��ƪ�̳�Transformer�Ļ���ԭ��д�ú�ʵ�ã�ϣ���ܰﵽ����
Transformer�Ļ���ԭ��
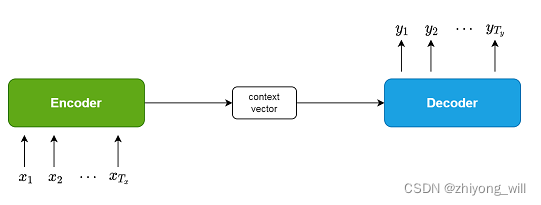
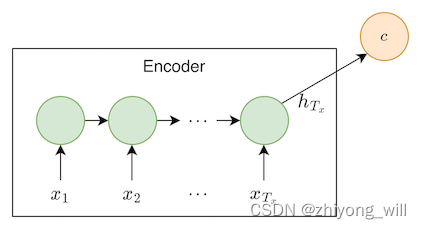
1. Seq2Seq��� 1.1. Seq2Seq��ܸ��� Seq2Seq[1]�����������������루Neural Machine Translation��NMT����������������ڽ�һ�����ԣ�sequence���������һ�����ԣ�sequence������ṹ����ͼ��ʾ��
��Seq2Seq����а�����Encoder��Decoder�������֡���Encoder�Σ�ͨ�������罫ԭʼ������{ x 1 , x 2 , ⋯ , x T x } { x 1 , x 2 , ⋯ , x T x } { c 1 , c 2 , ⋯ , c l } { c 1 , c 2 , ⋯ , c l } { y 1 , y 2 , ⋯ , y T y } { y 1 , y 2 , ⋯ , y T y }
1.2. ��ģ���� ��Encoder��Decoder���֣���Ҫģ���ܹ���ʱ�����ݽ�ģ����NLP�У�ͨ��ʹ�����ַ�ʽ��ʱ�����ݽ�ģ��һ������RNN[2]��LSTM[3]Ϊ���Ľ�ģ��������һ������CNN[4]��[5]Ϊ���Ľ�ģ������
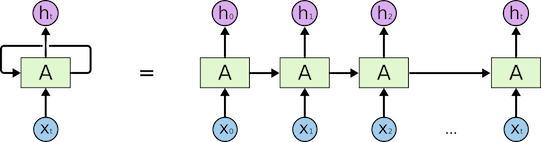
��RNNΪ�����������������ͼ��ʾ��
�ڻ���RNN�Ľ�ģ�����У�t t t − 1 t − 1 t t
h t = f ( U h t − 1 + W x t + b ) h t = f ( U h t − 1 + W x t + b )
��RNN�Ļ������������ܶ��Ż��ķ���������ڳ���������������Ż��������LSTM�Լ�GRU��ģ�ͣ����ڵ���ģ���������⣬�����˫���RNNģ�ͣ������˶�ʱ�����ݵĽ�ģ�������Լ�RNNΪ�������Ͽ��Կ�����RNN���������Dz����ײ��л�����Ϊt t t − 1 t − 1 t − 1 t − 1
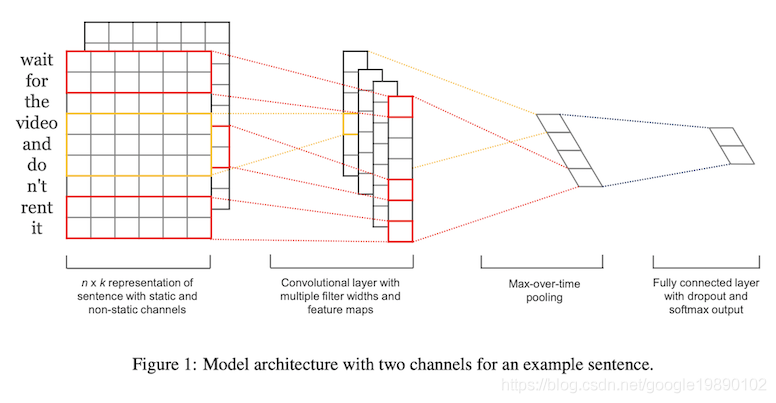
�ڶ�����CNN�Ľ�ģ��������TextCNN[4]��[5]ģ��Ϊ����
�������ĺ�ɫΪ�������ò�ͬ��filter�Ĵ�СN N N N
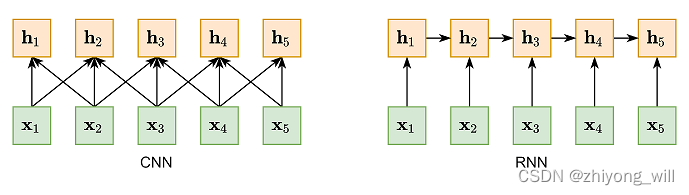
��ͼ�п��Կ�����CNN��RNN���ǶԱ䳤���е�һ��“�ֲ�����”�������������ǻ���N-gram�ľֲ����룻������ѭ�������磬�����ݶ���ʧ������Ҳֻ�ܽ����̾���������Ҫ������ֶ̾���������“�ֲ�����”���⣬������������֮��ij�����������ϵ������ʹ���������ַ�����һ�ַ�������������IJ�����ͨ��һ�������������ȡԶ�������Ϣ��������һ�ַ�����ʹ��ȫ��������[6]��ȫ������������ͼ��ʾ��
Ȼ����ȫ����������Ȼ���Զ�Զ����������ģ�������������䳤���������У�ͬʱ����ȫ���������У�ȱʧ�˴�֮���˳����Ϣ����ͬ�����볤�ȣ�������Ȩ�صĴ�СҲ�Dz�ͬ�ġ�
���ϣ�����RNN��CNN�Լ�ȫ�������罨ģ�������������µ����⣺
�������������⣨RNN��CNN��
�������⣨RNN��
�䳤�������⣬������Ϣ���⣨ȫ�������磩
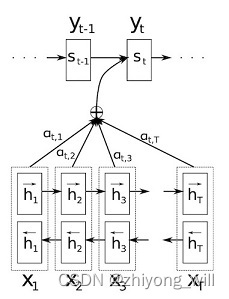
1.3. Self-Attention Ϊ��������Seq2Seq��ܵ����ܣ���Seq2Seq�����������Attention����[7]��Attention����ͨ����ѵ�����ݵ�ѧϰ����������x x
���У�Attention�ļ�����������Բ�ͬ��Decoder���y t y t c t c t y t y t
y t = f ( y t − 1 , s t − 1 , c t ) y t = f ( y t − 1 , s t − 1 , c t )
����c t c t
c i = ∑ j = 1 T x α i j h j c i = j = 1 ∑ T x α ij h j
���У�α i j α ij
α i j = e x p ( e i j ) ∑ k = 1 T x e x p ( e i k ) α ij = ∑ k = 1 T x e x p ( e ik ) e x p ( e ij )
���У�e i j e ij i i s i − 1 s i − 1 j j h j h j
e i j = a ( s i − 1 , h j ) = v a T t a n h ( W a s i − 1 + U a h j ) e ij = a ( s i − 1 , h j ) = v a T t anh ( W a s i − 1 + U a h j )
�����Ĺ�ʽҲ��ʾ��һ���Ե�Attention�ļ�����̣�����
����Attention�÷֣�e i = a ( u , v i ) e i = a ( u , v i )
��һ����α i = e i ∑ i e i α i = ∑ i e i e i
�����c = ∑ i α i v i c = ∑ i α i v i
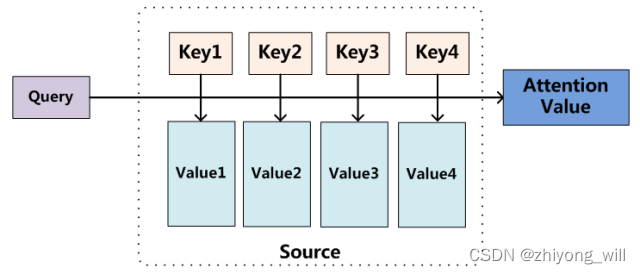
ͨ����һ��Attention�������Ա�������һ��ӳ�䣬���и�ӳ���������һ��query��һ��key-value�ԣ��������̿���ͨ�����µ�ͼ��ʾ[8]��
����ʽ��Ӧ��QueryΪ��ʽ�е�u u v i v i v i v i
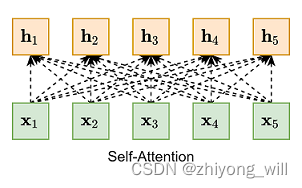
���Ҳ�Ĵ�ΪQuery��Query������ÿһ��Key����Attention�÷֣�����ͼ���Կ�����Query��it_����Key��animal_����Attention�÷ֱȽϴ�Self-Attention��һ����ʽΪ��s o f t m a x ( X X T ) X so f t ma x ( X X T ) X
������ȫ���Ӳ�ͬ���ǣ�Self-Attention�����ܱ䳤�����Ӱ�졣
Self-Attention���������˴�ͳRNNģ�͵ij��������������ײ��е����⡣��ȻSelf-Attention����Щ�ŵ㣬���ǻ�����Self-Attention���������ܲ��������Ϣ��Google��2017������˽��Seq2Seq�����Transformerģ��[10]����Self-Attention�Ľṹ��ȫ�����˴�ͳ�Ļ���RNN�Ľ�ģ������ͬʱ��Transformer��ģ���м����˴������Ϣ�������ڷ���������ȡ���˱�RNN���õijɼ���
��Transformer�����ɱ�����Seq2Seq��Encoder+Decoder��ܣ���Encoder�ζ�Դ�ı����룬����Embedding����Ϊc c y 1 , y 2 , ⋯ , y t − 1 y 1 , y 2 , ⋯ , y t − 1 y t y t
y t = f ( y t �O y 1 , y 2 , ⋯ , y t − 1 , c ) y t = f ( y t �O y 1 , y 2 , ⋯ , y t − 1 , c )
���ڴ�ͳ����Attention��Seq2Seq����У�Encoder������Embedding�ǹ̶�����ģ�����ͼ��ʾ��
���ڴ���Attention��Seq2Seq����У�Encoder������Embedding����ݵ�ǰ��ҪԤ���ֵ����һ����̬��Embedding����������ͼ��ʾ��
����Transformer����е�Encoder������õڶ��ַ�����
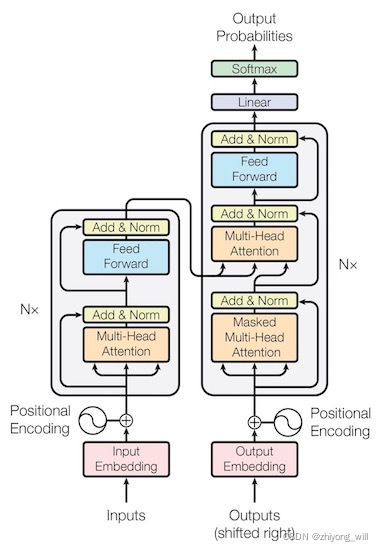
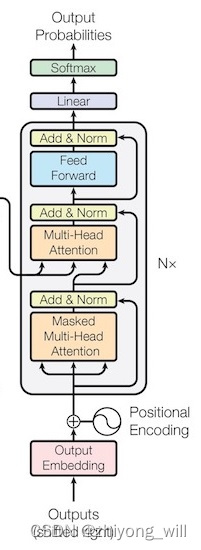
2. �㷨ԭ�� Transformer������ṹ����ͼ��ʾ��
�ʹ������Seq2Seqģ��һ������Transformer�Ľṹ�У�ͬ������Encoder����ͼ�е���ಿ�֣���Decoder����ͼ�е��Ҳಿ�֣�����������ɡ���TensorFlow Core [11]�Ĵ��뽲��Ϊ���ӣ���������Transformer�������ṹ��
2.1. Encoder Encoder���ֵĽṹ����ͼ��ʾ��
��Encoder���֣�ͨ���ѵ�����ض�ģ�飨��ͼ��Nx���֣���������[10]�У�ѡ��N = 6 N = 6
class Encoder ( tf. keras. layers. Layer) :
def __init__ ( self, num_layers, d_model, num_heads, dff, input_vocab_size,
maximum_position_encoding, rate= 0.1 ) :
super ( Encoder, self) . __init__( )
self. d_model = d_model
self. num_layers = num_layers
self. embedding = tf. keras. layers. Embedding( input_vocab_size, d_model)
self. pos_encoding = positional_encoding( maximum_position_encoding,
self. d_model)
self. enc_layers = [ EncoderLayer( d_model, num_heads, dff, rate)
for _ in range ( num_layers) ]
self. dropout = tf. keras. layers. Dropout( rate)
def call ( self, x, training, mask) :
seq_len = tf. shape( x) [ 1 ]
x = self. embedding( x)
x *= tf. math. sqrt( tf. cast( self. d_model, tf. float32) )
x += self. pos_encoding[ : , : seq_len, : ]
x = self. dropout( x, training= training)
for i in range ( self. num_layers) :
x = self. enc_layers[ i] ( x, training, mask)
return x
ע��������[10]���ᵽ��Embedding�㣬����Ȩ��d m o d e l d m o d e l
2.1.1. ���� ��Transformer��������RNN��ģ�ͣ�ʹ�û���Self-Attentionģ�ͣ������RNNģ�ͣ�����Self-Attention��ģ���ܹ����ⳤ���������Լ����е����⣬Ȼ����һ���Self-Attentionģ���������Դ���ģ�ģ���������ı���������Ϊ��Ҫ�ģ����������[10]�У������ᵽ������λ�ñ��루Positional Encoding��������Ȼ�ʵ�Embedding��λ�õ�Embedding��ӣ���Ϊ���յ�����Embedding������λ�ñ���ֱ�Ϊ��
�ò�ͬƵ�ʵ�sin��cos��������
ѧϰ��Positional Embedding
ͨ������ʵ�鷢�����ߵĽ��һ������������ѡ���˵�һ�ַ�����
P E ( p o s , 2 i ) = sin ( p o s / 100 0 2 i / d m o d e l ) P E ( p os , 2 i ) = sin ( p os /100 0 2 i / d m o d e l )
P E ( p o s , 2 i + 1 ) = cos ( p o s / 100 0 2 i / d m o d e l ) P E ( p os , 2 i + 1 ) = cos ( p os /100 0 2 i / d m o d e l )
λ�ñ���Ĵ���������[11]��Ϊ��
def get_angles ( pos, i, d_model) :
angle_rates = 1 / np. power( 10000 , ( 2 * ( i// 2 ) ) / np. float32( d_model) )
return pos * angle_rates
def positional_encoding ( position, d_model) :
angle_rads = get_angles( np. arange( position) [ : , np. newaxis] ,
np. arange( d_model) [ np. newaxis, : ] ,
d_model)
angle_rads[ : , 0 : : 2 ] = np. sin( angle_rads[ : , 0 : : 2 ] )
angle_rads[ : , 1 : : 2 ] = np. cos( angle_rads[ : , 1 : : 2 ] )
pos_encoding = angle_rads[ np. newaxis, . . . ]
return tf. cast( pos_encoding, dtype= tf. float32)
ͨ��ԭʼ��������λ��������ӣ���õ������յĴ���λ����Ϣ�Ĵ�������
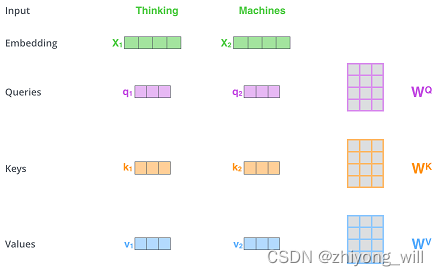
2.2.2. Multi-Head Self-Attention �õ��˴����������к���ΪX X Q Q K K V V
����ʹ�����Ա任�õ�Q Q K K V V
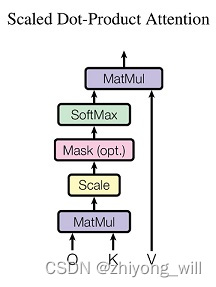
��Transformer�У�ʹ�õ���Scaled Dot-Product Attention���������㷽��Ϊ��
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V A tt e n t i o n ( Q , K , V ) = so f t ma x ( d k
Q K T ) V
����1 d k d k
1
���ο�����[11] ������Q��K�ľ�ֵΪ0������Ϊ1�����ǵľ���˻����о�ֵΪ0������Ϊd k d k d k d k
������̿�����ͼ��ʾ��
Scaled Dot-Product Attentionģ��Ĵ���������[11]��Ϊ��
def scaled_dot_product_attention ( q, k, v, mask) :
"""����ע����Ȩ�ء�
q, k, v �������ƥ���ǰ��ά�ȡ�
k, v ������ƥ��ĵ����ڶ���ά�ȣ����磺seq_len_k = seq_len_v��
��Ȼ mask ���������ͣ�����ǰհ���в�ͬ����״��
���� mask �����ܽ��й㲥ת���Ա���͡�
����:
q: �������״ == (..., seq_len_q, depth)
k: ��������״ == (..., seq_len_k, depth)
v: ��ֵ����״ == (..., seq_len_v, depth_v)
mask: Float ����������״��ת����
(..., seq_len_q, seq_len_k)��Ĭ��ΪNone��
����ֵ:
�����ע����Ȩ��
"""
matmul_qk = tf. matmul( q, k, transpose_b= True )
dk = tf. cast( tf. shape( k) [ - 1 ] , tf. float32)
scaled_attention_logits = matmul_qk / tf. math. sqrt( dk)
if mask is not None :
scaled_attention_logits += ( mask * - 1e9 )
attention_weights = tf. nn. softmax( scaled_attention_logits, axis= - 1 )
output = tf. matmul( attention_weights, v)
return output, attention_weights
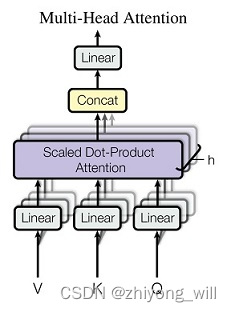
ͨ�����Scaled Dot-Product Attentionģ�����ϣ����γ���Multi-Head Self-Attention�����������ͼ��ʾ��
����̿��Ա�ʾΪ��
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , ⋯ , h e a d h ) W o M u lt i He a d ( Q , K , V ) = C o n c a t ( h e a d 1 , ⋯ , h e a d h ) W o
���У�ÿһ��h e a d i h e a d i h h
Multi-head Attentionģ��Ĵ���������[11]��Ϊ��
class MultiHeadAttention ( tf. keras. layers. Layer) :
def __init__ ( self, d_model, num_heads) :
super ( MultiHeadAttention, self) . __init__( )
self. num_heads = num_heads
self. d_model = d_model
assert d_model % self. num_heads == 0
self. depth = d_model // self. num_heads
self. wq = tf. keras. layers. Dense( d_model)
self. wk = tf. keras. layers. Dense( d_model)
self. wv = tf. keras. layers. Dense( d_model)
self. dense = tf. keras. layers. Dense( d_model)
def split_heads ( self, x, batch_size) :
"""�ֲ����һ��ά�ȵ� (num_heads, depth).
ת�ý��ʹ����״Ϊ (batch_size, num_heads, seq_len, depth)
"""
x = tf. reshape( x, ( batch_size, - 1 , self. num_heads, self. depth) )
return tf. transpose( x, perm= [ 0 , 2 , 1 , 3 ] )
def call ( self, v, k, q, mask) :
batch_size = tf. shape( q) [ 0 ]
q = self. wq( q)
k = self. wk( k)
v = self. wv( v)
q = self. split_heads( q, batch_size)
k = self. split_heads( k, batch_size)
v = self. split_heads( v, batch_size)
scaled_attention, attention_weights = scaled_dot_product_attention(
q, k, v, mask)
scaled_attention = tf. transpose( scaled_attention, perm= [ 0 , 2 , 1 , 3 ] )
concat_attention = tf. reshape( scaled_attention,
( batch_size, - 1 , self. d_model) )
output = self. dense( concat_attention)
return output, attention_weights
2.2.3. Layer Normalization Layer Normalization�����ÿ���������й�һ�������Զ�Transformerѧϰ����������Embedding�ۼӿ��ܴ�����“�߶�”�������Լ�����൱�ڶԱ���ÿ����һ�ʶ���Ŀռ����Լ������Ч����ģ�ͷ����TF�п���ʹ��tf.keras.layers.LayerNormalization()����ֱ��ʵ��Layer Normalization���ܡ���Transformer�У�Layer Normalization�ǶԲв����Ӻ�Ľ�����й�һ�������幫ʽ������ʾ��
L a y e r N o r m ( x + S u b l a y e r ( x ) ) L a yer N or m ( x + S u b l a yer ( x ) )
2.2.4. Position-wise FFN Position-wise Feed Forward Network����һ��ȫ�������磬��Transformer�У�������ְ���������FFN���磬�����������Ĺ�ʽ��ʾ��
F F N ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2
Position-wise FFNģ��Ĵ���������[11]��Ϊ��
def point_wise_feed_forward_network ( d_model, dff) :
return tf. keras. Sequential( [
tf. keras. layers. Dense( dff, activation= 'relu' ) ,
tf. keras. layers. Dense( d_model)
] )
��������Ķ�����֣������γ���Encoderģ�鲿�֣������������[11]��Ϊ��
class EncoderLayer ( tf. keras. layers. Layer) :
def __init__ ( self, d_model, num_heads, dff, rate= 0.1 ) :
super ( EncoderLayer, self) . __init__( )
self. mha = MultiHeadAttention( d_model, num_heads)
self. ffn = point_wise_feed_forward_network( d_model, dff)
self. layernorm1 = tf. keras. layers. LayerNormalization( epsilon= 1e - 6 )
self. layernorm2 = tf. keras. layers. LayerNormalization( epsilon= 1e - 6 )
self. dropout1 = tf. keras. layers. Dropout( rate)
self. dropout2 = tf. keras. layers. Dropout( rate)
def call ( self, x, training, mask) :
attn_output, _ = self. mha( x, x, x, mask)
attn_output = self. dropout1( attn_output, training= training)
out1 = self. layernorm1( x + attn_output)
ffn_output = self. ffn( out1)
ffn_output = self. dropout2( ffn_output, training= training)
out2 = self. layernorm2( out1 + ffn_output)
return out2
2.2. Decoder Decoder���ֵĽṹ����ͼ��ʾ��
��Decoder���֣�ͨ���ѵ�����ض�ģ�飨��ͼ��Nx���֣���������[10]�У�ѡ��N = 6 N = 6
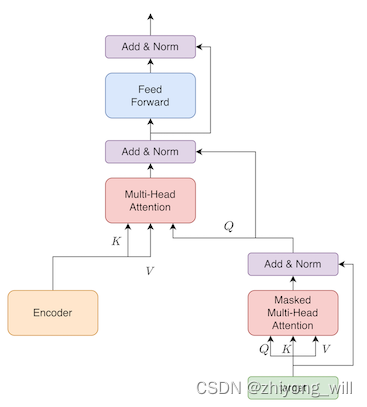
������Masked Multi-Head Self-Attention���sub-layer
Multi-Head Self-Attention�����벻һ������Encoder�У�Q Q K K V V Q Q K K V V
Decoder���ֵĴ����ڲο�����[11]��������ʾ��
class Decoder ( tf. keras. layers. Layer) :
def __init__ ( self, num_layers, d_model, num_heads, dff, target_vocab_size,
maximum_position_encoding, rate= 0.1 ) :
super ( Decoder, self) . __init__( )
self. d_model = d_model
self. num_layers = num_layers
self. embedding = tf. keras. layers. Embedding( target_vocab_size, d_model)
self. pos_encoding = positional_encoding( maximum_position_encoding, d_model)
self. dec_layers = [ DecoderLayer( d_model, num_heads, dff, rate)
for _ in range ( num_layers) ]
self. dropout = tf. keras. layers. Dropout( rate)
def call ( self, x, enc_output, training,
look_ahead_mask, padding_mask) :
seq_len = tf. shape( x) [ 1 ]
attention_weights = { }
x = self. embedding( x)
x *= tf. math. sqrt( tf. cast( self. d_model, tf. float32) )
x += self. pos_encoding[ : , : seq_len, : ]
x = self. dropout( x, training= training)
for i in range ( self. num_layers) :
x, block1, block2 = self. dec_layers[ i] ( x, enc_output, training,
look_ahead_mask, padding_mask)
attention_weights[ 'decoder_layer{}_block1' . format ( i+ 1 ) ] = block1
attention_weights[ 'decoder_layer{}_block2' . format ( i+ 1 ) ] = block2
return x, attention_weights
���գ���Encoder�Σ�����������е�ÿһ���ʲ���һ��Embedding��ʾ���������������е�x�Ĵ�СΪ[target_seq_len, d_model]��
2.2.1. Decoder���ֵ����� Decoder���ֵ���������t t t t t t
x = self. embedding( x)
x *= tf. math. sqrt( tf. cast( self. d_model, tf. float32) )
x += self. pos_encoding[ : , : seq_len, : ]
2.2.2. Masked Multi-Head Self-Attention Masked��Transformer�к���Ҫ�ĸ����ʵ��Transformer�д�������Mask��Mask�ĺ��������룬�����ڲ�ijЩֵ��ʹ��ģ���ڲ�������ʱ��ģ���ڲء�Transformer�а���������Mask���ֱ���padding mask��sequence mask�����У�padding mask�����е�Scaled Dot-Product Attention���涼��Ҫ�õ�����sequence maskֻ����Decoder��Masked Multi-Head Self-Attention�����õ���
Masked Language Model�������ı�������ڸǣ�mask�����ִʣ���ͨ��ѵ������ģ�ͣ���masked���Ĵ����ã��Դ�ѵ������ģ�͡�
�����������ж�Ҫ����padding���룬Ҳ����˵�趨һ��ͳһ�ľ��ӳ���N N N N 0 0 N N N N 0 0 1 1 0 0
def create_padding_mask ( seq) :
seq = tf. cast( tf. math. equal( seq, 0 ) , tf. float32)
return seq[ : , tf. newaxis, tf. newaxis, : ]
��Self-Attention�ļ�������У�����maskΪ1 1 0 0 scaled_dot_product_attention��������ʾ��
if mask is not None :
scaled_attention_logits += ( mask * - 1e9 )
sequence mask��Ϊ��ʹDecoderģ�鲻�ܿ���δ������Ϣ����Decoderģ���У�ϣ����t t t t t t t t 0 0
def create_look_ahead_mask ( size) :
mask = 1 - tf. linalg. band_part( tf. ones( ( size, size) ) , - 1 , 0 )
return mask
�������ֵ�mask�����һ���ڲο�����[11]�еĴ���������ʾ��
def create_masks ( inp, tar) :
enc_padding_mask = create_padding_mask( inp)
dec_padding_mask = create_padding_mask( inp)
look_ahead_mask = create_look_ahead_mask( tf. shape( tar) [ 1 ] )
dec_target_padding_mask = create_padding_mask( tar)
combined_mask = tf. maximum( dec_target_padding_mask, look_ahead_mask)
return enc_padding_mask, combined_mask, dec_padding_mask
2.2.3. Decoder�ĺ��IJ��� ����Decoder�ĺ��IJ��֣�������N x N x
����Masked Multi-Head Attention��������Ϊtarget��Embedding��Position Embedding�ĺͣ��������ΪMulti-Head Attention������Q Q K K V V t t t t t t
class DecoderLayer ( tf. keras. layers. Layer) :
def __init__ ( self, d_model, num_heads, dff, rate= 0.1 ) :
super ( DecoderLayer, self) . __init__( )
self. mha1 = MultiHeadAttention( d_model, num_heads)
self. mha2 = MultiHeadAttention( d_model, num_heads)
self. ffn = point_wise_feed_forward_network( d_model, dff)
self. layernorm1 = tf. keras. layers. LayerNormalization( epsilon= 1e - 6 )
self. layernorm2 = tf. keras. layers. LayerNormalization( epsilon= 1e - 6 )
self. layernorm3 = tf. keras. layers. LayerNormalization( epsilon= 1e - 6 )
self. dropout1 = tf. keras. layers. Dropout( rate)
self. dropout2 = tf. keras. layers. Dropout( rate)
self. dropout3 = tf. keras. layers. Dropout( rate)
def call ( self, x, enc_output, training,
look_ahead_mask, padding_mask) :
attn1, attn_weights_block1 = self. mha1( x, x, x, look_ahead_mask)
attn1 = self. dropout1( attn1, training= training)
out1 = self. layernorm1( attn1 + x)
attn2, attn_weights_block2 = self. mha2(
enc_output, enc_output, out1, padding_mask)
attn2 = self. dropout2( attn2, training= training)
out2 = self. layernorm2( attn2 + out1)
ffn_output = self. ffn( out2)
ffn_output = self. dropout3( ffn_output, training= training)
out3 = self. layernorm3( ffn_output + out2)
return out3, attn_weights_block1, attn_weights_block2
2.3. ģ��ѵ�� ����������Encoder��Decoderģ�飬����һ��������Seq2Seq��ܣ���Ҫ�ۺ����������ֵ�����������Transformer�Ĵ����ڲο�����[11]Ϊ��
class Transformer ( tf. keras. Model) :
def __init__ ( self, num_layers, d_model, num_heads, dff, input_vocab_size,
target_vocab_size, pe_input, pe_target, rate= 0.1 ) :
super ( Transformer, self) . __init__( )
self. encoder = Encoder( num_layers, d_model, num_heads, dff,
input_vocab_size, pe_input, rate)
self. decoder = Decoder( num_layers, d_model, num_heads, dff,
target_vocab_size, pe_target, rate)
self. final_layer = tf. keras. layers. Dense( target_vocab_size)
def call ( self, inp, tar, training, enc_padding_mask,
look_ahead_mask, dec_padding_mask) :
enc_output = self. encoder( inp, training, enc_padding_mask)
dec_output, attention_weights = self. decoder(
tar, enc_output, training, look_ahead_mask, dec_padding_mask)
final_output = self. final_layer( dec_output)
return final_output, attention_weights
3. �ܽ� Transformer�Ի��ڵݹ�������RNN��Seq2Seqģ�͵ľ�Ľ������ı����е�ѧϰ���ܹ����õ���ȡ�ı��е���Ϣ����Seq2Seq��������ȡ�ýϺõĽ������Transformer����Ҳ����һ���ľ����ԣ�����Ҫ����ע����ֻ�ܴ����̶����ȵ��ı��ַ���������ڳ��ı���˵�ᶪʧ�ܶ���Ϣ��
����� [1] Cho K, Merrienboer B V, Gulcehre C, et al. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation[J]. Computer Science, 2014.
[2] ѭ��������RNN
[3] �����ڼ�������LSTM
[4] CNN���ı���ģ�е�Ӧ��TextCNN
[5] Y. Kim, “Convolutional neural networks for sentence classification,” in Proceedings of EMNLP 2014
[6] �����������ѧϰ
[7] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv:1409.0473, 2014.
[8] Attentionע����������self-attention��ע��������
[9] The Illustrated Transformer
[10] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[11] �������Ե� Transformer ģ��
[11] transformer������ļش�
[12] nlp�е�Attentionע��������+Transformer���
[13] ���ѧϰ�е�ע����ģ�ͣ�2017�棩
[14] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
[15] ģ���Ż�֮Layer Normalization
[16] ����ϸͼ��Self-Attention
[17] �����侫����Transformerģ�ͺ�Attention����
[18] Transformer������tensorflow������
�����б� BertԤѵ��ģ�͡�Bert�ϴCNN��LSTMģ�͵����롢������