作者|Frank Andradehttps:// towardsdatascience.com/ 7-nlp-techniques-you-can-easily-implement-with-python-dc0ade1a53c2
自然语言处理(NLP)的重点是使计算机能够理解和处理人类语言。计算机擅长处理结构化数据,如电子表格;然而,我们写或说的很多信息都是非结构化的。
自然语言处理的目标是使计算机能够理解非结构化文本并从中提取有意义的信息。多亏了spaCy和NLTK等开源库,我们只需几行Python代码就可以实现许多NLP技术。
在本文中,我们将学习7种NLP技术的核心概念,以及如何在Python中轻松实现它们。
目录
情绪分析
命名实体识别(NER)
词干化
词形还原
词袋(BoW)
词频逆文档频率(TF-IDF)
Wordcloud
1.情绪分析 情感分析是最流行的NLP技术之一,它涉及到获取一段文本(例如,评论或文档),并确定数据是正面的、负面的还是中性的。它在医疗保健、客户服务、银行等领域有着广泛的应用。
Python实现 对于简单的情况,在Python中,我们可以使用NLTK包中提供的VADER,它可以直接应用于未标记的文本数据。作为一个例子,让我们得到一个电视剧中人物所说台词的所有情感分数。
首先,我们在Kaggle或我的Github上找到一个名为“avatar.csv”的数据集,然后用VADER计算每一行的得分。所有这些都存储在df_character_sentiment数据帧中。
import pandas as pd
import nltk
from nltk.sentiment.vader import SentimentIntensityAnalyzer
# 读取和处理数据
df_avatar = pd.read_csv('avatar.csv', engine='python')
df_avatar_lines = df_avatar.groupby('character').count()
df_avatar_lines = df_avatar_lines.sort_values(by=['character_words'], ascending=False)[:10]
top_character_names = df_avatar_lines.index.values
# 过滤
df_character_sentiment = df_avatar[df_avatar['character'].isin(top_character_names)]
df_character_sentiment = df_character_sentiment[['character', 'character_words']]
# 计算情绪得分
sid = SentimentIntensityAnalyzer()
df_character_sentiment.reset_index(inplace=True, drop=True)
df_character_sentiment[['neg', 'neu', 'pos', 'compound']] = df_character_sentiment['character_words'].apply(sid.polarity_scores).apply(pd.Series)
df_character_sentiment
在下面的df_character_sentiment中,我们可以看到每个句子都会得到一个否定、中立和肯定的分数。
我们甚至可以按字符对分数进行分组,并计算平均值以获得字符的情感分数,然后使用matplotlib库中的水平条形图表示它(这一结果显示在本文中)。
你可以使用更完整的算法,也可以使用机器学习库开发自己的算法。在下面的链接中,有一个关于如何使用sklearn库用Python从头开始创建一个完整的指南。
https:// towardsdatascience.com/ a-beginners-guide-to-text-classification-with-scikit-learn-632357e16f3a
2.命名实体识别(NER) 命名实体识别是一种将文本中的命名实体进行定位和分类的技术,它将文本中的命名实体分为人、组织、地点、时间、数量、货币价值、百分比等类别,用于优化搜索引擎算法、推荐系统、客户支持、内容分类等。
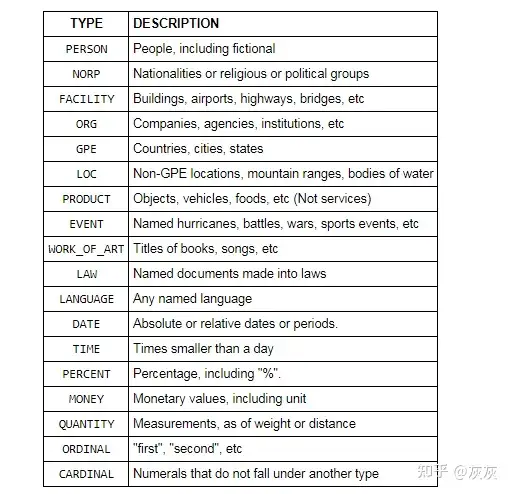
Python实现 在Python中,我们可以使用SpaCy的命名实体识别,它支持以下实体类型。
要查看它的运行情况,我们首先导入spacy,然后创建一个nlp变量来存储en_core_web_sm管道。
这是一个小的英语管道用于训练书面文本(博客,新闻,评论),其中包括词汇,向量,语法和实体。为了找到实体,我们将nlp应用到一个句子中。
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Biden invites Ukrainian president to White House this summer")
print([(X.text, X.label_) for X in doc.ents])
这将打印以下值
[('Biden', 'PERSON'), ('Ukrainian', 'GPE'), ('White House', 'ORG'), ('this summer', 'DATE')]
Spacy发现,“Biden”是一个人,“Ukrainian”是GPE(国家、城市、州),“White House”是一个组织,而“this summer”是一个日期。
3.词干化和词形还原 词干化和词形还原是自然语言处理中两种常用的技术。两者都规范化了一个词,但方式不同。
词干化:把一个词截成它的词干。例如,单词“friends”、“friendship”、“friendships”将被简化为“friend”。词干分析的结果可能是不存在的单词。
词形还原:与词干分析技术不同,词形还原查找字典中的单词,而不是截断原始单词。词形还原算法提取每个单词的正确词形,因此它们通常需要语言词典才能正确地对每个单词进行分类。
这两种技术都被广泛使用,你应该根据项目的目标明智地选择它们。词形还原处理速度比词干化慢,所以如果准确性不是项目的目标而是速度,那么词干化是合适的方法;然而。如果准确性是至关重要的,那么就考虑使用词形还原。
Python的库NLTK使使用这两种技术变得容易。让我们看看它的实际效果。
Python实现(词干) 对于英语,nltk中有两个流行的库—Porter Stemmer和Lancaster Stemmer。
from nltk.stem import PorterStemmer
from nltk.stem import LancasterStemmer
# PorterStemmer
porter = PorterStemmer()
# LancasterStemmer
lancaster = LancasterStemmer()
print(porter.stem("friendship"))
print(lancaster.stem("friendship"))
PorterStemmer算法不遵循语言学,而是针对不同情况的5条规则,这些规则被分阶段应用来生成词干。print(porter.stem(" friendship "))代码将打印friendship这个词
LancasterStemmer很简单,但可能会出现由于把词缀删除得非常过度。这导致词干可能没有意义。print(lancaster.stem(“friendship”))代码将打印单词friend。
你可以尝试任何其他单词来查看这两种算法的不同之处。对于其他语言,可以从nltk.stem导入snowballsteme
Python实现(Lemmatization) 我们将再次使用NLTK,但这次我们导入WordNetLemmatizer,如下面的代码所示。
from nltk import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
words = ['articles', 'friendship', 'studies', 'phones']
for word in words:
print(lemmatizer.lemmatize(word))
Lemmatization为不同的词性(POS)值生成不同的输出。最常见的词性值有动词(v)、名词(n)、形容词(a)和副词(r)。
lemmatization中的默认POS值是一个名词,因此前面示例中的打印值将是article、friendship、study和phone。
让我们把POS值改为动词(v)。
from nltk import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
words = ['be', 'is', 'are', 'were', 'was']
for word in words:
print(lemmatizer.lemmatize(word, pos='v'))
在本例中,Python将打印单词be。
5.词袋 词袋(BoW)模型是一种将文本转换为固定长度向量的表示方法。这有助于我们将文本表示为数字,以便我们可以将其用于机器学习模型。该模型不关心词序,只关心词频。它在自然语言处理、文献信息检索、文献分类等方面都有应用。
典型的BoW工作流包括清理原始文本、标记化、构建词汇表和生成向量。
Python实现 Python的库sklearn包含一个名为CountVectorizer的工具,它负责大部分的BoW工作流。
让我们用下面两个句子作为例子。
句子1 :“I love writing code in Python. I love Python code”
句子2 :“I hate writing code in Java. I hate Java code”
两个句子都将存储在一个名为text的列表中。然后我们将创建一个数据帧df来存储这个文本列表。
在此之后,我们将启动CountVectorizer(cv)实例,然后对文本数据进行拟合和转换以获得数字表示。这将存储在文档术语矩阵df_dtm中。
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
text = ["I love writing code in Python. I love Python code",
"I hate writing code in Java. I hate Java code"]
df = pd.DataFrame({'review': ['review1', 'review2'], 'text':text})
cv = CountVectorizer(stop_words='english')
cv_matrix = cv.fit_transform(df['text'])
df_dtm = pd.DataFrame(cv_matrix.toarray(),
index=df['review'].values,
columns=cv.get_feature_names())
df_dtm
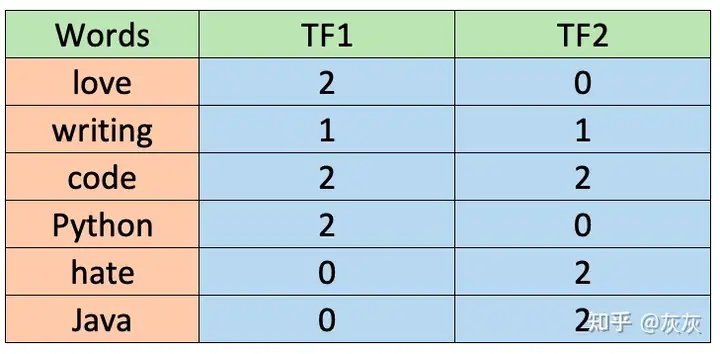
使用存储在df_dtm中的CountVectorizer生成的表示如下图所示。请记住,CountVectorizer不考虑2个字母或更少的单词。
如你所见,矩阵中的数字表示每个单词在每次评论中被提及的次数。像“love”、“hate”和“code”这样的词在本例中的频率相同(2)。
总的来说,我们可以说CountVectorizer在文本标记、词汇表构建和向量生成方面做得很好;但是,它不会为你清除原始数据。
我做了一个关于如何用Python清理和准备数据的指南,如果你想学习最佳实践,请查看:
https:// towardsdatascience.com/ a-straightforward-guide-to-cleaning-and-preparing-data-in-python-8c82f209ae33
6.词频-逆文档频率(TF-IDF) 与CountVectorizer不同,TF-IDF计算“权重”,表示单词与文档集合(又称语料库)中文档的相关性。TF-IDF值随单词在文档中出现的次数成比例增加,并被包含该单词的语料库中的文档数量所抵消。简单地说,TF-IDF分数越高,这个术语就越稀有、独特或有价值,反之亦然。
它在信息检索中有应用,比如搜索引擎,目的是提供与你正在搜索的内容最相关的结果。
在我们看到Python实现之前,让我们先看一个示例,以便你了解如何计算TF和IDF。对于下面的示例,我们将使用与CountVectorizer示例相同的句子。
句子1 :“I love writing code in Python. I love Python code”
句子2 :“I hate writing code in Java. I hate Java code”
词频(TF) 有不同的方法来定义词频。一个建议是原始计数本身(即计数向量器所做的),但另一个建议是句子中单词的频率除以句子中单词的总数。对于这个简单的示例,我们将使用第一个条件,因此词频显示在下表中。
如你所见,这些值与之前为CountVectorizer计算的值相同。另外,不考虑2个字母或更少的单词。
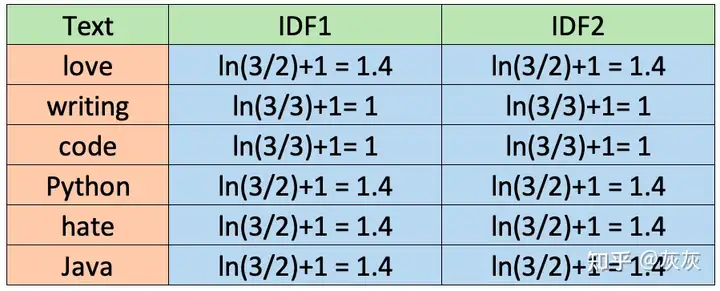
逆文档频率(IDF) IDF的计算方法也不同。尽管标准教科书表示法将IDF定义为idf(t) = log [ n / (df(t) + 1) ],但是我们稍后将在Python中使用的sklearn库默认计算公式如下。
另外,sklearn假设自然对数ln,而不是log和smooth(smooth_idf=True)。让我们按照sklearn的方法计算每个单词的IDF值。
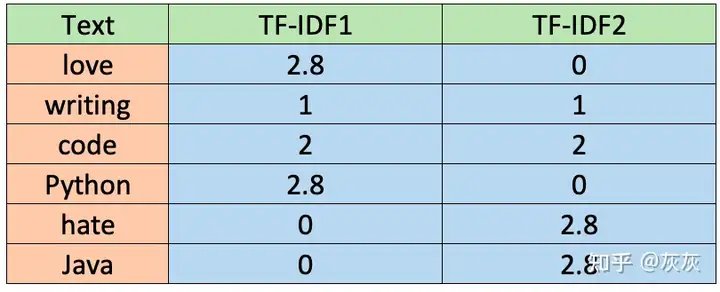
TF-IDF 一旦我们得到TF和IDF值,我们就可以通过将这两个值相乘(TF-IDF=TF*IDF)得到TF-IDF。数值如下表所示。
Python实现 感谢sklearn库,用Python计算上表所示的TF-IDF需要几行代码。
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
text = ["I love writing code in Python. I love Python code",
"I hate writing code in Java. I hate Java code"]
df = pd.DataFrame({'review': ['review1', 'review2'], 'text':text})
tfidf = TfidfVectorizer(stop_words='english', norm=None)
tfidf_matrix = tfidf.fit_transform(df['text'])
df_dtm = pd.DataFrame(tfidf_matrix.toarray(),
index=df['review'].values,
columns=tfidf.get_feature_names())
df_dtm
存储在df_dtm中的TF-IDF表示如下图所示。同样,TF-IDF不考虑2个字母或更少的单词。
注意:默认情况下,TfidfVectorizer()使用l2规范化,但要使用上面显示的相同公式,我们将norm=None设置为参数。
有关sklearn中默认使用的公式以及如何自定义公式的更多详细信息,请查看其文档:https:// scikit-learn.org/stable /modules/generated/sklearn.feature_extraction.text.TfidfTransformer.html
7.Wordcloud Wordcloud是一种流行的技术,它可以帮助我们识别文本中的关键字。
在wordcloud中,使用频率较高的单词的字体更大、更粗体,而使用频率较低的单词的字体更小或更细。
在Python中,可以使用wordcloud库创建简单的wordclouds,使用stylecloud库创建漂亮的wordclouds。
下面是用Python制作wordcloud的代码。我用的是史蒂夫·乔布斯演讲的文本文件。
import stylecloud
stylecloud.gen_stylecloud(file_path='SJ-Speech.txt',
icon_name= "fas fa-apple-alt")
这是上面代码的结果。
Wordclouds之所以如此流行,是因为它们引人入胜、易于理解、易于创建。
你可以通过更改颜色、删除停用词、选择图像,甚至添加自己的图像将其用作wordcloud的掩码,进一步进行自定义。有关更多详细信息,请查看下面的教程。
https:// towardsdatascience.com/ how-to-easily-make-beautiful-wordclouds-in-python-55789102f6f5
就这样!你刚刚了解了7种NLP技术的核心概念以及如何在Python中实现它们。本文中编写的所有代码都可以在我的Github上找到:https:// github.com/ifrankandrad e/data-science-projects.git