这篇教程从Sigmoid到GELU,一文概览神经网络激活函数写得很实用,希望能帮到您。
从Sigmoid到GELU,一文概览神经网络激活函数原文:https://zhuanlan.zhihu.com/p/450136840
神经网络得益于强大的非线性拟合能力,可以自动完成特征提取工作,在NLP、CV、ASR、推荐、搜索等领域发挥了广泛的应用。
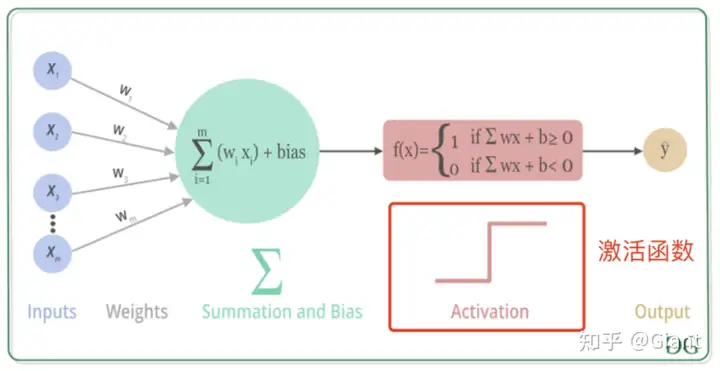
这里的拟合能力,主要来自于非线性激活函数。
最近我总结了7个深度学习训练中常用的激活函数,并对它们的特点和优劣做了整理。激活函数也是算法面试中常考主题,建议同学们提前收藏备需!
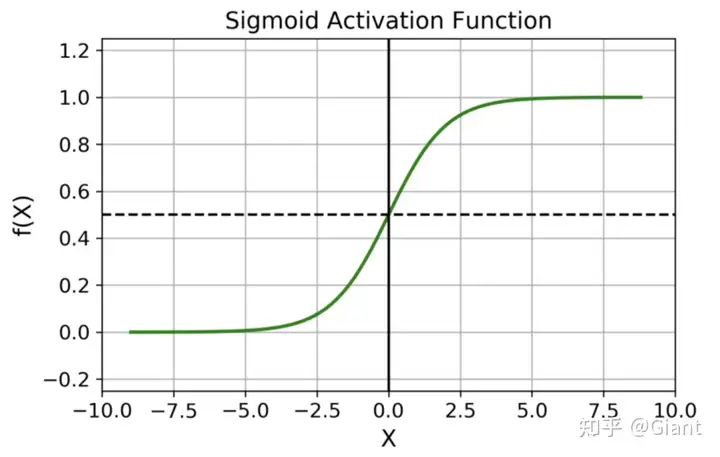
1.sigmoid
sigmoid 是最基础的激活函数,可以将任意数值转换为概率(缩放到0~1之间),在分类等场景中有广泛的应用。
sigmoid的公式也非常简洁优雅:
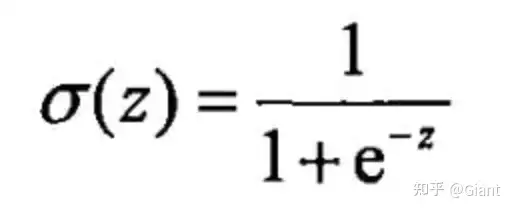
主要优点:
- 函数的映射范围是 0 到 1,对每个神经元的输出进行了归一化
- 梯度平滑,避免「跳跃」的输出值
- 函数是可微的,意味着可以找到任意两个点的 sigmoid 曲线的斜率
- 预测结果明确,即非常接近 1 或 0
缺点:
- 倾向于梯度消失
- 函数输出不是以 0 为中心的,会降低权重更新的效率
- Sigmoid 函数执行指数运算,计算机运行得较慢
2.Tanh 双曲正切激活函数
激活函数Tanh和sigmoid类似,都是 S 形曲线,输出范围是[-1, 1]。
在一般的二元分类问题中,tanh 函数常用于隐藏层,sigmoid 用于输出层,但这并不是固定的,需要根据特定问题进行调整。
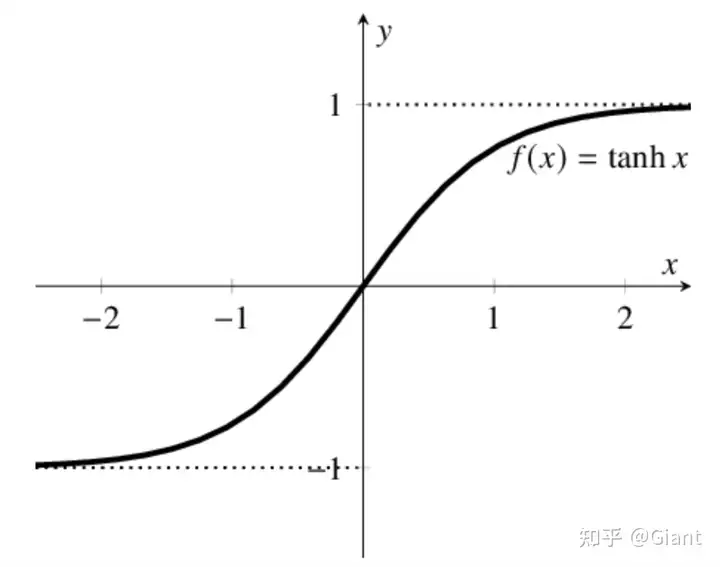
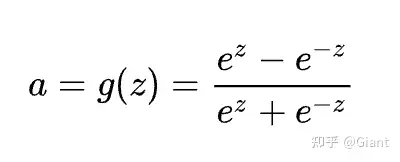
相比sigmoid,tanh的优势在于:
- tanh 的输出间隔为 1,并且整个函数以 0 为中心,比 sigmoid 函数更好
- 在负输入将被强映射为负,而零输入被映射为接近零。
缺点:
- 当输入较大或较小时,输出几乎是平滑的并且梯度较小,这不利于权重更新
- 依然存在指数计算量大的问题
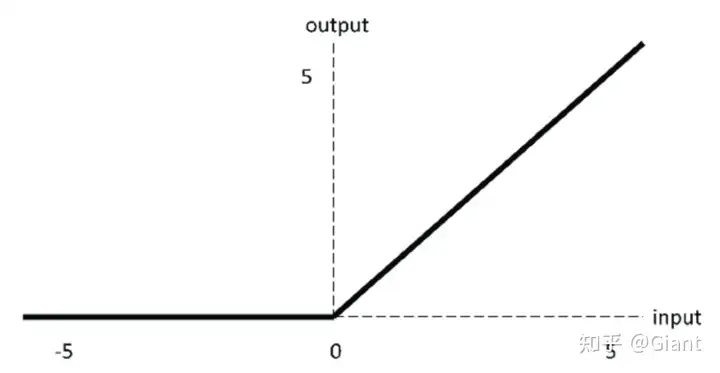
3.ReLU 整流线性单元
Relu也是深度学习中非常流行的激活函数,近两年大火的Transformer模块由Attention和前馈神经网络FFN组成,其中FFN(即全连接)又有两层,第一层的激活函数就是ReLU,第二层是一个线性激活函数。
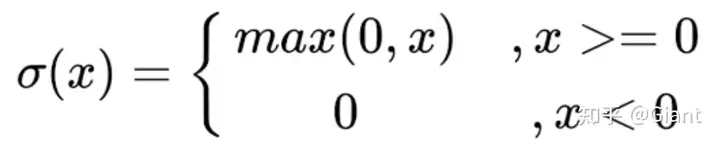
相比sigmoid和tanh,它具有以下优点:
- 当输入为正时,不存在梯度饱和问题
- 计算复杂度低。ReLU 函数只存在线性关系,一个阈值就可以得到激活值
- 单侧抑制,可以对神经元进行筛选,让模型训练更加鲁棒
当然它也存在缺点:
- dead relu 问题(神经元坏死现象)。relu在训练的时很“脆弱”。在x<0时,梯度为0,这个神经元及之后的神经元梯度永远为0,不再对任何数据有所响应,导致相应参数永远不会被更新
- 解决方法:采用Xavier初始化方法,以及避免将learning rate设置太大或使用adagrad等自动调节learning rate的算法。
- 输出不是 0 均值
4.Leaky ReLU 渗漏整流线性单元
为了解决dead relu问题,Leaky relu用一个类似0.01的小值来初始化神经元,从而使得relu在负数区域更偏向于激活而不是坏死,这里的斜率都是确定的。
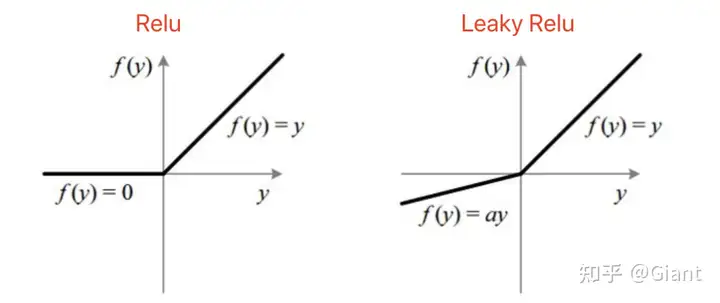
从理论上讲,Leaky ReLU 具有 ReLU 的所有优点,但在实际中尚未完全证明 Leaky ReLU 总是比 ReLU 更好。
5.ELU 指数线形单元
ELU 的提出也解决了 ReLU 的问题。与 ReLU 相比,ELU 有负值,这会使激活的平均值接近零,让模型学习得更快。
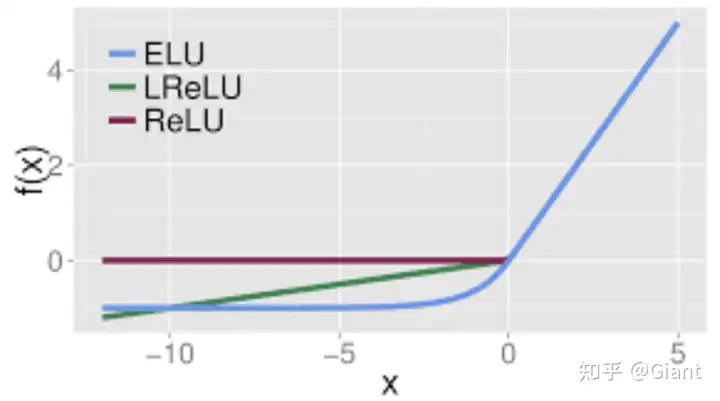
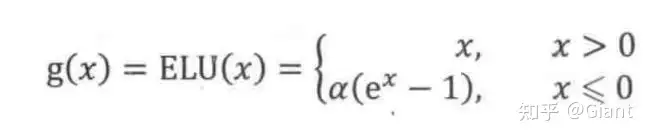
其中a不是固定的,是通过反向传播学习出来的。ELU的一个小问题是需要exp计算,运算量会更大一些。
6.GELU 高斯误差线性单元
激活函数GELU的灵感来源于 relu 和 dropout,在激活中引入了随机正则的思想。gelu通过输入自身的概率分布情况,决定抛弃还是保留当前的神经元。
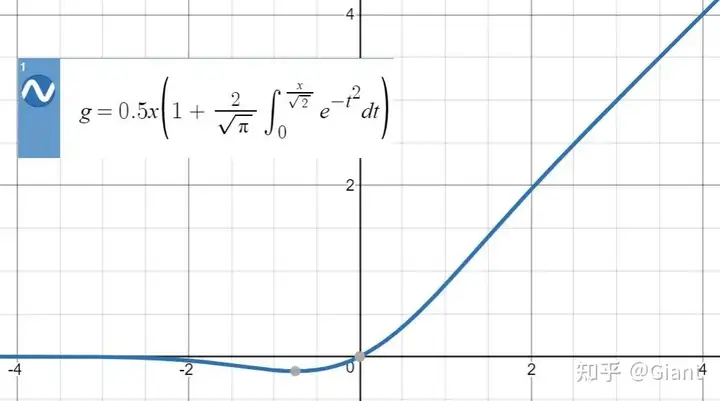
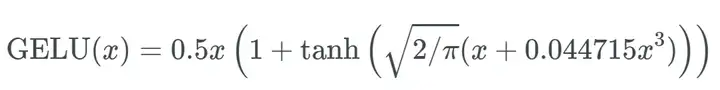
可以理解为,对于输入的值,根据它的情况乘上 1 或 0。更「数学」一点的描述是,对于每一个输入 x,其服从于标准正态分布 N(0, 1),它会乘上一个伯努利分布 Bernoulli(Φ(x)),其中Φ(x) = P(X ≤ x)。
随着 x 的降低,它被归零的概率会升高。对于 ReLU 来说,这个界限就是 0,输入少于零就会被归零。这一类激活函数,不仅保留了概率性,同时也保留了对输入的依赖性。
gelu在最近的Transformer模型中(包括BERT,RoBertA和GPT2等)得到了广泛的应用。
优点:
- 似乎是 NLP 领域的当前最佳;尤其在 Transformer 模型中表现最好
- 能避免梯度消失问题。
7.Maxout
激活函数本质上可以作为一个激活层来使用,而maxout相对来说更灵活,直接将激活层的部分替换为一个新的隐层结构,简单粗暴点说就是用一个隐层来作为激活函数,而这个隐层的神经元个数(maxout的参数k)可以人工指定。
比如指定参数k=5,maxout层就如下所示:
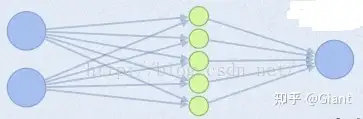
相当于在每个输出神经元前面又多了一层。这一层有5个神经元,此时maxout网络的输出计算公式为:

这就是为什么采用maxout的时候,参数个数成k倍增加的原因。本来只需要一组参数就够了,采用maxout后,就需要有k组参数。
Maxout是通过分段线性函数来拟合所有可能的凸函数来作为激活函数的,但是由于线性函数是可学习,所以实际上是可以学出来的激活函数。具体操作是对所有线性取最大,也就是把若干直线的交点作为分段的边界,然后每一段取最大。
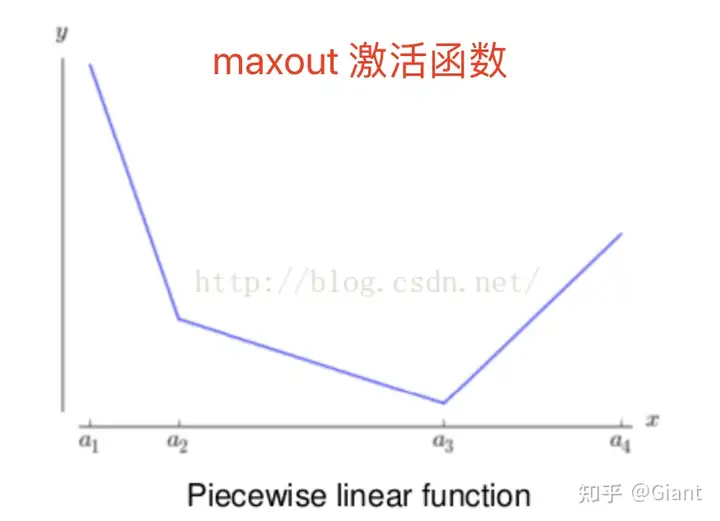
maxout 具有以下优点:
- Maxout的拟合能力非常强,可以拟合任意的凸函数
- 具有ReLU的所有优点,线性、不饱和性
- 不会出现神经元坏死的现象。
缺点:增加了参数量。显然这计算量太大了。常规的激活函数就只是单纯的函数而已,而maxout还需要反向传播去更新它自身的权重系数。。
以上就是深度学习领域常用的非线性激活函数,你都掌握了吗?
返回列表
keras中的深度可分离卷积 SeparableConv2D与DepthwiseConv2D |