引言:
Bert模型作为一个强大的双向Transformer模型,已经在NLP领域广泛使用并作为word embeddding 预训练模型深受青睐。Hugging Face的transformers框架包含BERT、GPT、GPT2、ToBERTa、T5等众多模型,同时支持pytorch和tensorflow 2两个框架,本博客主要介绍如何从Hugging Face加载预训练模型及高效使用。
目录
一、 加载Bert预训练模型的常用方法
1.1模型名称加载
1.2模型文件路径加载
二、Bert预训练模型的使用
2.1BertTokenizer的使用
2.2BertModel的使用
一、 加载Bert预训练模型的常用方法
1.1模型名称加载
直接通过在Hugging Face网站中查找对应模型名称,通过 from_pretrain() 函数的运行将预训练模型加载到本地。不足之处是下载速度较慢甚至无法下载。
from transformers import BertTokenizer,BertModel
tokenizer =BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
1.2模型文件路径加载
直接从Hugging Face网站将需要的相关文件下载到本地文件夹,通过from_pretrain()函数传递相对路径/绝对路径参数。在网站搜索栏输入需要加载的模型名称。
https://huggingface.co/ https://huggingface.co/
https://huggingface.co/
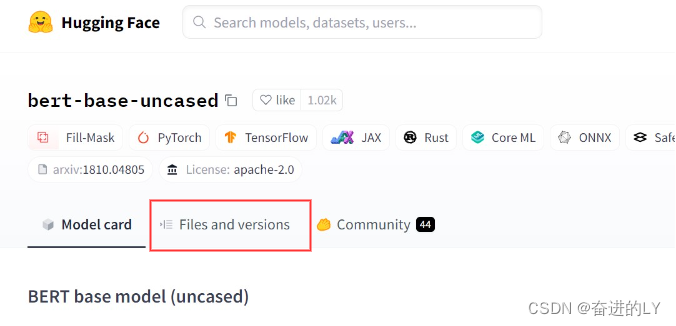
点击Files and versions,选择config.json和vocab.txt文件,若是pytorch框架选择pytorch_model.bin文件,若是tensorflow2.0选择tf_model.h5文件,将三个文件下载到本地计算机中,并放入同一个文件夹下。
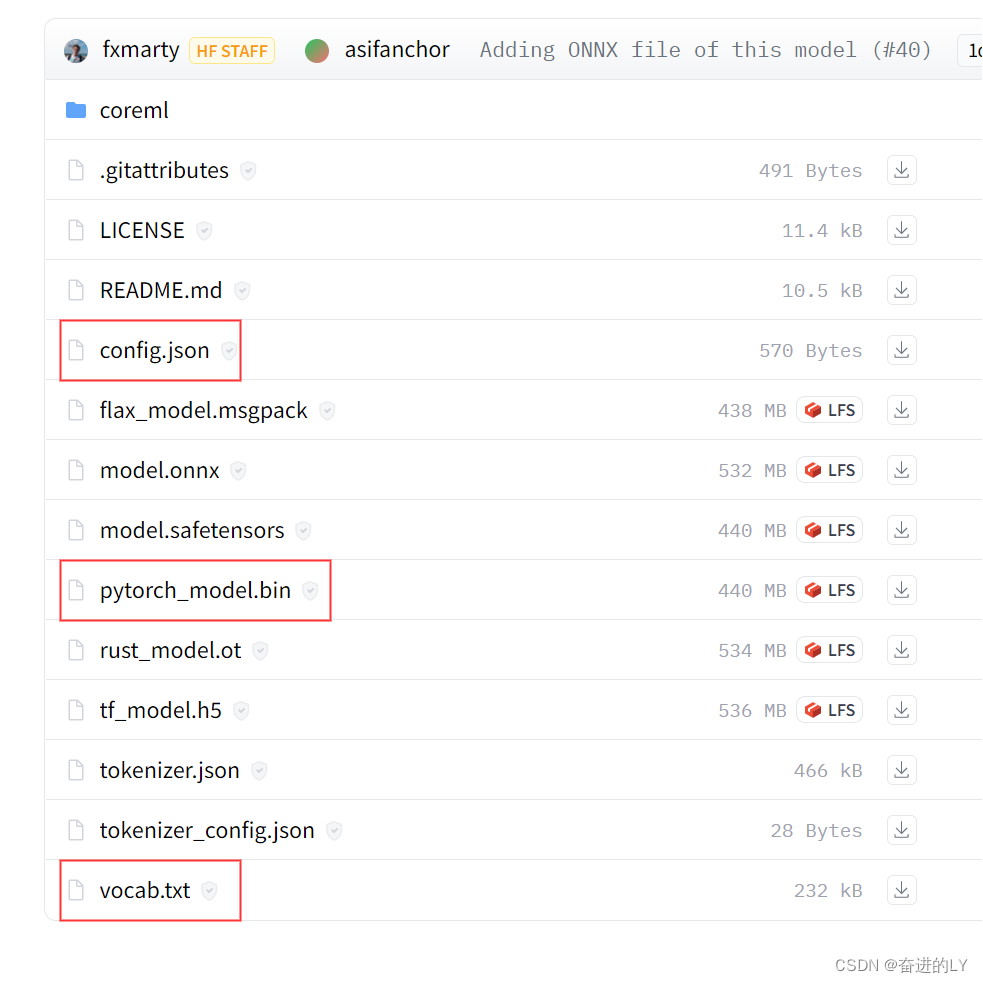
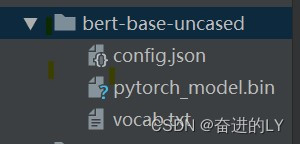
将该文件夹路径作为实参传递给函数from_pretrain,就可以方便快速加载相应的预训练模型。可以在from_pretrain函数中设置参数cache_dir,指向模型缓存路径。
from transformers import BertTokenizer,BertModel
path = './bert-base-uncased'
tokenizer =BertTokenizer.from_pretrained(path)
model = BertModel.from_pretrained(path)
二、Bert预训练模型的使用
2.1BertTokenizer的使用
调用BertTokenizer中的encode方法既然可以完成分词操作也可以对单词进行整数编码,若使用encode_plus方法返回的是一个字典,包括input_ids(整数编码), attention_mask(有单词对应为1,无单词对应为0), token_type_ids(属于同一句话的单词下标相同)。直接使用tokenizer结果与encode_plus相同。
txt = '这是一个美丽的城市'
ckpt = r'.\ConvAdapter\vocab\bert\chinese_roberta_wwm_base_ext_pytorch'
tokenizer =BertTokenizer.from_pretrained(ckpt)
input_ids = tokenizer.encode(txt,max_length=40,add_special_tokens=True,
padding='max_length', truncation=True)
print(input_ids)
2.2BertModel的使用
将input_ids变成tensor后传入model模型中,加载model的from_pretrain函数中有一个参数output_hidden_states为True时,hidden_states显示十二层transformer的每一层输出,为False时hidden_states显示为None。输出结果为字典具体内容可以通过调用vars()函数查看 。根据需求选择自己想要的输出内容。
ckpt = r'.\chinese_roberta_wwm_base_ext_pytorch'
model = BertModel.from_pretrained(ckpt,output_hidden_states=True)
out = model(input_ids,attention_mask=mask)
print(vars(out).keys())
last_hidden_states = out.last_hidden_state
print("last hidden state:",out['last_hidden_state'].shape) #torch.Size([1, 6, 768])
print("pooler_output of classification token:",out['pooler_output'].shape) #[1,768] [CLS]
print("all hidden_states:", len(out.hidden_states))
Reference
1.下载BERT模型到本地,并且加载使用 - 知乎
2.【NLP】手动下载、本地加载BERT预训练权重_bert权重文件下载_sunflower_sara的博客-CSDN博客
3.HuggingFace | 如何下载预训练模型-云海天教程