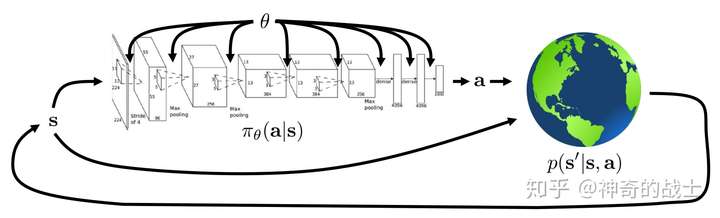
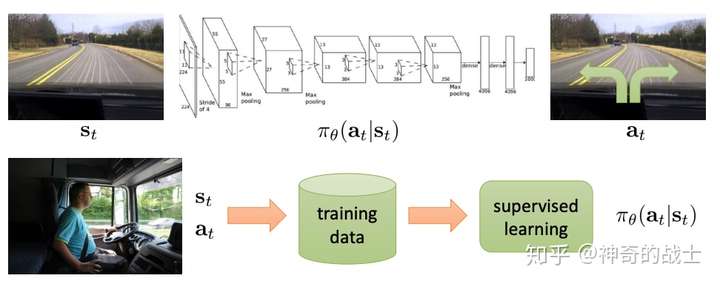
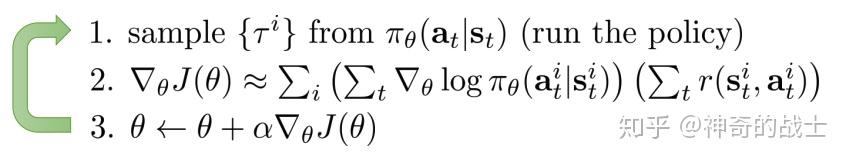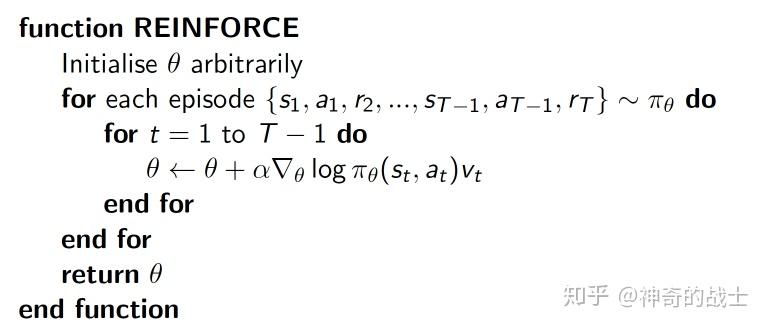学习参数化表示的策略(Parameterized policy), 输入环境状态来选择动作,这里使用来表示策略的参数向量,因此策略函数表示为
其中时刻,环境状态为,参数为,输出动作的概率为
因此生成马尔可夫决策过程的一个轨迹(trajectory)的概率为
更一般地,将策略下生成轨迹的概率表示为
策略梯度方法的目标就是找到一组最佳的参数来表示策略函数使得累计奖励的期望最大,即
令累积奖励为,设定优化目标优化策略参数使得奖励的期望值最大
对求梯度可得策略梯度,公式 (6) 的推导过程请参见链接
将策略 (1) 两边取 log 对数,然后带入梯度表达式 (6) ,推导策略梯度的公式请参考下图
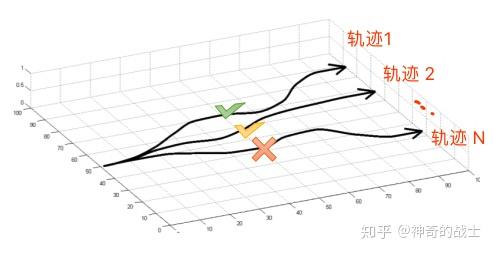
根据策略生成条轨迹如图所示
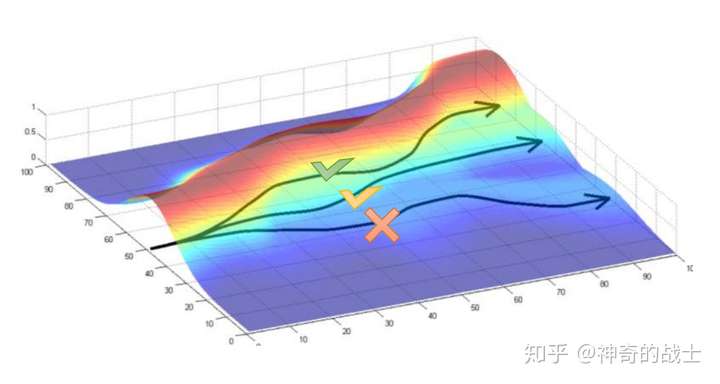
利用上图条轨迹的经验平均对策略梯度进行逼近,有公式 (7) (8)
其中为轨迹的数量,为一条轨迹的长度,假设已知策略,那么就可以计算出策略的梯度。另一方面,根据策略,在仿真环境中生成条轨迹的数据,即可计算出 (8),根据梯度上升 对参数进行一步更新,如公式 (9)
总结下来就是:
根据公式 (7) (8) (9) 可得蒙特卡罗 REINFORCE 算法流程
写成伪代码形式
策略属于概率分布,可以用神经网络来表示这种概率分布,输入状态,神经网络将映射成向量,然后网络输出概率和动作采样值,令为 log 标准差。
其中
在连续的运动空间中,通常使用高斯策略,假设方差为,策略是高斯的,输入状态输出动作服从,那么 log 策略梯度为
在实际使用高斯策略时,用神经网络来表示,即令,那么策略
策略的梯度
然后反向传播,更新网络参数