于调整大小的图像,为每个样本生成20个不同的增强样本。第三,裁剪200个随机图像块以创建用于训练和测试模型的图像块数据库。使用Winner Take All(WTA)方法生成结果,其中最终类是基于提名最大补丁数的类确定的。图像块的标签被认为与原始图像具有相同的类别标签。另一方面,使用图像块的方法,首先,从原始输入样本裁剪128×128像素的图像块中心。其次,将增强技术应用于图像(每个样本生成20个增强样本),并从增强样本中剪切中心斑块。第三,我们使用200个随机选择的图像块评估模型,其中单个图像的尺寸为128×128像素。表2给出了图像方式和图像块方式的统计数据。
Data Augmentation
在每个数据集中,我们应用了不同的数据增强技术,包括顺时针旋转40度,宽度偏移系数为0.2,高度偏移系数为0.2,剪切系数为0.2,变焦范围为0.2,水平翻转和垂直翻转。 图5显示了一些示例图像以及四种不同数据类的不同增强样本。 从图5中可以看出,噪声已被添加到图像的某些部分。 因此,我们仅使用增强样本的中心补丁来评估我们的方法。 针对图6中的两个不同输入样本示出了下采样和中心图像块。


Training Methodology(训练方法)
在第一个实验中,我们使用随机梯度下降(SGD)优化函数对IRRCNN架构进行了总共150个时期的训练。 在50个时期之后,学习率降低了10倍。我们将动量设置为0.9,并且基于初始学习率和50个时期的数量来计算衰减。
Results and Discussion
在这项工作中,我们为两个不同数据集上的二分类和多分类问题引入了自动乳腺癌分类。 在多分类乳腺癌分类问题的情况下,在该实现中考虑了四个和八个类。 我们为两个数据集实现了最先进的测试精度。
Results for BreakHis
根据[12,18]的工作,我们考虑了评估IRRCNN模型性能的两个标准。我们考虑了(1)图像水平和(2)患者水平的性能,用于八种类型乳腺癌的多分类,属于两种主要类型(良性或恶性)。此外,我们还评估了良性和恶性类型的二分类系统的性能。对于图像级分类,我们没有考虑与患者有关的图像。对于该实验,图像被组织成八个类,并且图像包含×40,×100,×200或×400的放大因子。在这种情况下,性能通过不同的评估指标来衡量。考虑两种不同的性能标准来评估IRRCNN深度学习方法的性能,如[18]。首先,我们考虑了患者级别的绩效分析,其中患者总数被定义为Nnp;相关患者(P)的乳腺癌图像数量定义为Nncp。用于患者的正确分类的图像的数量表示为Ntp。等式(6)定义患者得分(Ps)。

全局患者识别率(Prt)在等式(7)中定义。

我们还计算了IRRCNN方法在图像级别分类方面的表现。 我们将可用于测试的样品总数定义为NT。 正确分类的组织病理学样本定义为NCCT。 图像级识别率(Irt)用公式(8)表示。

IRRCNN乳腺癌分类模型的训练和验证准确度如图7所示。从该图可以看出,样本的放大系数对训练和测试精度有影响。 我们使用×100的放大倍数实现了最佳的训练精度,并且放大倍数为×200的数据的训练精度非常接近。

乳腺癌的多分类和二分类的测试精度分别如表3和表4所示。 这些表格显示了在BreakHis数据集上有和没有数据增强的图像级别和患者级别分析的测试精度。


在图像级评估中,我们分别采集了来自82名患者的×40,×100,×200和×400放大倍数的41,895; 43701; 42273;和38,200的38,220个增强样本。对于每种情况,我们使用随机选择的70%样本进行训练,并使用剩余的30%样本进行验证和测试,根据[8,18]中讨论的实验设置。对于乳腺癌的多分类(8类),放大系数×100达到最高精度,与最近公布的结果[20]相比,五项试验的平均测试精度提高了3.67%。该模型显示×40的平均测试精度为97.95%,与现有方法[18]中所述的最高精度相比,提高了2.15%。对于患者级别的性能分析,我们根据[18]中的实验方法,考虑了共计82名患者的21名患者用作测试。我们分别在乳腺癌八分类和二分类中获得了96.84%和97.65%的平均最高测试精度,与[18]中所述的最高平均精度相比,测试精度提高了约2.14%和3.75%。
此外,在[15]中使用不同的融合技术(包括总和sum,乘积product和最大值max)分析了乳腺癌识别的性能。 因此,我们将我们提出的方法的性能与[15]中报告的最高准确度进行了比较。 在这两种情况下,与[8,15,18]中现有的基于深度学习的方法相比,基于IRRCNN的方法显示出更高的性能。 用于不同放大因子的所提出方法的ROC曲线下面积如图8所示。

Results for BC Classification Challenge 2015
对于2015 乳腺癌分类挑战数据集,不同方法的训练和验证准确度分别如图9a和b所示。 使用调整大小和增强样本时的实验结果显示出最高的训练和验证准确度,如图9所示。

Patch-Wise分类结果 表5和表6显示了不同基于图像块的方法的实验结果。在表中,对于二分类和多分类情况,增强中心图像块的实验显示最高的测试精度为97.51% 和97.11%。

随机图像块观察到相似的性能,但单中心图像块的实验显示出最低的准确度,二分类的情况为88.7%,多分类的情况为88.12%。
Image-Wise分类结果 表7和表8显示了二分类和多分类情况的图像级别性能的实验结果。从表中可以看出,与仅调整大小的样本相比,具有数据增强的调整大小样本显示出更好的性能。增强的调整大小样本的二分类饰演的测试准确度为99.05%,多分类的测试准确度为98.59%的。对于调整大小的样本,观察到最低的测试精度。


此外,我们评估了基于图像的性能,其中20个随机样本从四个不同的类别(每个类别5个样本)中分离出来。 我们使用来自229个样本(每个样本200个图像块)的随机选择的样本训练模型,并且对来自20个样本(每个样本200个图像块)的随机选择的样本进行了验证和测试。 最后,我们将WTA技术应用于模型产生的结果上,最终分类是根据指定的图像块的最大数量的类来确定的。 对于二分类和多分类乳腺癌识别,我们使用WTA技术实现了此评估的100%测试准确度。
Analysis and Comparison of Results(结果分析和比较)
BreakHis Dataset
大多数先前的研究报告了良性和恶性病例的分类结果[8,15,18]。然而,一些研究已经显示了乳腺癌多分类问题的结果[15,18]。已经针对×40,×100,×200和×400的放大因子的样品的二分类和多分类问题进行了这些实验。基于BreakHis数据集,应用了不同的基于特征的方法,包括PFTAS,GLCM,QDA,SVM,1-NN和RP,并且报告了患者级别分析的准确度约为85%[8]。此外,AlexNet被用于不同放大倍数的乳腺癌二分类的识别,图像级别的最高识别准确率为95.6±4.8%,患者级别的识别准确度为90.0±6.7%[15]。此外,报告的良性和恶性乳腺癌分类的最高准确度为图像级别96.9±1.9%和患者级别97.1±2.8%[18]。对于乳腺癌多分类,图像级别和患者级别所达到的最佳测试准确度分别为93.9±1.9%和94.7±3.9%[18]。
或者,在这项工作中,我们为图像和患者级别的良性和恶性乳腺癌分类实现了97.95±1.07%和97.65±1.20%的测试准确度。 因此,我们针对[18]中图像和患者水平分析报告的最高准确度,在平均性能方面取得了1.05%和0.55%的改善。 此外,我们提出的IRRCNN模型在图像水平和患者水平分别对多级乳腺癌分类产生了97.57±0.89%和96.84±1.13%的测试准确度。 与最新报告的性能相比,这些结果的平均识别精度提高了3.67%和2.14%[18]。
BC Classification Challenge Dataset 2015
2014年,Crus-Roa等人。提出了一种基于CNN的图像块输入的分类方法,他们报告的灵敏度(sensitivity)为79.6%[30]。 在2017年针对同一数据集中的四种不同类型的乳腺癌报告了最高准确度,并且针对乳腺癌的二分类和多分类问题进行了实验。由于数据维度很高(2040×1536像素),因此对乳腺癌的二分类和多分类进行了图像级别和图像块级别的分析。采用CNN方法,报告了图像级别分类的最佳结果分别为四分类77.8%和二分类83.3%的测试精度[17]。相反,我们基于IRRCNN模型进行了一项实验,考虑了不同的标准,包括调整大小,裁剪,随机图像块和不同的数据增强技术。对于调整大小和增强的样本,我们分别实现了二分类99.05%和多分类98.59%的测试精度。此外,我们将分类模型应用于随机贴片,然后使用Winner Take All方法生成最终结果,该实验实现了100%的测试性能。因此,我们的方法显示了2015年乳腺癌分类挑战数据集中二分类和多类乳腺癌识别的最新性能的显着改善。表9给出了这些实验的计算时间。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zRrfono2-1575438189409)(media/15660063471450/15680175551641.jpg)]

Conclusion
在本文中,我们提出了使用初始残差循环神经网络(IRRCNN)模型对乳腺癌的二分类和多分类识别方法。使用IRRCNN模型在两个不同的基准数据集(BreakHis和2015年乳腺癌分类挑战)上进行实验,并使用不同的性能指标评估性能。通过图像级别,患者级别,基于图像和基于图像块的分析来评估所提出方法的性能。我们已经考虑了不同的标准,例如放大系数,调整大小的样本输入,增强的图像块和样本,以及此实现中基于图像块的分类。对于截至2016年的科学报告中发布的所有结果,所提出的方法在BreakHis数据集的平均识别准确度提高了约3.67%和2.14%。此外,该方法在2015年乳腺癌分类挑战数据集上对于二分类达到了99.05%的测试准确度,对于多分类达到了98.59%的测试准确度,这明显高于其他任何基于CNN方法基于图像和基于图像块的识别性能的方法。我们还使用随机图像块和Winner Take All(WTA)方法评估了所提方法的性能,以实现基于图像的识别,并实现了100%的测试精度。因此,与两种数据集的现有方法相比,实验结果显示了乳腺癌识别的最新测试准确度。
深度学习检测疟疾
轻量级网络 MixNet 论文笔记 |