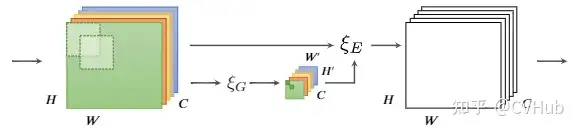
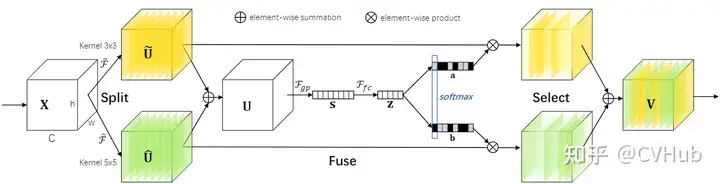
class SKConv(nn.Module):
def __init__(self, features, M=2, G=32, r=16, stride=1, L=32):
""" Constructor
Args:
features: input channel dimensionality.
M: the number of branchs.
G: num of convolution groups.
r: the ratio for compute d, the length of z.
stride: stride, default 1.
L: the minimum dim of the vector z in paper, default 32.
"""
super(SKConv, self).__init__()
d = max(int(features/r), L)
self.M = M
self.features = features
self.convs = nn.ModuleList([])
for i in range(M):
self.convs.append(nn.Sequential(
nn.Conv2d(features, features, kernel_size=3, stride=stride, padding=1+i, dilation=1+i, groups=G, bias=False),
nn.BatchNorm2d(features),
nn.ReLU(inplace=False)
))
self.gap = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Sequential(nn.Conv2d(features, d, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(d),
nn.ReLU(inplace=False))
self.fcs = nn.ModuleList([])
for i in range(M):
self.fcs.append(
nn.Conv2d(d, features, kernel_size=1, stride=1)
)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
batch_size = x.shape[0]
feats = [conv(x) for conv in self.convs]
feats = torch.cat(feats, dim=1)
feats = feats.view(batch_size, self.M, self.features, feats.shape[2], feats.shape[3])
feats_U = torch.sum(feats, dim=1)
feats_S = self.gap(feats_U)
feats_Z = self.fc(feats_S)
attention_vectors = [fc(feats_Z) for fc in self.fcs]
attention_vectors = torch.cat(attention_vectors, dim=1)
attention_vectors = attention_vectors.view(batch_size, self.M, self.features, 1, 1)
attention_vectors = self.softmax(attention_vectors)
feats_V = torch.sum(feats*attention_vectors, dim=1)
return feats_V
SPA-Net[14]
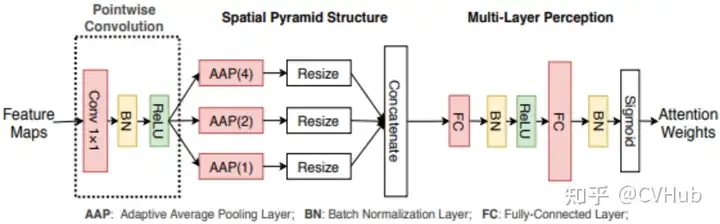
《Spatial Pyramid Attention Network for Enhanced Image Recognition》 发表于ICME 2020 并获得了最佳学生论文。考虑到 SE-Net 这种利用 GAP 去建模全局上下文的方式会导致空间信息的损失,SPA-Net另辟蹊径,利用多个自适应平均池化(Adaptive Averatge Pooling, APP) 组成的空间金字塔结构来建模局部和全局的上下文语义信息,使得空间语义信息被更加充分的利用到。
class CPSPPSELayer(nn.Module):
def __init__(self,in_channel, channel, reduction=16):
super(CPSPPSELayer, self).__init__()
if in_channel != channel:
self.conv1 = nn.Sequential(
nn.Conv2d(in_channel, channel, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(channel),
nn.ReLU(inplace=True)
)
self.avg_pool1 = nn.AdaptiveAvgPool2d(1)
self.avg_pool2 = nn.AdaptiveAvgPool2d(2)
self.avg_pool4 = nn.AdaptiveAvgPool2d(4)
self.fc = nn.Sequential(
nn.Linear(channel*21, channel*21 // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel*21 // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
x = self.conv1(x) if hasattr(self, 'conv1') else x
b, c, _, _ = x.size()
y1 = self.avg_pool1(x).view(b, c) # like resize() in numpy
y2 = self.avg_pool2(x).view(b, 4 * c)
y3 = self.avg_pool4(x).view(b, 16 * c)
y = torch.cat((y1, y2, y3), 1)
y = self.fc(y)
b, out_channel = y.size()
y = y.view(b, out_channel, 1, 1)
return y
ECA-Net[15]
《ECANet:Efficient Channel Attention for Deep Convolutional Neural Networks》发表于CVPR 2020,是对SE-Net中特征变换部分进行了改进。SE-Net的通道信息交互方式是通过全连接实现的,在降维和升维的过程中会损害一部分的特征表达。ECA-Net则进一步地利用一维卷积来实现通道间的信息交互,相对于全连接实现的全局通道信息交互所带来的计算开销,ECA-Net提出了一种基于自适应选择卷积核大小的方法,以实现局部交互,从而显著地降低模型复杂度且保持性能。
class ECALayer(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, channel, k_size=3):
super(ECALayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# feature descriptor on the global spatial information
y = self.avg_pool(x)
# Two different branches of ECA module
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# Multi-scale information fusion
y = self.sigmoid(y)
return x * y.expand_as(x)
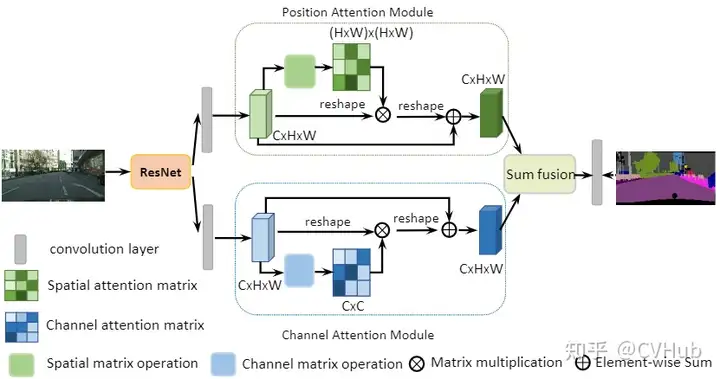
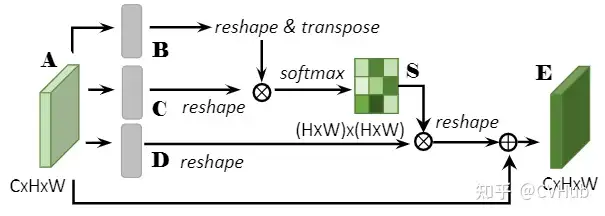
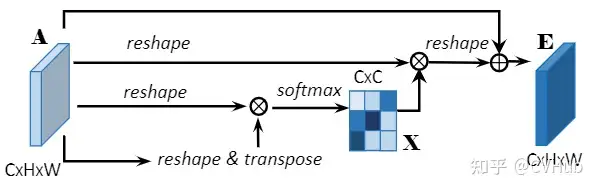
《DA-Net:Dual Attention Network for Scene Segmentation》发表于CVPR 2019,该论文将Non-local的思想同时引入到了通道域和空间域,分别将空间像素点以及通道特征作为查询语句进行上下文建模,自适应地整合局部特征和全局依赖。【代码链接可访问github[23]】
Position Attention Module
PAM将更广泛的上下文信息编码为局部特征,从而提高了它们的代表性。
Channel Attention Module
CAM通过挖掘通道图之间的相互依赖关系,可以强调相互依赖的特征图,改进特定语义的特征表示。
ANLNet[24]
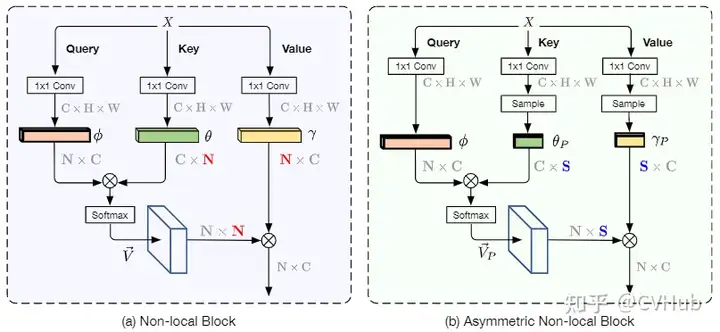
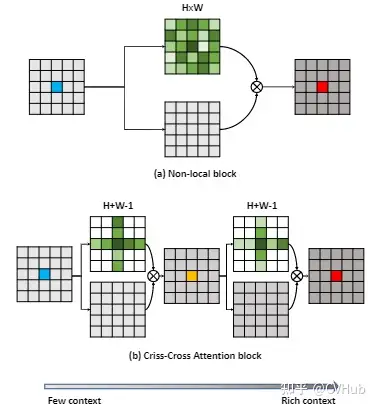
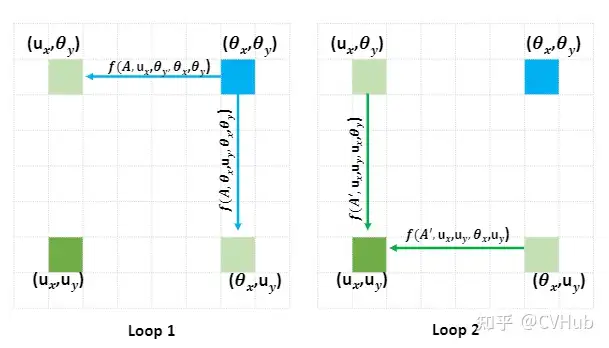
《ANLNet:Asymmetric Non-local Neural Networks for Semantic Segmentation》发表于ICCV 2019,是基于Non-Local的思路往轻量化方向做改进。Non-Local模块是一种效果显著的技术,但同时也受限于过大计算量而难以很好地嵌入网络中应用。为了解决以上问题,ANLNet基于Non-Local结构并融入了金字塔采样模块,在充分考虑了长距离依赖的前提下,融入了不同层次的特征,从而在保持性能的同时极大地减少计算量。【代码链接可访问github[25]】
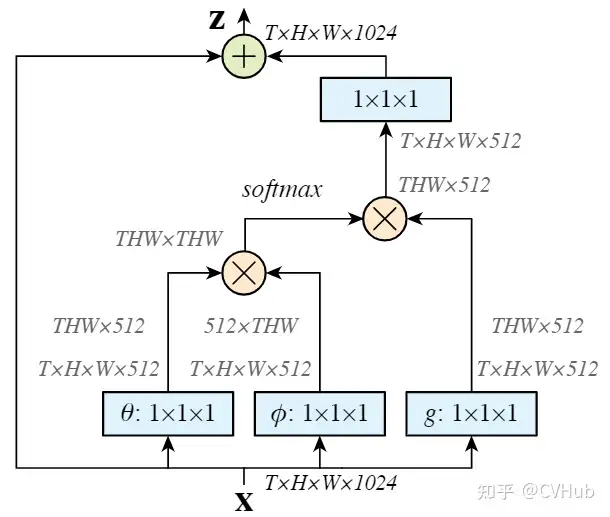
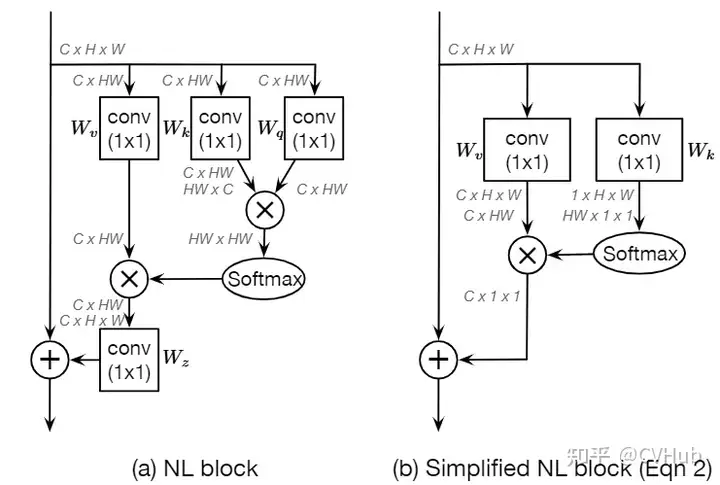
《GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond》发表于ICCV 2019,受SE-Net和Non-local思想的启发提出了一种更简化的空间自注意力模块。Non-local采用Self-attention机制来建模全局的像素对关系,建模长距离依赖,但这种基于全局像素点(pixel-to-pixel) 对的建模方式其计算量无疑是巨大的。SE-Net则利用GAP和MLP完成通道之间的特征重标定,虽然轻量,但未能充分利用到全局上下文信息。因此,作者提出了GC-Net可以高效的建模全局的上下文信息。【代码链接可访问github[29]】
类别注意力
OCR-Net[30]
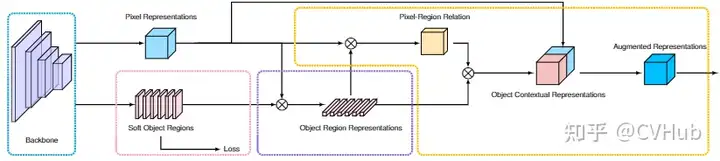
《Object-Contextual Representations for SemanticSegmentation》发表于ECCV 2020,是一种基于自注意力对类别信息进行建模的方法。与先前的自注意力对全局上下文建模的角度(通道和空间)不同,OCR-Net是从类别的角度进行建模,其利用粗分割的结果作为建模的对象,最后加权到每一个查询点,这是一种轻量并有效的方法。【代码链接可访问github[31]】
Soft Object Regions 对Backbone倒数第二层所输出的粗分割结果进行监督;
Object Region Representations 融合粗分割和Backbone网络最后一层所输出的高级语义特征图生成对象区域语义,每一条向量代表不同的类别信息;
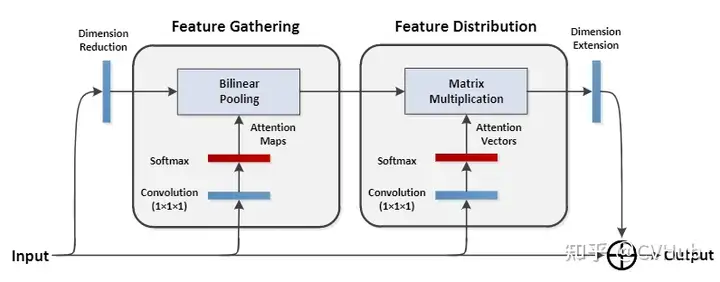
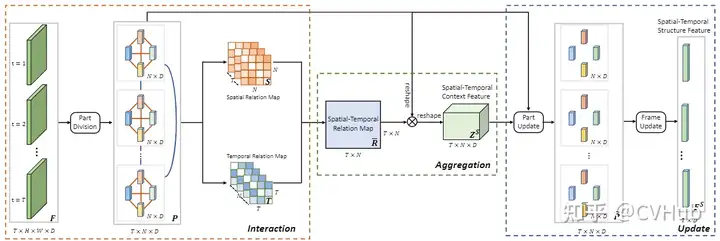
《IAUnet: Global Context-Aware Feature Learning for Person Re-Identification》发表于 IEEE Trans. on Neural Networks and Learning Systems,将自注意力机制的方法扩展到时间维度并应用于行人充识别任务,有效的解决了大多数基于卷积神经网络的方法无法充分对空间-时间上下文进行建模的弊端。【代码链接可访问github[33]】