这篇教程深度学习-神经网络模型参数选择写得很实用,希望能帮到您。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28 |
from keras import models
from keras import layers
from keras.datasets import mnist
from keras.utils import to_categorical
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# build network
network = models.Sequential()
network.add(layers.Dense(512, activation='relu', input_shape=(28 * 28, )))
network.add(layers.Dense(10, activation="softmax"))
network.compile(
optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
train_images = train_images.reshape((train_images.shape[0], 28 * 28))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((test_images.shape[0], 28 * 28))
test_images = test_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
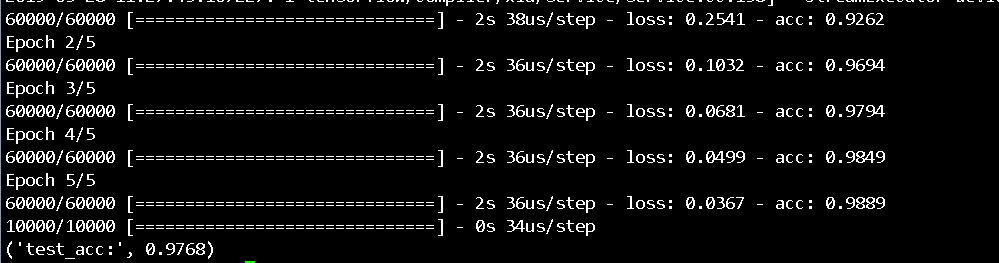
network.fit(train_images, train_labels, epochs=10, batch_size=128)
test_loss, test_acc = network.evaluate(test_images, test_labels)
print("test_acc:", test_acc) |
不过又有了新的疑问,隐藏层个数、激活函数、优化器什么什么的,都该怎么选择呢? 如何区分欠拟合、过拟合?如何调优呢?
带着种种疑问,又撸了吴恩达老师的视频,解答了一些疑问,调参的时候心里有谱了些
一、分出验证集
首先,为什么需要验证集? 如果在训练集上训练后,再根据测试集上的效果来调参,相当于间接把测试集用于训练,这对于比较模型好坏来说是不公平的~
所以从训练集中分出一部分作为验证集,通过验证集上的结果调整参数;参数调好了后,再把验证集加到训练集,得到最终的模型,用于测试集的检验。
详细来说,有三种主流的方法:
1. 简单留出验证集,一般 train_set:val_set:test_set = 6:2:2
2. K折交叉验证
如果数据量很少,随机抽出的验证集不足以衡量参数效果,则采用这种方式

3. 带有打乱数据的重复 K 折验证
如果可用的数据相对较少,而你又需要尽可能精确地评估模型,那么可以选择带有打乱数据的重复 K 折验证( iterated K-fold validation with shuffling)
即每次K折之前打算数据,重复P次,共训练 P*K个模型
二、activation,loss,metrics, optimizer,batch_size的选择
1.activation(激活函数)
为什么需要激活函数?如果隐含层不使用激活函数,那么它表达的永远都是线性关系;使用多个线性隐藏层的logistic回归与没有隐藏层的logistic回归是等价的
隐含层激活函数现在一般推荐ReLU, 如果效果不好再使用LeakyReLU, Maxout; 对于输出层,则根据神经网络的目的,比如多分类问题,就用softmax
图片转自知乎:
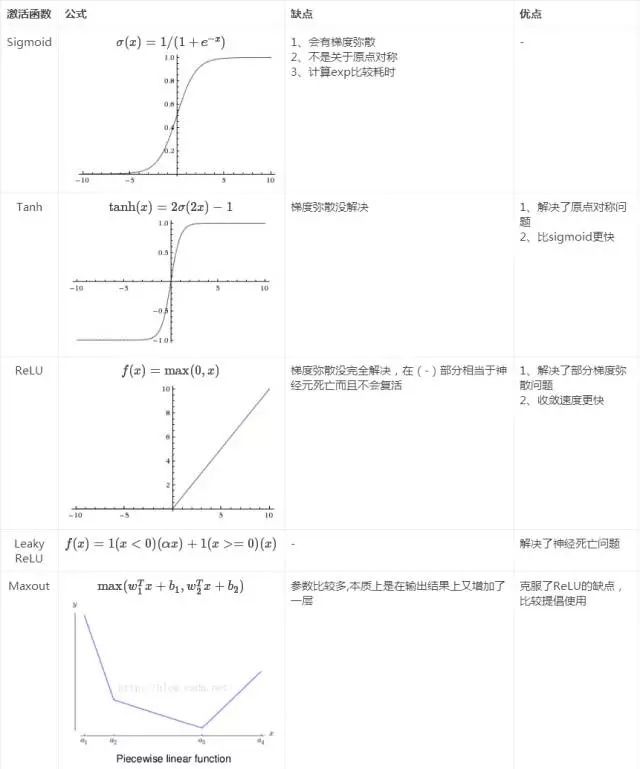
补充LeakyReLU 曲线图

2. loss(损失函数)与metrics(度量)
损失函数是神经网络训练的目标函数,度量是给人看的指标,比如准确度,mae等
二分类:binary_crossentropy(二元交叉熵) accuracy(分类器正确分类的样本数与总样本数之比)
多分类:categorical_crossentropy(多元交叉熵) accuracy
拟合: MSE(均方误差) MAE(平均绝对误差),比如预测房价与实际房价的平均偏差
二分类问题中,正负样本的数目是有很大偏差的,需要用P指标、R指标评估模型
如0.1% 的样本是癌症样本,如果模型直接预测100%样本是正常的,此时模型准确是 99.99%
精确率(precision) 所有"正确被检索的结果(TP)"占所有"实际被检索到的(TP+FP)"的比例
召回率(recall) 所有"正确被检索的结果(TP)"占所有"应该检索到的结果(TP+FN)"的比例
显然,P指标和R指标会出现矛盾的情况,这时我们用F1度量来综合评价模型结果。F1越大,效果越好

3. optimizer(权值更新算法) 与 batch_size
多是基于BP算法的优化,现一般推荐使用 rmsprop
batch_size 一般取2的幂,利于CPU并行处理
四. 过拟合、欠拟合处理
初始网络:
- 一般而言是一个隐藏层
- 如果采用多个隐藏层,每个隐藏层的数目是相等的
欠拟合的表现:训练集、验证集上的损失都没有降低
过拟合的表现:训练集损失很小,验证集上损失在增大
扩大训练集---------------------> underfitting
增加特征-----------------------> underfitting
减少特征-----------------------> overfitting
减少隐含层层数、隐含层节点-----> overfitting
减少正则系数λλ----------> underfitting
增大正则系数λλ----------> overfitting
利用keras加载训练好的.H5文件,并预测图片
Keras RAdam |