为什么初始化一个非常小的学习率呢?因为初始的学习率过小,会需要非常多次的迭代才能使模型达到最优状态,训练缓慢。如果训练过程中不断缩小学习率,可以快速又精确的获得最优模型。
-
monitor:监测的值,可以是accuracy,val_loss,val_accuracy -
factor:缩放学习率的值,学习率将以lr = lr*factor的形式被减少 -
patience:当patience个epoch过去而模型性能不提升时,学习率减少的动作会被触发 -
mode:‘auto’,‘min’,‘max’之一 默认‘auto’就行 -
epsilon:阈值,用来确定是否进入检测值的“平原区” -
cooldown:学习率减少后,会经过cooldown个epoch才重新进行正常操作 -
min_lr:学习率最小值,能缩小到的下限 -
-
Reduce=ReduceLROnPlateau(monitor='val_accuracy', -
factor=0.1, -
patience=2, -
verbose=1, -
mode='auto', -
epsilon=0.0001, -
cooldown=0, -
min_lr=0)
使用手写数字mnist作演示,当只设置EarlyStopping的时候,代码及效果如下:
-
# -*- coding: utf-8 -*- -
import numpy #导入数据库 -
from keras.datasets import mnist -
from keras.models import Sequential -
from keras.layers import Dense -
from keras.layers import Dropout -
from keras.utils import np_utils -
from keras.callbacks import EarlyStopping -
from keras import optimizers -
from keras.callbacks import ReduceLROnPlateau -
-
seed = 7 #设置随机种子 -
numpy.random.seed(seed) -
-
(X_train, y_train), (X_test, y_test) = mnist.load_data(path='mnist.npz') #加载数据 -
-
num_pixels = X_train.shape[1] * X_train.shape[2] -
X_train = X_train.reshape(X_train.shape[0], num_pixels).astype('float32') -
X_test = X_test.reshape(X_test.shape[0], num_pixels).astype('float32') -
#数据集是3维的向量(instance length,width,height).对于多层感知机,模型的输入是二维的向量,因此这 -
#里需要将数据集reshape,即将28*28的向量转成784长度的数组。可以用numpy的reshape函数轻松实现这个过 -
#程。 -
-
#给定的像素的灰度值在0-255,为了使模型的训练效果更好,通常将数值归一化映射到0-1。 -
X_train = X_train / 255 -
X_test = X_test / 255 -
-
#最后,模型的输出是对每个类别的打分预测,对于分类结果从0-9的每个类别都有一个预测分值,表示将模型 -
#输入预测为该类的概率大小,概率越大可信度越高。由于原始的数据标签是0-9的整数值,通常将其表示成#0ne-hot向量。如第一个训练数据的标签为5,one-hot表示为[0,0,0,0,0,1,0,0,0,0]。 -
-
y_train = np_utils.to_categorical(y_train) -
y_test = np_utils.to_categorical(y_test) -
num_classes = y_test.shape[1] -
-
#现在需要做得就是搭建神经网络模型了,创建一个函数,建立含有一个隐层的神经网络。 -
# define baseline model -
def baseline_model(): -
# create model -
model = Sequential() -
model.add(Dense(num_pixels, input_dim=num_pixels, kernel_initializer='normal', activation='relu')) -
model.add(Dropout(rate=0.5)) -
model.add(Dense(num_classes, kernel_initializer='normal', activation='softmax')) -
# Compile model -
adam=optimizers.Adam(learning_rate=0.01) -
model.compile(loss='categorical_crossentropy', -
optimizer=adam, metrics=['accuracy']) -
-
return model -
-
model=baseline_model() -
EarlyStop=EarlyStopping(monitor='val_accuracy', -
patience=2,verbose=1, mode='auto') -
#注释掉 -
#Reduce=ReduceLROnPlateau(monitor='val_accuracy', -
# factor=0.1, -
# patience=2, -
# verbose=1, -
# mode='auto', -
# epsilon=0.0001, -
# cooldown=0, -
# min_lr=0) -
# Fit the model -
history=model.fit(X_train, y_train, validation_data=(X_test, y_test), -
epochs=30, batch_size=200, -
callbacks=[EarlyStop],verbose=2) -
# Final evaluation of the model -
scores = model.evaluate(X_test, y_test, verbose=1) -
print("Baseline Error: %.2f%%" % (100-scores[1]*100))
效果:训练到5轮就触发早停了。
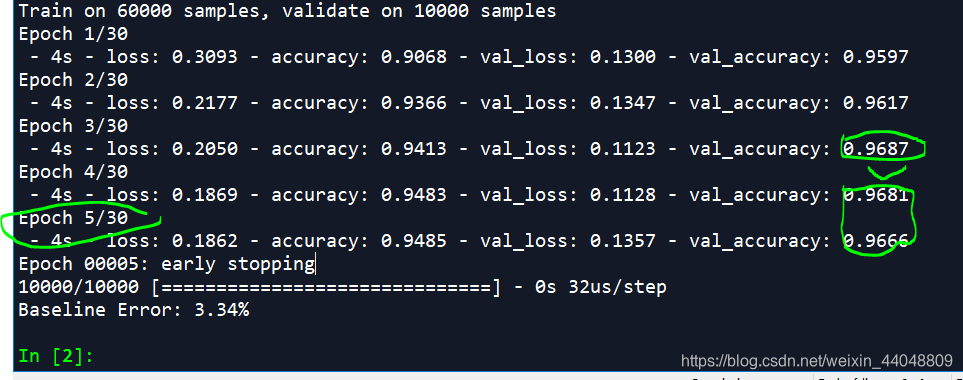
当使用ReduceLROnPlateau在训练过程中优化减小learning_rate:
-
# -*- coding: utf-8 -*- -
import numpy #导入数据库 -
from keras.datasets import mnist -
from keras.models import Sequential -
from keras.layers import Dense -
from keras.layers import Dropout -
from keras.utils import np_utils -
from keras.callbacks import EarlyStopping -
from keras import optimizers -
from keras.callbacks import ReduceLROnPlateau -
-
seed = 7 #设置随机种子 -
numpy.random.seed(seed) -
-
y_train), (X_test, y_test) = mnist.load_data(path='mnist.npz') #加载数据 -
-
num_pixels = X_train.shape[1] * X_train.shape[2] -
X_train = X_train.reshape(X_train.shape[0], num_pixels).astype('float32') -
X_test = X_test.reshape(X_test.shape[0], num_pixels).astype('float32') -
#数据集是3维的向量(instance length,width,height).对于多层感知机,模型的输入是二维的向量,因此这 -
#里需要将数据集reshape,即将28*28的向量转成784长度的数组。可以用numpy的reshape函数轻松实现这个过 -
#程。 -
-
#给定的像素的灰度值在0-255,为了使模型的训练效果更好,通常将数值归一化映射到0-1。 -
X_train = X_train / 255 -
X_test = X_test / 255 -
-
#最后,模型的输出是对每个类别的打分预测,对于分类结果从0-9的每个类别都有一个预测分值,表示将模型 -
#输入预测为该类的概率大小,概率越大可信度越高。由于原始的数据标签是0-9的整数值,通常将其表示成#0ne-hot向量。如第一个训练数据的标签为5,one-hot表示为[0,0,0,0,0,1,0,0,0,0]。 -
-
y_train = np_utils.to_categorical(y_train) -
y_test = np_utils.to_categorical(y_test) -
num_classes = y_test.shape[1] -
-
#现在需要做得就是搭建神经网络模型了,创建一个函数,建立含有一个隐层的神经网络。 -
# define baseline model -
def baseline_model(): -
# create model -
model = Sequential() -
input_dim=num_pixels, kernel_initializer='normal', activation='relu')) -
=0.5)) -
kernel_initializer='normal', activation='softmax')) -
# Compile model -
adam=optimizers.Adam(learning_rate=0.01) -
='categorical_crossentropy', -
optimizer=adam, metrics=['accuracy']) -
-
return model -
-
model=baseline_model() -
EarlyStop=EarlyStopping(monitor='val_accuracy', -
patience=2,verbose=1, mode='auto') -
#减小学习率 -
Reduce=ReduceLROnPlateau(monitor='val_accuracy', -
factor=0.1, -
patience=1, -
verbose=1, -
mode='auto', -
epsilon=0.0001, -
cooldown=0, -
min_lr=0) -
# Fit the model -
history=model.fit(X_train, y_train, validation_data=(X_test, y_test), -
epochs=30, batch_size=200, -
callbacks=[EarlyStop,Reduce],verbose=2) -
# Final evaluation of the model -
scores = model.evaluate(X_test, y_test, verbose=1) -
Error: %.2f%%" % (100-scores[1]*100)) -
得到的val_accuracy有所提升,训练轮数会增加。不会过早触发EarlyStooping。当然EarlyStopping的patience要比ReduceLROnPlateau的patience大一些才会有效果。