这篇教程深度学习(七)U-Net原理以及keras代码实现医学图像眼球血管分割写得很实用,希望能帮到您。
深度学习(七)U-Net原理以及keras代码实现医学图像眼球血管分割
原文作者:aircraft
原文链接:https://www.cnblogs.com/DOMLX/p/9780786.html
有没有大佬们的公司招c++开发/图像处理/opengl/opencv/halcon实习的啊,带上我一个呗QAQ
深度学习教程目录如下,还在继续更新完善中
深度学习系列教程目录
最近秦老师叫我研究深度学习与指静脉结合,我就拿这篇来做敲门砖,并且成功将指静脉的纹理特征提取用u-net实现了,而眼球血管分割则给我提供了很大的帮助。现在就分享给大家吧。。虽然很想把指静脉也写一篇单独的博客分享,但是不允许啊hhhhhhh
DRIVE数据集下载百度云链接:链接:https://pan.baidu.com/s/1C_1ikDwexB0hZvOwMSeDtw
提取码:关注最下面公众号添加小编微信 发送文章标题源码获取
U-net+kears实现眼部血管分割源码python2.7版本的百度云链接:链接:https://pan.baidu.com/s/1C_1ikDwexB0hZvOwMSeDtw
提取码:关注最下面公众号添加小编微信 发送文章标题源码获取
U-net+kears实现眼部血管分割源码python3.6版本的百度链接:链接:https://pan.baidu.com/s/1rAf6wuWGCswuBfkDivxjyQ
提取码:关注最下面公众号添加小编微信 发送文章标题源码获取
全卷积神经网络
大名鼎鼎的FCN就不多做介绍了,这里有一篇很好的博文 http://www.cnblogs.com/gujianhan/p/6030639.html。
不过还是建议把论文读一下,这样才能加深理解。
医学图像分割框架
医学图像分割主要有两种框架,一个是基于CNN的,另一个就是基于FCN的。这里都是通过网络来进行语义分割。
那么什么是语义分割?可不是汉字分割句意,在图像处理中有自己的定义。
图像语义分割的意思就是机器自动分割并识别出图像中的内容,比如给出一个人骑摩托车的照片,机器判断后应当能够生成右侧图,红色标注为人,绿色是车(黑色表示 back ground)。

所以图像分割对图像理解的意义,就好比读古书首先要断句一样。
在 Deeplearning 技术快速发展之前,就已经有了很多做图像分割的技术,其中比较著名的是一种叫做 “Normalized cut” 的图划分方法,简称 “N-cut”。
N-cut 的计算有一些连接权重的公式,这里就不提了,它的思想主要是通过像素和像素之间的关系权重来综合考虑,根据给出的阈值,将图像一分为二。
基于CNN 的框架
这个想法也很简单,就是对图像的每一个像素点进行分类,在每一个像素点上取一个patch,当做一幅图像,输入神经网络进行训练,举个例子:
图1 DRIVE数据集的训练集眼底图像
DRIVE数据集的优点是:不仅有已经手工分好的的血管图像(在manual文件夹下,如图2所示),而且还包含有眼部轮廓的图像(在mask文件夹下,如图3所示)。

图2 DRIVE数据集的训练集手工标注血管图像

图3 DRIVE数据集的训练集眼部轮廓图像
DRIVE数据集的缺点是:显而易见,从上面的图片中可以看出,训练集只有20幅图片,可见数据量实在是少之又少。。。
所以,为了得到更好的分割效果,我们需要对这20幅图像进行预处理从而增大其数据量
2、依赖的库
- numpy >= 1.11.1
- Keras >= 2.1.0
- PIL >=1.1.7
- opencv >=2.4.10
- h5py >=2.6.0
- configparser >=3.5.0b2
- scikit-learn >= 0.17.1
3、数据读取与保存
数据集中训练集和测试集各只有20幅眼底图像(tif格式)。首先要做的第一步就是对生成数据文件,方便后续的处理。所以这里我们需要对数据集中的眼底图像、人工标注的血管图像、眼部轮廓生成数据文件。这里使用的是hdf5文件。有关hdf5文件的介绍,请参考CSDN博客(HDF5快速上手全攻略)。
4、网络解析
因为U-net网络可以针对很少的数据集来进行语义分割,比如我们这个眼球血管分割就是用了20张图片来训练就可以达到很好的效果。而且我们这种眼球血管,或者指静脉,指纹之类的提取特征或者血管静脉在U-net网络里就是一个二分类问题,大家一听,二分类对于目前的神经网络不是一件很简单的事情了吗?还有是什么可以说的。
的确目前二分类问题是没有什么难度了,只要给我足够的数据集做训练。而本文用的U-net网络来实现这个二分类就只需要二十张图片来作为数据集。大家可以看到优势所在了吧。
5、具体实现
首先我们肯定都是要对数据进行一些预处理的。
第一步
先将图像转为灰度图分别读入数组建立起一个符合我们自己的tensor的格式才好传入神经网络,这里我们是先将数据存入hdf5文件中,在开始运行的时候从文件中读入。 
#将对应的图像数据存入对应图像数组
def get_datasets(imgs_dir,groundTruth_dir,borderMasks_dir,train_test="null"):
imgs = np.empty((Nimgs,height,width,channels))
groundTruth = np.empty((Nimgs,height,width))
border_masks = np.empty((Nimgs,height,width))
for path, subdirs, files in os.walk(imgs_dir): #list all files, directories in the path
for i in range(len(files)):
#original
print("original image: " +files[i])
img = Image.open(imgs_dir+files[i])
imgs[i] = np.asarray(img)
#corresponding ground truth
groundTruth_name = files[i][0:2] + "_manual1.gif"
print("ground truth name: " + groundTruth_name)
g_truth = Image.open(groundTruth_dir + groundTruth_name)
groundTruth[i] = np.asarray(g_truth)
#corresponding border masks
border_masks_name = ""
if train_test=="train":
border_masks_name = files[i][0:2] + "_training_mask.gif"
elif train_test=="test":
border_masks_name = files[i][0:2] + "_test_mask.gif"
else:
print("specify if train or test!!")
exit()
print("border masks name: " + border_masks_name)
b_mask = Image.open(borderMasks_dir + border_masks_name)
border_masks[i] = np.asarray(b_mask)
print("imgs max: " +str(np.max(imgs)))
print("imgs min: " +str(np.min(imgs)))
assert(np.max(groundTruth)==255 and np.max(border_masks)==255)
assert(np.min(groundTruth)==0 and np.min(border_masks)==0)
print("ground truth and border masks are correctly withih pixel value range 0-255 (black-white)")
#reshaping for my standard tensors
imgs = np.transpose(imgs,(0,3,1,2))
assert(imgs.shape == (Nimgs,channels,height,width))
groundTruth = np.reshape(groundTruth,(Nimgs,1,height,width))
border_masks = np.reshape(border_masks,(Nimgs,1,height,width))
assert(groundTruth.shape == (Nimgs,1,height,width))
assert(border_masks.shape == (Nimgs,1,height,width))
return imgs, groundTruth, border_masks
if not os.path.exists(dataset_path):
os.makedirs(dataset_path)
#getting the training datasets
imgs_train, groundTruth_train, border_masks_train = get_datasets(original_imgs_train,groundTruth_imgs_train,borderMasks_imgs_train,"train")
print("saving train datasets")
write_hdf5(imgs_train, dataset_path + "DRIVE_dataset_imgs_train.hdf5")
write_hdf5(groundTruth_train, dataset_path + "DRIVE_dataset_groundTruth_train.hdf5")
write_hdf5(border_masks_train,dataset_path + "DRIVE_dataset_borderMasks_train.hdf5")
#getting the testing datasets
imgs_test, groundTruth_test, border_masks_test = get_datasets(original_imgs_test,groundTruth_imgs_test,borderMasks_imgs_test,"test")
print("saving test datasets")
write_hdf5(imgs_test,dataset_path + "DRIVE_dataset_imgs_test.hdf5")
write_hdf5(groundTruth_test, dataset_path + "DRIVE_dataset_groundTruth_test.hdf5")
write_hdf5(border_masks_test,dataset_path + "DRIVE_dataset_borderMasks_test.hdf5")
第二步
是对读入内存准备开始训练的图像数据进行一些增强之类的处理,这里对其进行了,直方图均衡化,数据标准化,并且压缩像素值到0-1,将其的一个数据符合标准正态分布。当然啦我们这个数据拿来训练还是太少的,所以我们对每张图片取patch时,除了正常的每个patch每个patch移动的取之外,我们还在数据范围内进行随机取patch,这样虽然各个patch之间会有一部分数据是相同的,但是这对于网络而言,你传入的也是一个新的东西,网络能从中提取到的特征也更多了。这一步的目的其实就是在有限的数据集中进行一些数据扩充,这也是在神经网络训练中常用的手段了。
当然了在这个过程中我们也可以随机组合小的patch来看看。
随机原图:
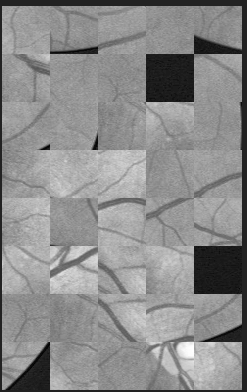
mask图:

处理待训练数据的部分代码:
def get_data_training(DRIVE_train_imgs_original,
DRIVE_train_groudTruth,
patch_height,
patch_width,
N_subimgs,
inside_FOV):
train_imgs_original = load_hdf5(DRIVE_train_imgs_original)
train_masks = load_hdf5(DRIVE_train_groudTruth) #masks always the same
# visualize(group_images(train_imgs_original[0:20,:,:,:],5),'imgs_train')#.show() #check original imgs train
train_imgs = my_PreProc(train_imgs_original) #直方图均衡化,数据标准化,压缩像素值到0-1
train_masks = train_masks/255.
train_imgs = train_imgs[:,:,9:574,:] #cut bottom and top so now it is 565*565
train_masks = train_masks[:,:,9:574,:] #cut bottom and top so now it is 565*565
data_consistency_check(train_imgs,train_masks)
#check masks are within 0-1
assert(np.min(train_masks)==0 and np.max(train_masks)==1)
print("\ntrain images/masks shape:")
print(train_imgs.shape)
print("train images range (min-max): " +str(np.min(train_imgs)) +' - '+str(np.max(train_imgs)))
print("train masks are within 0-1\n")
#extract the TRAINING patches from the full images
patches_imgs_train, patches_masks_train = extract_random(train_imgs,train_masks,patch_height,patch_width,N_subimgs,inside_FOV)
data_consistency_check(patches_imgs_train, patches_masks_train)
print("\ntrain PATCHES images/masks shape:")
print(patches_imgs_train.shape)
print("train PATCHES images range (min-max): " +str(np.min(patches_imgs_train)) +' - '+str(np.max(patches_imgs_train)))
return patches_imgs_train, patches_masks_train#, patches_imgs_test, patches_masks_test
第三步
按照U-net的网络结构,使用keras来构造出网络。这里对keras函数语法不太理解的可以看这篇博客:深度学习(六)keras常用函数学习
def get_unet(n_ch,patch_height,patch_width):
inputs = Input(shape=(n_ch,patch_height,patch_width))
conv1 = Conv2D(32, (3, 3), activation='relu', padding='same',data_format='channels_first')(inputs)
conv1 = Dropout(0.2)(conv1)
conv1 = Conv2D(32, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv1)
pool1 = MaxPooling2D((2, 2))(conv1)
#
conv2 = Conv2D(64, (3, 3), activation='relu', padding='same',data_format='channels_first')(pool1)
conv2 = Dropout(0.2)(conv2)
conv2 = Conv2D(64, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv2)
pool2 = MaxPooling2D((2, 2))(conv2)
#
conv3 = Conv2D(128, (3, 3), activation='relu', padding='same',data_format='channels_first')(pool2)
conv3 = Dropout(0.2)(conv3)
conv3 = Conv2D(128, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv3)
up1 = UpSampling2D(size=(2, 2))(conv3)
up1 = concatenate([conv2,up1],axis=1)
conv4 = Conv2D(64, (3, 3), activation='relu', padding='same',data_format='channels_first')(up1)
conv4 = Dropout(0.2)(conv4)
conv4 = Conv2D(64, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv4)
#上采样后横向拼接
up2 = UpSampling2D(size=(2, 2))(conv4)
up2 = concatenate([conv1,up2], axis=1)
conv5 = Conv2D(32, (3, 3), activation='relu', padding='same',data_format='channels_first')(up2)
conv5 = Dropout(0.2)(conv5)
conv5 = Conv2D(32, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv5)
#
conv6 = Conv2D(2, (1, 1), activation='relu',padding='same',data_format='channels_first')(conv5)
conv6 = core.Reshape((2,patch_height*patch_width))(conv6)
conv6 = core.Permute((2,1))(conv6)
############
conv7 = core.Activation('softmax')(conv6)
model = Model(inputs=inputs, outputs=conv7)
# sgd = SGD(lr=0.01, decay=1e-6, momentum=0.3, nesterov=False)
model.compile(optimizer='sgd', loss='categorical_crossentropy',metrics=['accuracy'])
return model
第四步
这里就是将我们处理好的数据传入到网络里训练了。得出结果图。
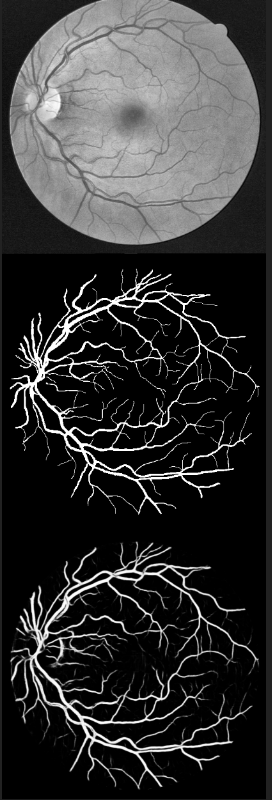
看的出来很多很细的纹理都被提取出来了,这个U-net网络也可以用于一些医学细胞的 边缘提取,指静脉,掌静脉之类的纹路提取都可以。后面在下可能还会出指静脉之类其他图像的语义分割提取,关注在下就可以看到啦hhhhhhh
因为keras内部可以直接将整个网络结构打印出来,所以我们可以看到完整的网络结构图如下所示:

用图片存储和显示keras模型的结构
深度学习(六)keras常用函数学习 |