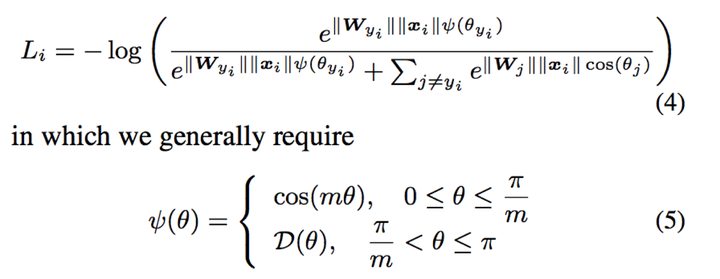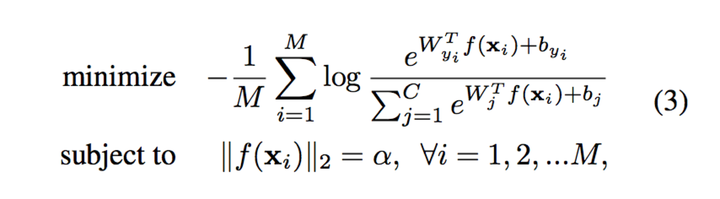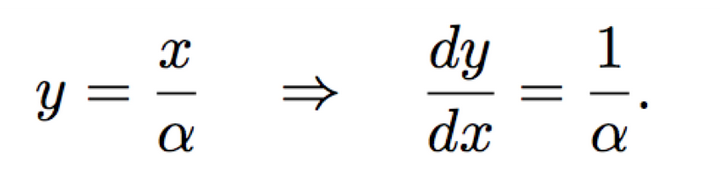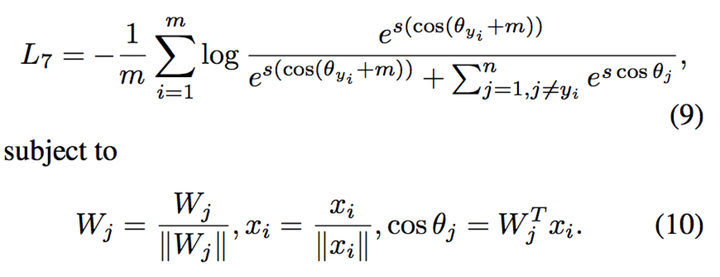这篇教程softmax loss综述一文道尽softmax loss及其变种写得很实用,希望能帮到您。1 softmax loss softmax loss是我们最熟悉的loss之一,在图像分类和分割任务中都被广泛使用。Softmax loss是由softmax和交叉熵(cross-entropy loss)loss组合而成,所以全称是softmax with cross-entropy loss,在caffe,tensorflow等开源框架的实现中,直接将两者放在一个层中,而不是分开不同层,可以让数值计算更加稳定,因为正指数概率可能会有非常大的值。
这里我们将其数学推导一起回顾一遍。
令z是softmax层的输入,f(z)是softmax的输出,则
单个像素i的softmax%20loss等于cross-entropy%20error如下:
展开上式:
在caffe实现中,z即bottom%20blob,l(y,z)是top%20blob,反向传播时,就是要根据top%20blob%20diff得到bottom%20blob%20diff,所以要得到
下面求loss对z的第k个节点的梯度
可见,传给groundtruth%20label节点和非groundtruth%20label节点的梯度是不一样的。
我们看看caffe中Backward的代码。
Dtype*%20bottom_diff%20=
bottom[0]->mutable_cpu_diff();
const%20Dtype*%20prob_data%20=%20prob_.cpu_data();
caffe_copy(prob_.count(),%20prob_data,
bottom_diff);
const%20Dtype*%20label%20=
bottom[1]->cpu_data();
int%20dim%20=%20prob_.count()%20/%20outer_num_;
int%20count%20=%200;
for%20(int%20i%20=%200;%20i%20<%20outer_num_;%20++i)%20{
%20%20%20%20for%20(int%20j%20=%200;%20j%20<%20inner_num_;%20++j)%20{
%20%20%20%20%20%20%20%20const%20int%20label_value%20=
%20%20%20%20%20%20%20%20static_cast<int>(label[i%20*%20inner_num_%20+%20j]);
%20%20%20%20%20%20%20%20if%20(has_ignore_label_%20&&%20label_value%20==%20ignore_label_)%20{
%20%20%20%20%20%20%20%20%20%20%20%20for%20(int%20c%20=%200;%20c%20<bottom[0]->shape(softmax_axis_);%20++c)%20{
%20%20%20%20%20%20%20%20%20%20%20%20%20bottom_diff[i%20*%20dim%20+%20c%20*inner_num_%20+%20j]%20=%200;
%20%20%20%20%20%20%20%20%20%20%20%20%20}
%20%20%20%20%20%20%20%20}else
%20%20%20%20%20%20%20%20{
%20%20%20%20%20%20%20%20%20%20%20bottom_diff[i%20*%20dim%20+%20label_value%20*%20inner_num_%20+%20j]%20-=%201;
%20%20%20%20%20%20%20%20%20%20%20++count;
%20%20%20%20%20%20%20%20}
%20%20%20%20}
}
作为loss层,很有必要测试一下,测试分两块,forward和backward,我们看看caffe中的代码。
Test_softmax_with_loss_layer.cpp
Forward测试是这样的,定义了个bottom%20blob%20data和bottom%20blob%20label,给data塞入高斯分布数据,给label塞入0~4。
blob_bottom_data_(new%20Blob<Dtype>(10,%205,%202,%203))
blob_bottom_label_(new%20Blob<Dtype>(10,%201,%202,%203))
然后分别ingore其中的一个label做5次,最后比较,代码如下。
Dtype%20accum_loss%20=%200;
for%20(int%20label%20=%200;%20label%20<%205;%20++label)%20{
%20%20%20%20layer_param.mutable_loss_param()->set_ignore_label(label);
%20%20%20%20layer.reset(new%20SoftmaxWithLossLayer<Dtype>(layer_param));
%20%20%20%20layer->SetUp(this->blob_bottom_vec_,this->blob_top_vec_);
%20%20%20%20layer->Forward(this->blob_bottom_vec_,%20this->blob_top_vec_);
%20%20%20%20accum_loss%20+=%20this->blob_top_loss_->cpu_data()[0];
}
//%20Check%20that%20each%20label%20was%20included%20all%20but%20once.
EXPECT_NEAR(4%20*%20full_loss,%20accum_loss,%201e-4);
至于backwards,直接套用checker.CheckGradientExhaustive就行,它自己会利用数值微分的方法和你写的backwards来比较精度。
TYPED_TEST(SoftmaxWithLossLayerTest,
TestGradientIgnoreLabel)%20{
%20%20%20%20typedef%20typename%20TypeParam::Dtype%20Dtype;
%20%20%20%20LayerParameter%20layer_param;
%20%20%20%20//labels%20are%20in%20{0,%20...,%204},%20so%20we'll%20ignore%20about%20a%20fifth%20of%20them
%20%20%20%20layer_param.mutable_loss_param()->set_ignore_label(0);
%20%20%20%20SoftmaxWithLossLayer<Dtype>%20layer(layer_param);
%20%20%20%20GradientChecker<Dtype>%20checker(1e-2,%201e-2,%201701);
%20%20%20%20checker.CheckGradientExhaustive(&layer,%20this->blob_bottom_vec_,this->blob_top_vec_,%200);
}
原始的softmax%20loss非常优雅,简洁,被广泛用于分类问题。它的特点就是优化类间的距离非常棒,但是优化类内距离时比较弱 。
鉴于此,就有了很多对softmax%20loss的改进,下面一一道来。
2%20weighted%20softmax%20loss【1】 假如有一个二分类问题,两类的样本数目差距非常之大。比如图像任务中的边缘检测问题,它可以看作是一个逐像素的分类问题。此时两类的样本数目差距非常之大,明显边缘像素的重要性是比非边缘像素大的,此时可以针对性的对样本进行加权。
wc就是这个权重,像刚才所说,c=0代表边缘像素,c=1代表非边缘像素,则我们可以令w0=1,w1=0.001,即加大边缘像素的权重。
当然,这个权重,我们还可以动态地计算让其自适应。比如每一张图中,按照像素的比例进行加权。
具体的反向公式推导,就跟上面差不多不再赘述,详细的实现我会在git中给出代码。【1】中用了weighted%20sigmoid_cross_entropy_loss,原理类似。
固定权重的fixed%20softmax%20loss和自适应权重的adapted%20softmax%20loss大家可以去git中自行查看。
何提出的Focal%20loss【10】其实就是加权log%20loss的一个变种,它的定义如下
上面式子对正负样本进行了分开的表达,f(x)就是属于标签1的概率。
focal loss是针对类别不均衡问题提出的,它可以通过减少易分类样本的权重,使得模型在训练时更专注于难分类的样本,其中就是通过调制系数
对于类别1的样本,当f(x)越大,则调制项因为此时基于该样本是一个容易样本的假设,所以给予其更小的loss贡献权重。通过 的设置,可以获得自适应地对难易样本进行学习的能力。
3%20soft%20softmax%20loss【2】 首先我们看下面的式子。
当T=1时,就是softmax的定义,当T>1,就称之为soft%20softmax,T越大,因为Zk产生的概率差异就会越小。文【2】中提出这个是为了迁移学习,生成软标签,然后将软标签和硬标签同时用于新网络的学习。
为什么要想到这么用,这是因为当训练好一个模型之后,模型为所有的误标签都分配了很小的概率;然而实际上对于不同的错误标签,其被分配的概率仍然可能存在数个量级的悬殊差距。这个差距,在softmax中直接就被忽略了,但这其实是一部分有用的信息。
文章的做法是先利用softmaxloss训练获得一个大模型,然后基于大模型的softmax输出结果获取每一类的概率,将这个概率,作为小模型训练时soft%20target的label。
4%20Large-Margin%20Softmax%20Loss【3】 softmax loss擅长于学习类间的信息,因为它采用了类间竞争机制,它只关心对于正确标签预测概率的准确性,忽略了其他非正确标签的差异,导致学习到的特征比较散。文【3】中提出了Large-Margin Softmax Loss,简称为L-Softmax loss。
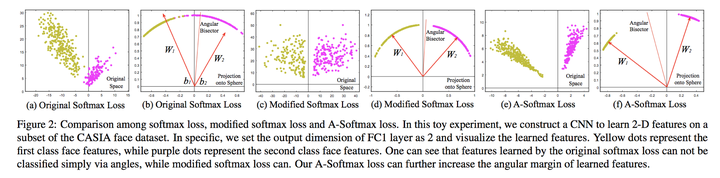
我们先从一张图来理解下softmax loss,这张图显示的是不同softmax loss和L-Softmax loss学习到的cnn特征分布。第一列就是softmax,第2列是L-Softmax loss在参数m取不同值时的分布。通过可视化特征可知学习到的类间的特征是比较明显的,但是类内比较散。而large-margin softmax loss则类内更加紧凑,怎么做到的呢?
先看一下loss的定义形式如下。
由于 是全连接层的输出,所以它可以写成 的形式,将内积更具体的表现出来,就是 。
我们看二分类的情况,对于属于第1类的样本,我们希望
如果我们对它提出更高的要求呢?由于cos函数在0~PI区间是递减函数,我们将要求改为
其中m>=1, ,
在这个条件下,原始的softmax条件仍然得到满足。
我们看下图,如果W1=W2,那么满足条件2,显然需要θ1与θ2之间的差距变得更大,原来的softmax的decision%20boundary只有一个,而现在类别1和类别2的decision%20boundary不相同,这样类间的距离进一步增加,类内更近紧凑。
更具体的定义如下:
L-Softmax loss中,m是一个控制距离的变量,它越大训练会变得越困难,因为类内不可能无限紧凑。
作者的实现是通过一个LargeMargin全连接层+softmax loss来共同实现,可参考代码。
5 angular softmax loss【4】 在人脸分类任务中,如果在large margin softmax loss的基础上添加了限制条件||W||=1和b=0,使得预测仅取决于W和x之间的角度θ,则得到了angular softmax loss,简称A-softmax loss。
上图分别比较了原softmax loss,原softmax loss添加||w||=1约束,以及在L-softmax loss基础上添加||w||=1约束的结果。
为什么要添加|w|=1的约束呢? 作者做了两方面的解释,一个是softmax loss学习到的特征,本来就依据角度有很强的区分度,另一方面,人脸是一个比较规整的流形,将其特征映射到超平面表面,也可以解释。
6 L2-constrained softmax loss【5】与NormFace【6】 在A-softmax中,对权重进行了归一化的约束,那么,特征是否也可以做归一化的约束呢?作者观测到好的正面的脸,特征的L2-norm大,而特征不明显的脸,其对应的特征L2-norm小,这不利于人脸聚类,因此提出这样的约束来增强特征的区分度。
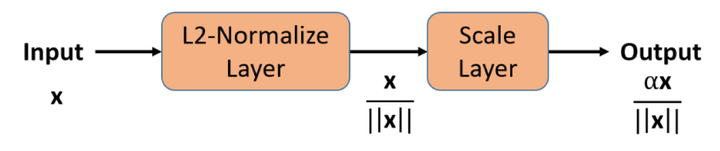
上面式就是将其归一化到固定值α。实际训练的时候都不需要修改代码,只需要添加L2-norm层与scale层,如下图。
为什么要加这个scale层?NormFace【6】中作出了解释。
该文章指出了直接归一化权重和特征,会导致loss不能下降。因为就算是极端情况下,多类样本,令正样本|wx|=1取最大值,负样本|wx|=-1取最小值,这时候分类概率也是
当类别数n=10,p=0.45;n=1000,p=0.007。当类别数增加到1000类时,正样本最大的概率还不足0.01,而反向求导的时候,梯度=1-p,会导致一直传回去很大的loss。
所以,有必要在后面加上scale层,作者还计算出了该值的下界,具体可自行参考。特征归一化后,人脸识别计算特征向量的相似度时,不管使用L2距离还是使用cos距离,都是等价的,计算量也相同,所以再也不用纠结到底用L2距离还会用cos距离。权值和特征归一化使得CNN更加集中在优化夹角上,得到的深度人脸特征更加分离。
7%20large%20margin%20cosine%20margin【7】与additive%20margin%20softmax%20loss【8】 与L-softmax%20loss和A-softmax%20loss不同,CosineFace直接在余弦空间中最大化分类界限,定义如下;
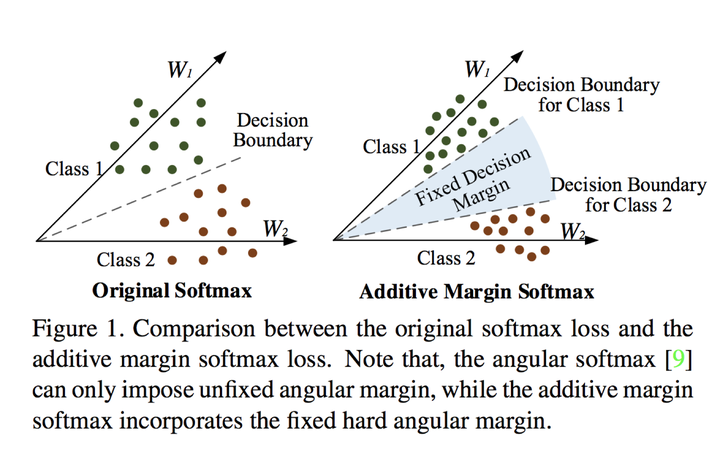
cosine loss就是把L-Softmax的乘法改成了减法,同时加上了尺度因子s,特征和权值都被归一化,AM-softmax loss和cosine loss是一样的。
它们相比soft Max loss,L-softmax loss等,更加明确地约束了角度,使得特征更加具有可区分度。作者这样改变之后前向后向传播变得更加简单,AM-softmax loss作者在论文中将m设为0.35。
值得注意的是,normalization是收敛到好的点的保证,同时,必须加上scale层,scale的尺度在文中被固定设置为30。
那到底什么时候需要normalization什么时候又不需要呢?这实际上依赖于图片的质量。
我们看一个公式如下
其中α就是向量x的模,它说明模值比较小的,会有更大的梯度反向传播误差系数,这实际上就相当于难样本挖掘了。不过,也要注意那些质量非常差的,模值太小可能会造成梯度爆炸的问题。
8 和 additive angular margin loss【9】 additive angular margin loss【9】则将m的减号换成了加号,并提到了括号内。
定义如下:
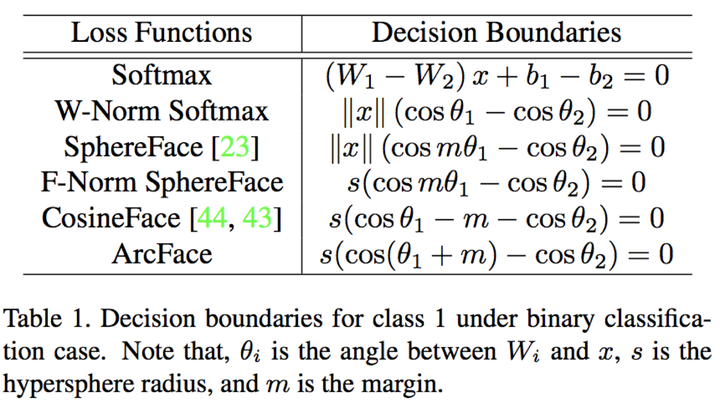
在定义这个loss的时候,作者干脆做了一个表把现有基于softmax loss及其改进的loss的二分类决策边界条件都列了出来。
到此可以说为了改进softmax loss用尽了手段了,至于有没有用,具体效果大家去尝试吧,附上未完整的GitHub链接。先写到这里,后续再充实实验结果和更多原理。
longpeng2008/Caffe_Longgithub.com
【1】Xie S, Tu Z.Holistically-nested edge detection[C]//Proceedings of the IEEE international conference on computer vision. 2015: 1395-1403.
【2】Hinton G,Vinyals O, Dean J. Distilling the knowledge in a neural network[J]. arXiv
【3】Liu W, Wen Y,Yu Z, et al. Large-Margin Softmax Loss for Convolutional Neural
【4】Liu W, Wen Y,Yu Z, et al. Sphereface: Deep hypersphere embedding for face
【5】Ranjan R, Castillo C D, Chellappa R. L2-constrained softmax loss for discriminative face verification[J]. arXiv preprint arXiv:1703.09507, 2017.
【6】Wang F, Xiang X, Cheng J, et al. NormFace: $ L_2 $ Hypersphere Embedding for Face Verification[J]. arXiv preprint arXiv:1704.06369, 2017.
【7】Wang H, Wang Y, Zhou Z, et al. CosFace: Large margin cosine loss for deep face recognition[J]. arXiv preprint arXiv:1801.09414, 2018.
【8】Wang F, Liu W,Liu H, et al. Additive Margin Softmax for Face Verification[J]. arXiv preprint arXiv:1801.05599, 2018.
【9】Deng J, Guo J, Zafeiriou S. ArcFace: Additive Angular Margin Loss for Deep Face
【10】Lin T Y, Goyal P, Girshick R, et al. Focal loss for dense object detection[J]. IEEE transactions on pattern analysis and machine intelligence, 2018.
Keras中自定义目标函数(损失函数) 人脸识别技术技术资料参考