这篇教程Escaping the Big Data Paradigm with Compact Transformers写得很实用,希望能帮到您。
Escaping the Big Data Paradigm with Compact Transformers

作者单位:俄勒冈大学, UIUC, PAIR
代码:https://github.com/SHI-Labs/Compact-Transformers
论文:https://arxiv.org/abs/2104.05704
随着Transformers成为语言处理标准的兴起,以及它们在计算机视觉方面的进步以及前所未有的规模和数量的训练数据,许多人开始认为它们不适用于少量数据。这种趋势引起了极大的关注,包括但不限于:在某些科学领域中数据的可用性有限,并且从该领域的研究中排除了那些资源有限的数据。
在本文中,我们消除了这样的误解【Transformer是“数据饥渴的(data hungry)”,因此只能应用于大型数据集】。我们首次证明,通过正确的大小和tokenization,Transformer可以在小型数据集上与最新的CNN肩并肩。
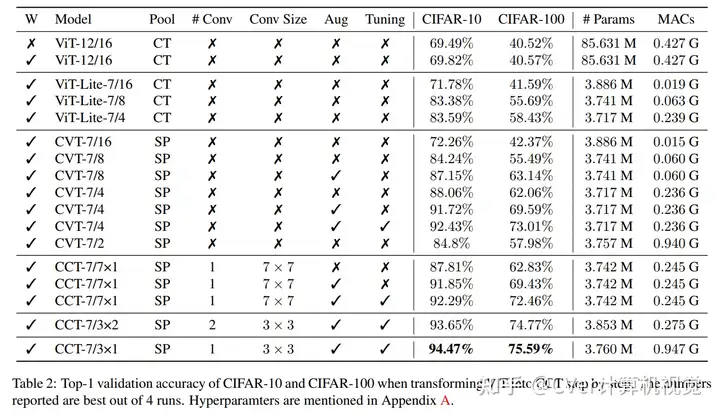
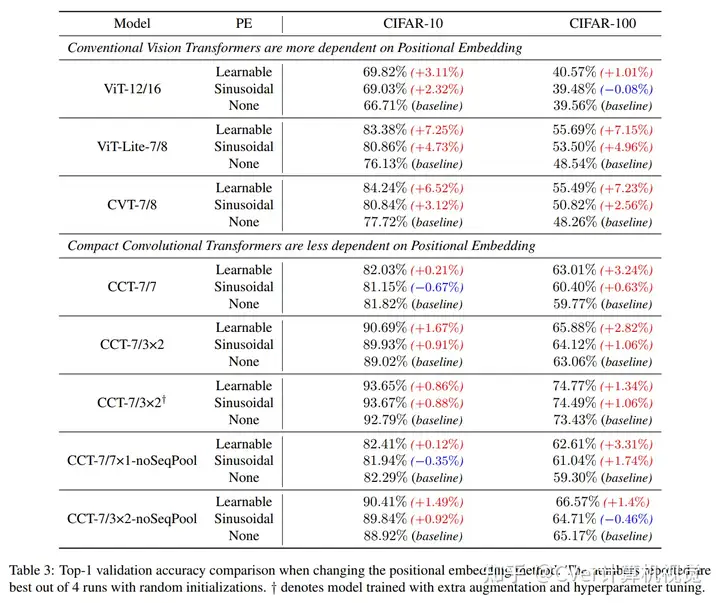
我们的模型通过一种新颖的序列合并策略和卷积的使用,消除了对类标记和位置嵌入的需求。我们表明,与CNN相比,我们的紧凑型Transformer具有更少的参数和MAC,同时获得了相似的精度。
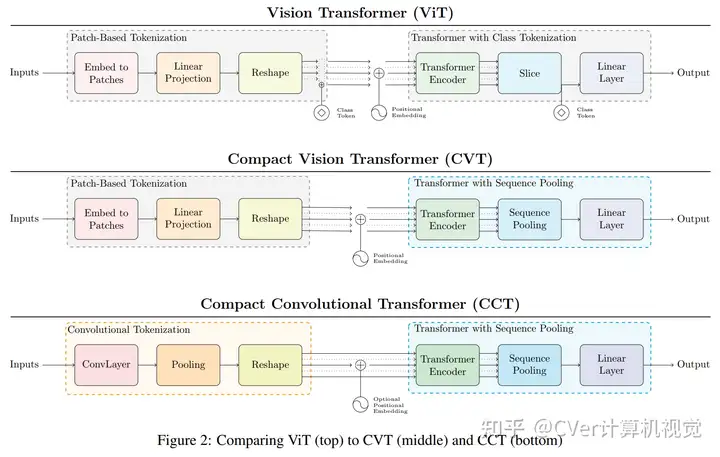
其中的CCT网络:
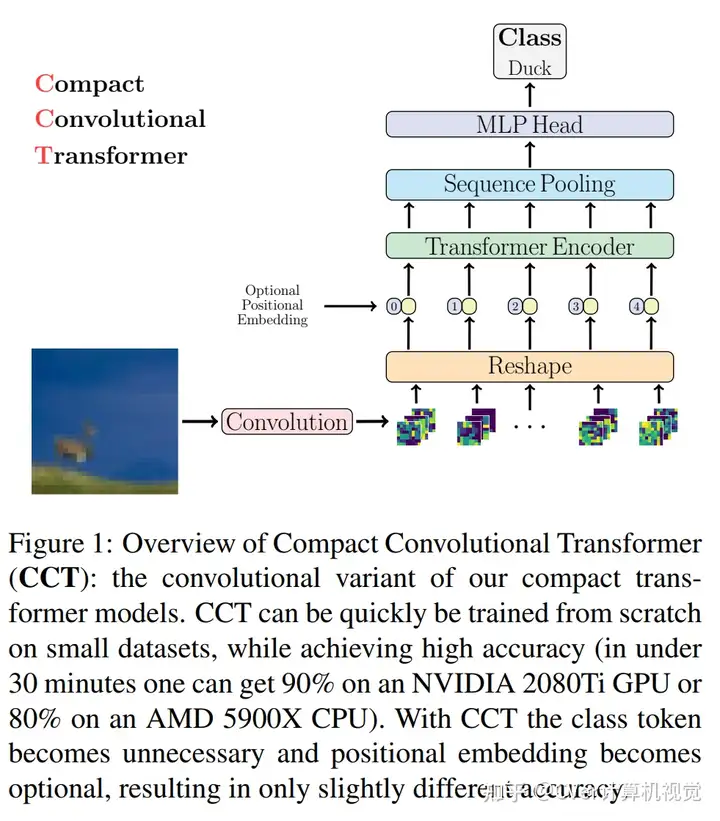

CCT vs CVT
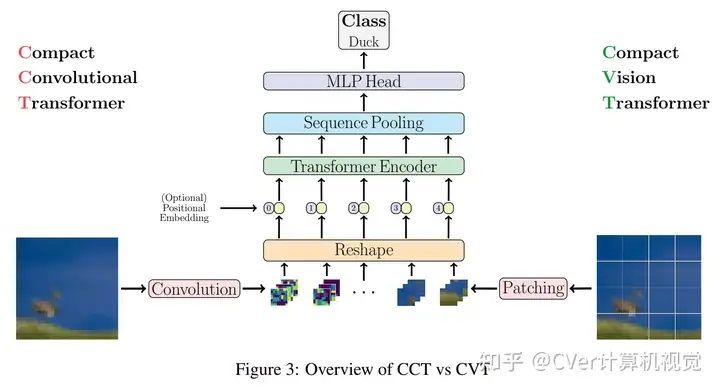
我们的方法在模型大小方面很灵活,可以拥有0.28M的参数,并且可以获得合理的结果。
从头开始在CIFAR-10上进行训练时,它可以达到94.72%的准确性,这与基于现代CNN的方法相当,并且比以前基于Transformer的模型有了显著改进。

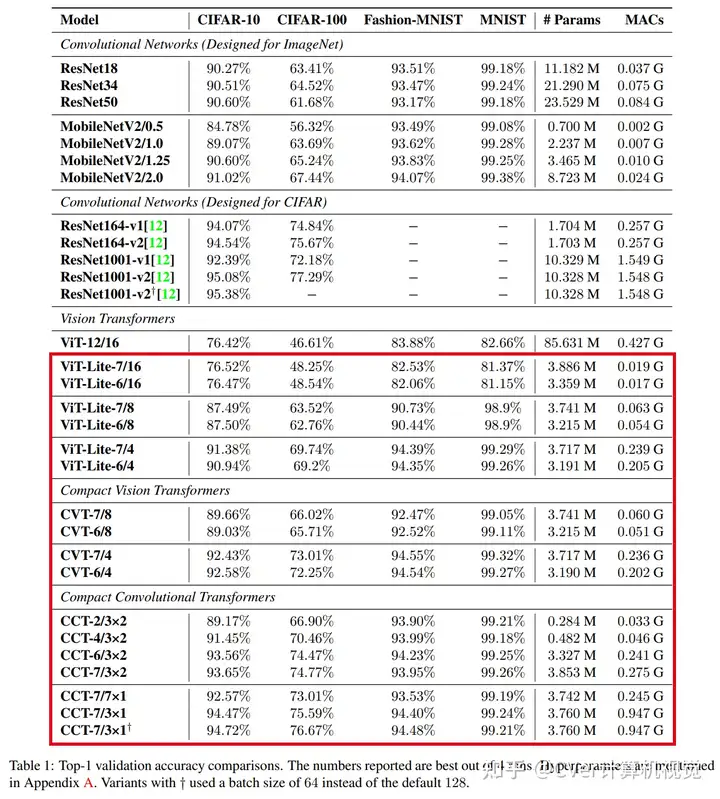
我们简单而紧凑的设计使配备基本计算资源和/或处理小型数据集的人员可以访问它们,从而使Transformer"民用化"。
CVer-Transformer交流群
建了CVer-Transformer交流群!想要进Transformer学习交流群的同学,可以直接加微信号:CVer9999。加的时候备注一下:Transformer+学校/公司+昵称,即可。然后就可以拉你进群了。
强烈推荐大家关注CVer知乎账号和CVer微信公众号,可以快速了解到最新优质的CV论文。
推荐阅读
CNN再助力!LocalViT:将Locality带入视觉Transformer
时隔三年半再升级!CondenseNet V2:深度网络的稀疏特征重新激活 | CVPR 2021
CVPR 2021 | 新视觉任务:宽范围图像融合
涨点神器!InAugment:通过内部增广来改进分类器
吸取CNN优点!LeViT:用于快速推理的视觉Transformer
SiT:自监督视觉Transformer
MoCo v3来了!何恺明等人新作:训练自监督视觉Transformer的实证研究
涨点神器!BA2M:用于视觉任务的Batch感知注意力模块
屠榜多目标跟踪!STGT:基于时空图Transformer的多目标跟踪
EfficientNetV2震撼发布!更小的模型,更快的训练
Github 深度学习资料大全 Awesome Deep Learning
CVPR 2022 论文开源目录 |