这篇教程deep Learning 最优化方法RMSProp详解写得很实用,希望能帮到您。
先上结论
1.AdaGrad算法的改进。鉴于神经网络都是非凸条件下的,RMSProp在非凸条件下结果更好,改变梯度累积为指数衰减的移动平均以丢弃遥远的过去历史。
2.经验上,RMSProp被证明有效且实用的深度学习网络优化算法。
相比于AdaGrad的历史梯度:
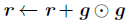 RMSProp增加了一个衰减系数来控制历史信息的获取多少: RMSProp增加了一个衰减系数来控制历史信息的获取多少:
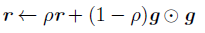
再看原始的RMSProp算法:

再看看结合Nesterov动量的RMSProp,直观上理解就是:
RMSProp改变了学习率,Nesterov引入动量改变了梯度,从两方面改进更新方式。

深度学习中的Momentum算法原理
深度学习: 指数加权平均 |