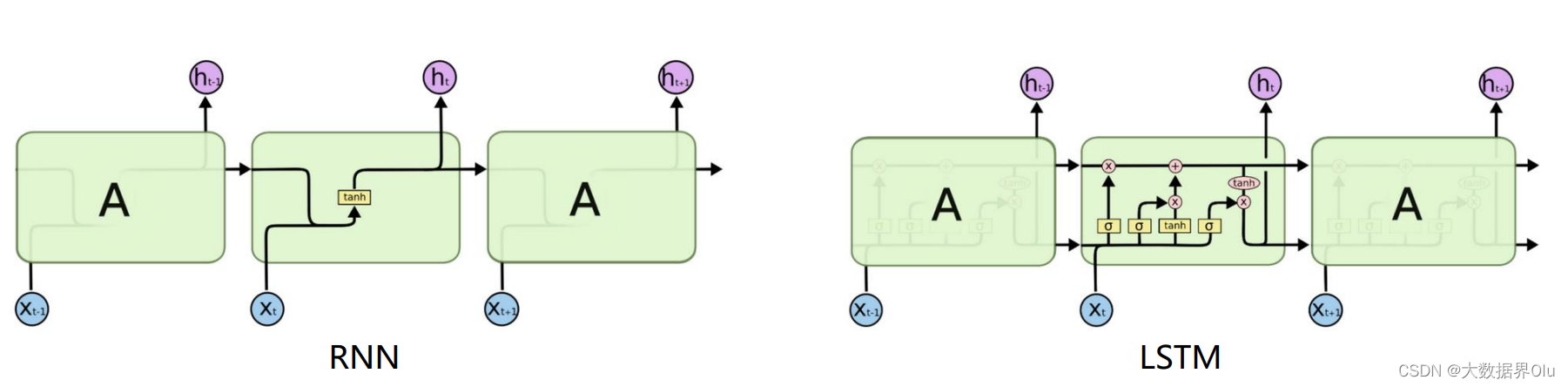
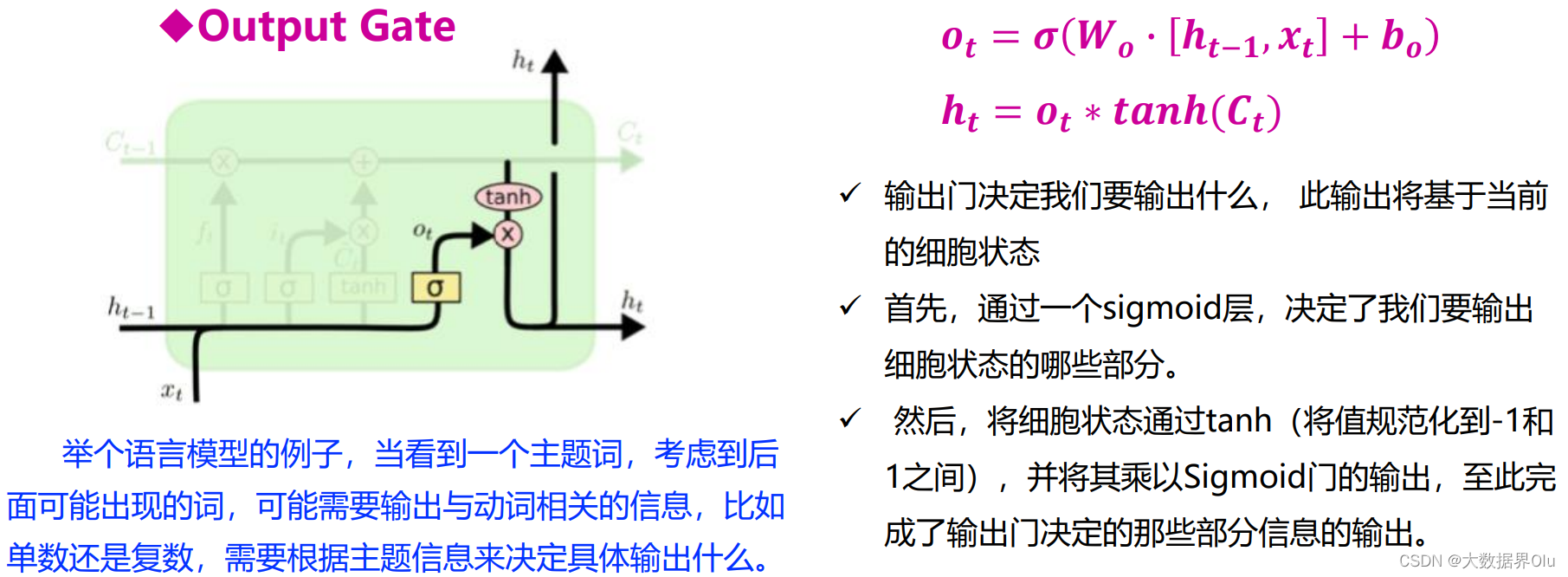
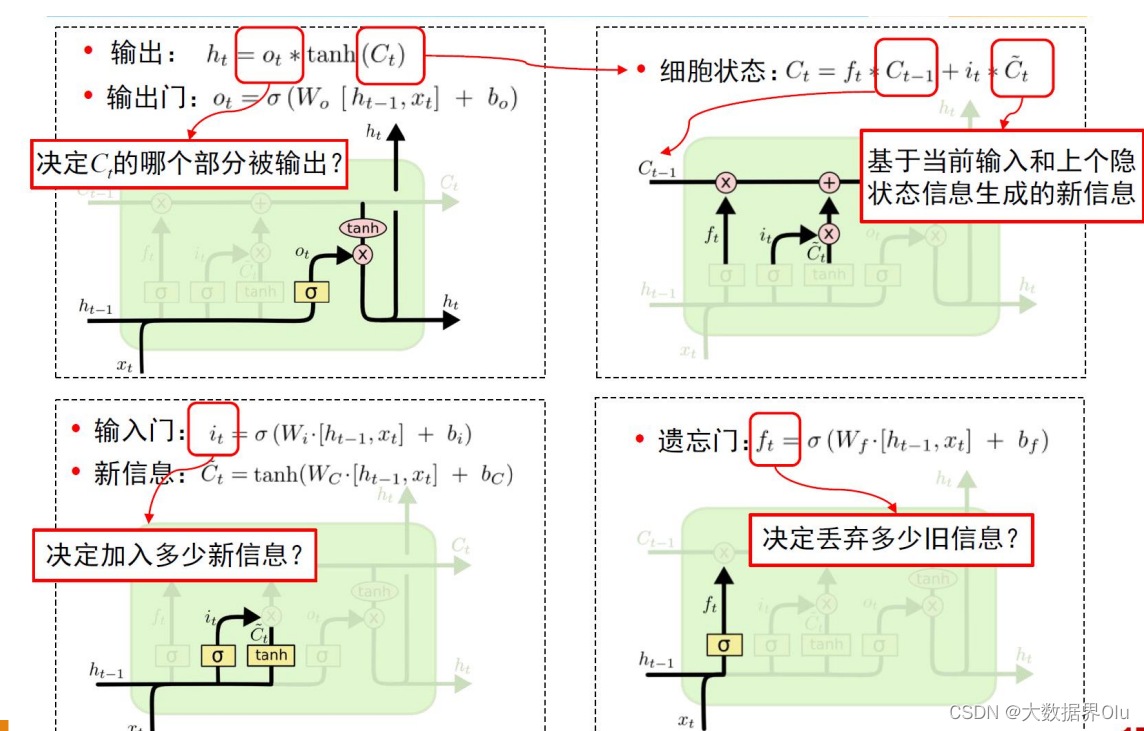
长短时记忆神经网络
RNN问题:长期依赖问题/梯度消失问题
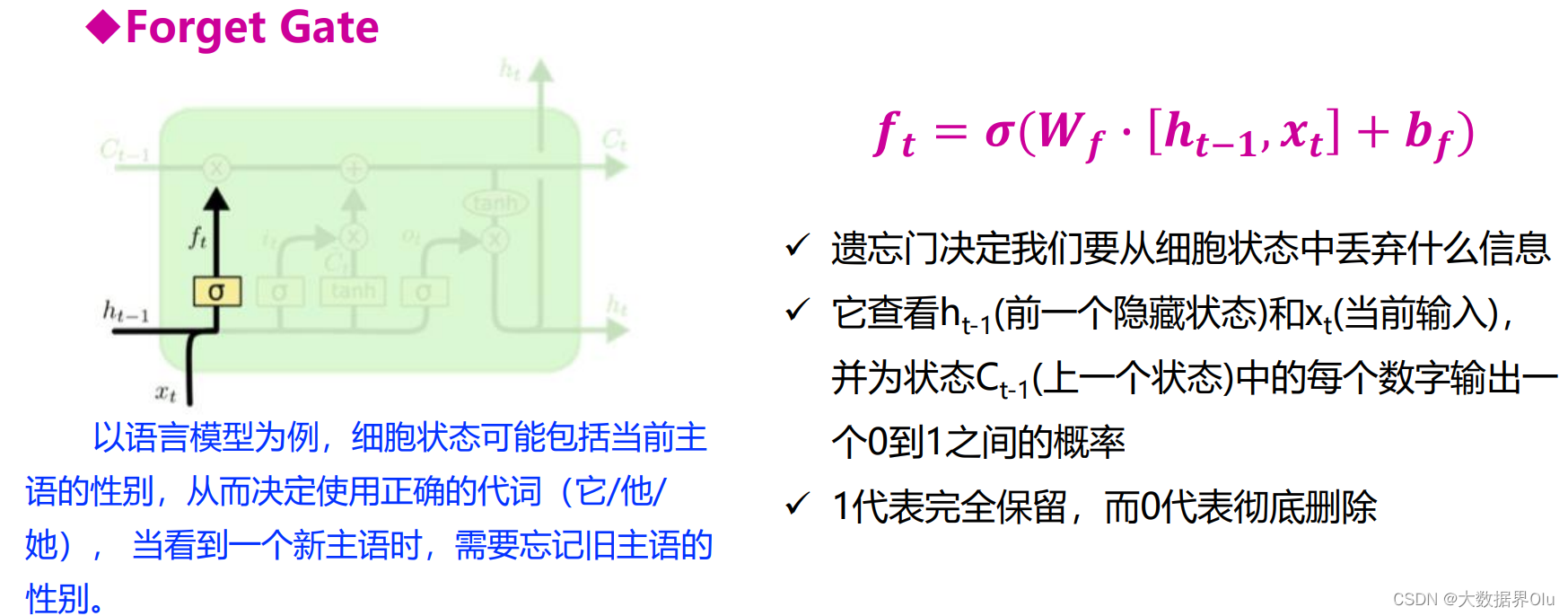
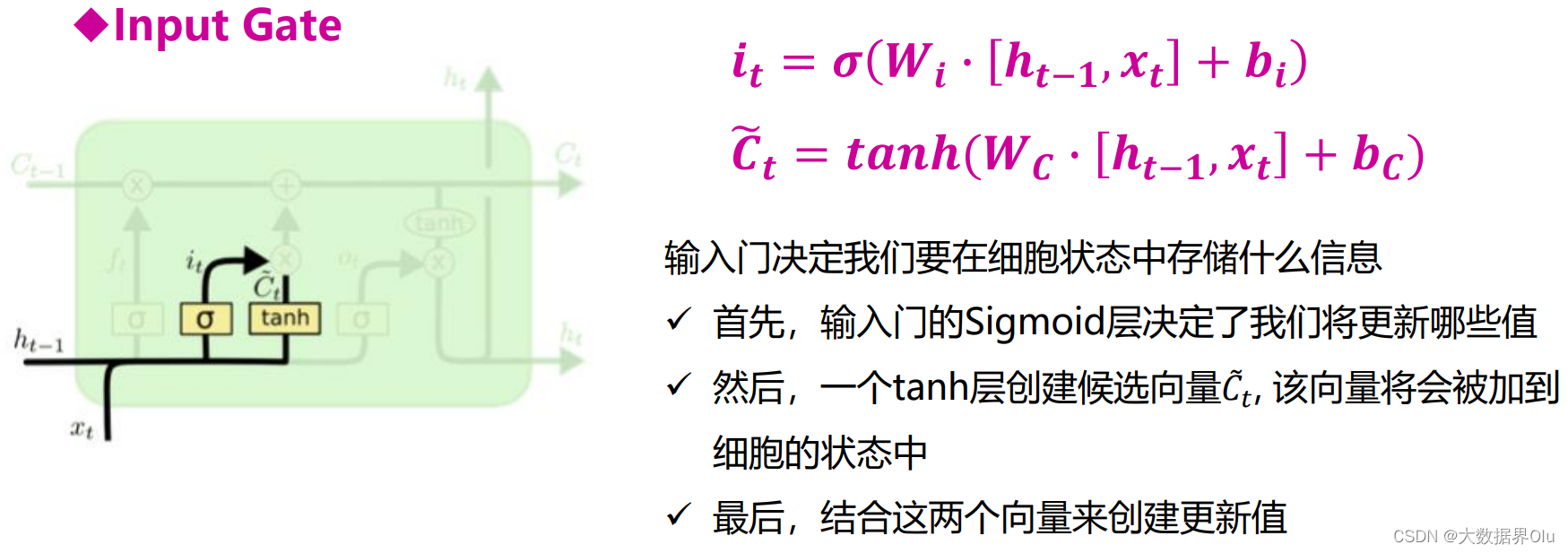
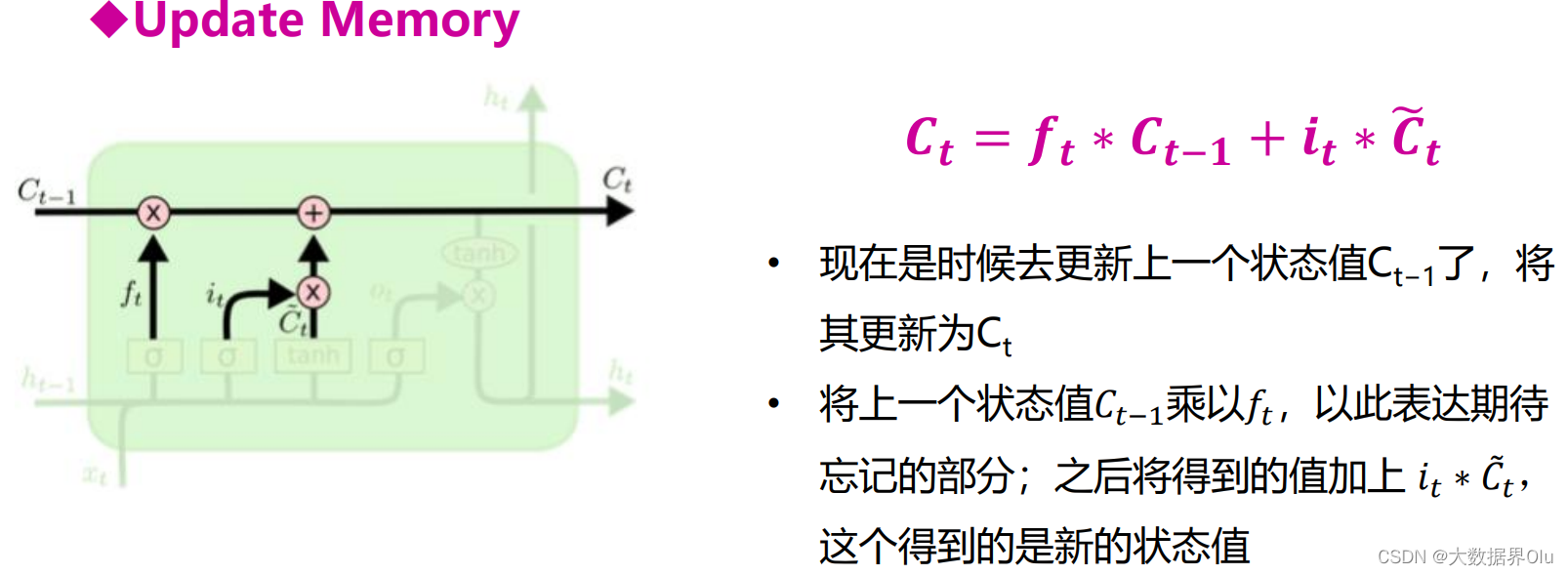
四种门
本次实践使用基于循环神经网络(RNN)的谣言检测模型,将文本中的谣言事件向量化,通过循环神经网络的学习训练来挖掘表示文本深层的特征,避免了特征构建的问题,并能发现那些不容易被人发现的特征,从而产生更好的效果。
数据集介绍:
本次实践所使用的数据是从新浪微博不实信息举报平台抓取的中文谣言数据,数据集中共包含1538条谣言和1849条非谣言。每条数据均为json格式,其中text字段代表微博原文的文字内容。
数据集介绍参考https://github.com/thunlp/Chinese_Rumor_Dataset
import paddle
import numpy as np
import matplotlib. pyplot as plt
print ( paddle. __version__)
(1)解压数据,读取并解析数据,生成all_data.txt
(2)生成数据字典,即dict.txt
(3)生成数据列表,并进行训练集与验证集的划分,train_list.txt 、eval_list.txt
(4)定义训练数据集提供器
import os, zipfile
src_path= "data/data20519/Rumor_Dataset.zip"
target_path= "/home/aistudio/data/Chinese_Rumor_Dataset-master"
if ( not os. path. isdir( target_path) ) :
z = zipfile. ZipFile( src_path, 'r' )
z. extractall( path= target_path)
z. close( )
import io
import random
import json
rumor_class_dirs = os. listdir( target_path+ "/Chinese_Rumor_Dataset-master/CED_Dataset/rumor-repost/" )
non_rumor_class_dirs = os. listdir( target_path+ "/Chinese_Rumor_Dataset-master/CED_Dataset/non-rumor-repost/" )
original_microblog = target_path+ "/Chinese_Rumor_Dataset-master/CED_Dataset/original-microblog/"
rumor_label= "0"
non_rumor_label= "1"
rumor_num = 0
non_rumor_num = 0
all_rumor_list = [ ]
all_non_rumor_list = [ ]
for rumor_class_dir in rumor_class_dirs:
if ( rumor_class_dir != '.DS_Store' ) :
with open ( original_microblog + rumor_class_dir, 'r' ) as f:
rumor_content = f. read( )
rumor_dict = json. loads( rumor_content)
all_rumor_list. append( rumor_label+ "\t" + rumor_dict[ "text" ] + "\n" )
rumor_num += 1
for non_rumor_class_dir in non_rumor_class_dirs:
if ( non_rumor_class_dir != '.DS_Store' ) :
with open ( original_microblog + non_rumor_class_dir, 'r' ) as f2:
non_rumor_content = f2. read( )
non_rumor_dict = json. loads( non_rumor_content)
all_non_rumor_list. append( non_rumor_label+ "\t" + non_rumor_dict[ "text" ] + "\n" )
non_rumor_num += 1
print ( "谣言数据总量为:" + str ( rumor_num) )
print ( "非谣言数据总量为:" + str ( non_rumor_num) )
data_list_path= "/home/aistudio/data/"
all_data_path= data_list_path + "all_data.txt"
all_data_list = all_rumor_list + all_non_rumor_list
random. shuffle( all_data_list)
with open ( all_data_path, 'w' ) as f:
f. seek( 0 )
f. truncate( )
with open ( all_data_path, 'a' ) as f:
for data in all_data_list:
f. write( data)
def create_dict ( data_path, dict_path) :
with open ( dict_path, 'w' ) as f:
f. seek( 0 )
f. truncate( )
dict_set = set ( )
with open ( data_path, 'r' , encoding= 'utf-8' ) as f:
lines = f. readlines( )
for line in lines:
content = line. split( '\t' ) [ - 1 ] . replace( '\n' , '' )
for s in content:
dict_set. add( s)
dict_list = [ ]
i = 0
for s in dict_set:
dict_list. append( [ s, i] )
i += 1
dict_txt = dict ( dict_list)
end_dict = { "<unk>" : i}
dict_txt. update( end_dict)
end_dict = { "<pad>" : i+ 1 }
dict_txt. update( end_dict)
with open ( dict_path, 'w' , encoding= 'utf-8' ) as f:
f. write( str ( dict_txt) )
print ( "数据字典生成完成!" )
def create_data_list ( data_list_path) :
with open ( os. path. join( data_list_path, 'eval_list.txt' ) , 'w' , encoding= 'utf-8' ) as f_eval:
f_eval. seek( 0 )
f_eval. truncate( )
with open ( os. path. join( data_list_path, 'train_list.txt' ) , 'w' , encoding= 'utf-8' ) as f_train:
f_train. seek( 0 )
f_train. truncate( )
with open ( os. path. join( data_list_path, 'dict.txt' ) , 'r' , encoding= 'utf-8' ) as f_data:
dict_txt = eval ( f_data. readlines( ) [ 0 ] )
with open ( os. path. join( data_list_path, 'all_data.txt' ) , 'r' , encoding= 'utf-8' ) as f_data:
lines = f_data. readlines( )
i = 0
maxlen = 0
with open ( os. path. join( data_list_path, 'eval_list.txt' ) , 'a' , encoding= 'utf-8' ) as f_eval, open ( os. path. join( data_list_path, 'train_list.txt' ) , 'a' , encoding= 'utf-8' ) as f_train:
for line in lines:
words = line. split( '\t' ) [ - 1 ] . replace( '\n' , '' )
maxlen = max ( maxlen, len ( words) )
label = line. split( '\t' ) [ 0 ]
labs = ""
if i % 8 == 0 :
for s in words:
lab = str ( dict_txt[ s] )
labs = labs + lab + ','
labs = labs[ : - 1 ]
labs = labs + '\t' + label + '\n'
f_eval. write( labs)
else :
for s in words:
lab = str ( dict_txt[ s] )
labs = labs + lab + ','
labs = labs[ : - 1 ]
labs = labs + '\t' + label + '\n'
f_train. write( labs)
i += 1
print ( "数据列表生成完成!" )
print ( "样本最长长度:" + str ( maxlen) )
谣言数据总量为:1538
data_root_path = "/home/aistudio/data/"
data_path = os. path. join( data_root_path, 'all_data.txt' )
dict_path = os. path. join( data_root_path, "dict.txt" )
create_dict( data_path, dict_path)
create_data_list( data_root_path)
def load_vocab ( file_path) :
fr = open ( file_path, 'r' , encoding= 'utf8' )
vocab = eval ( fr. read( ) )
fr. close( )
return vocab
vocab = load_vocab( os. path. join( data_root_path, 'dict.txt' ) )
def ids_to_str ( ids) :
words = [ ]
for k in ids:
w = list ( vocab. keys( ) ) [ list ( vocab. values( ) ) . index( int ( k) ) ]
words. append( w if isinstance ( w, str ) else w. decode( 'ASCII' ) )
return " " . join( words)
file_path = os. path. join( data_root_path, 'train_list.txt' )
with io. open ( file_path, "r" , encoding= 'utf8' ) as fin:
i = 0
for line in fin:
i += 1
cols = line. strip( ) . split( "\t" )
if len ( cols) != 2 :
sys. stderr. write( "[NOTICE] Error Format Line!" )
continue
label = int ( cols[ 1 ] )
wids = cols[ 0 ] . split( "," )
print ( str ( i) + ":" )
print ( 'sentence list id is:' , wids)
print ( 'sentence list is: ' , ids_to_str( wids) )
print ( 'sentence label id is:' , label)
print ( '---------------------------------' )
if i == 2 : break
vocab = load_vocab( os. path. join( data_root_path, 'dict.txt' ) )
class RumorDataset ( paddle. io. Dataset) :
def __init__ ( self, data_dir) :
self. data_dir = data_dir
self. all_data = [ ]
with io. open ( self. data_dir, "r" , encoding= 'utf8' ) as fin:
for line in fin:
cols = line. strip( ) . split( "\t" )
if len ( cols) != 2 :
sys. stderr. write( "[NOTICE] Error Format Line!" )
continue
label = [ ]
label. append( int ( cols[ 1 ] ) )
wids = cols[ 0 ] . split( "," )
if len ( wids) >= 150 :
wids = np. array( wids[ : 150 ] ) . astype( 'int64' )
else :
wids = np. concatenate( [ wids, [ vocab[ "<pad>" ] ] * ( 150 - len ( wids) ) ] ) . astype( 'int64' )
label = np. array( label) . astype( 'int64' )
self. all_data. append( ( wids, label) )
def __getitem__ ( self, index) :
data, label = self. all_data[ index]
return data, label
def __len__ ( self) :
return len ( self. all_data)
batch_size = 32
train_dataset = RumorDataset( os. path. join( data_root_path, 'train_list.txt' ) )
test_dataset = RumorDataset( os. path. join( data_root_path, 'eval_list.txt' ) )
train_loader = paddle. io. DataLoader( train_dataset, places= paddle. CPUPlace( ) , return_list= True ,
shuffle= True , batch_size= batch_size, drop_last= True )
test_loader = paddle. io. DataLoader( test_dataset, places= paddle. CPUPlace( ) , return_list= True ,
shuffle= True , batch_size= batch_size, drop_last= True )
print ( '=============train_dataset =============' )
for data, label in train_dataset:
print ( data)
print ( np. array( data) . shape)
print ( label)
break
print ( '=============test_dataset =============' )
for data, label in test_dataset:
print ( data)
print ( np. array( data) . shape)
print ( label)
break
import paddle
from paddle. nn import Conv2D, Linear, Embedding
from paddle import to_tensor
import paddle. nn. functional as F
class RNN ( paddle. nn. Layer) :
def __init__ ( self) :
super ( RNN, self) . __init__( )
self. dict_dim = vocab[ "<pad>" ]
self. emb_dim = 128
self. hid_dim = 128
self. class_dim = 2
self. embedding = Embedding(
self. dict_dim + 1 , self. emb_dim,
sparse= False )
self. _fc1 = Linear( self. emb_dim, self. hid_dim)
self. lstm = paddle. nn. LSTM( self. hid_dim, self. hid_dim)
self. fc2 = Linear( 19200 , self. class_dim)
def forward ( self, inputs) :
emb = self. embedding( inputs)
fc_1 = self. _fc1( emb)
x = self. lstm( fc_1)
x = paddle. reshape( x[ 0 ] , [ 0 , - 1 ] )
x = self. fc2( x)
x = paddle. nn. functional. softmax( x)
return x
rnn = RNN( )
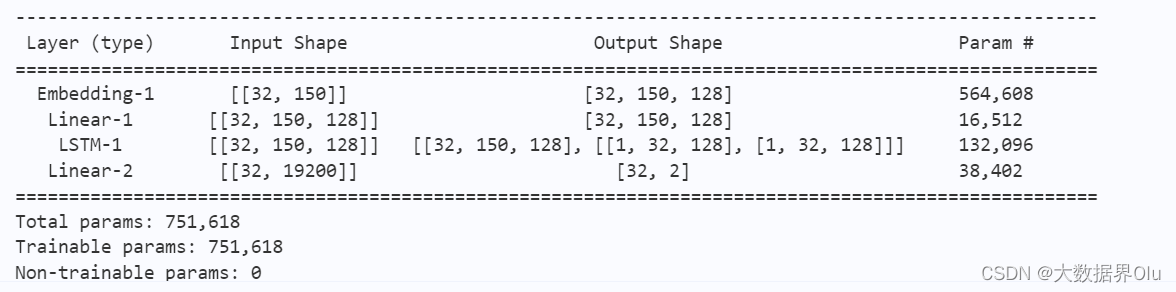
paddle. summary( rnn, ( 32 , 150 ) , "int64" )
def draw_process ( title, color, iters, data, label) :
plt. title( title, fontsize= 24 )
plt. xlabel( "iter" , fontsize= 20 )
plt. ylabel( label, fontsize= 20 )
plt. plot( iters, data, color= color, label= label)
plt. legend( )
plt. grid( )
plt. show( )
def train ( model) :
model. train( )
opt = paddle. optimizer. Adam( learning_rate= 0.002 , parameters= model. parameters( ) )
steps = 0
Iters, total_loss, total_acc = [ ] , [ ] , [ ]
for epoch in range ( 3 ) :
for batch_id, data in enumerate ( train_loader) :
steps += 1
sent = data[ 0 ]
label = data[ 1 ]
logits = model( sent)
loss = paddle. nn. functional. cross_entropy( logits, label)
acc = paddle. metric. accuracy( logits, label)
if batch_id % 50 == 0 :
Iters. append( steps)
total_loss. append( loss. numpy( ) [ 0 ] )
total_acc. append( acc. numpy( ) [ 0 ] )
print ( "epoch: {}, batch_id: {}, loss is: {}" . format ( epoch, batch_id, loss. numpy( ) ) )
loss. backward( )
opt. step( )
opt. clear_grad( )
model. eval ( )
accuracies = [ ]
losses = [ ]
for batch_id, data in enumerate ( test_loader) :
sent = data[ 0 ]
label = data[ 1 ]
logits = model( sent)
loss = paddle. nn. functional. cross_entropy( logits, label)
acc = paddle. metric. accuracy( logits, label)
accuracies. append( acc. numpy( ) )
losses. append( loss. numpy( ) )
avg_acc, avg_loss = np. mean( accuracies) , np. mean( losses)
print ( "[validation] accuracy: {}, loss: {}" . format ( avg_acc, avg_loss) )
model. train( )
paddle. save( model. state_dict( ) , "model_final.pdparams" )
draw_process( "trainning loss" , "red" , Iters, total_loss, "trainning loss" )
draw_process( "trainning acc" , "green" , Iters, total_acc, "trainning acc" )
model = RNN( )
train( model)
'''
模型评估
'''
model_state_dict = paddle. load( 'model_final.pdparams' )
model = RNN( )
model. set_state_dict( model_state_dict)
model. eval ( )
label_map = { 0 : "是" , 1 : "否" }
samples = [ ]
predictions = [ ]
accuracies = [ ]
losses = [ ]
for batch_id, data in enumerate ( test_loader) :
sent = data[ 0 ]
label = data[ 1 ]
logits = model( sent)
for idx, probs in enumerate ( logits) :
label_idx = np. argmax( probs)
labels = label_map[ label_idx]
predictions. append( labels)
samples. append( sent[ idx] . numpy( ) )
loss = paddle. nn. functional. cross_entropy( logits, label)
acc = paddle. metric. accuracy( logits, label)
accuracies. append( acc. numpy( ) )
losses. append( loss. numpy( ) )
avg_acc, avg_loss = np. mean( accuracies) , np. mean( losses)
print ( "[validation] accuracy: {}, loss: {}" . format ( avg_acc, avg_loss) )
print ( '数据: {} \n\n是否谣言: {}' . format ( ids_to_str( samples[ 0 ] ) , predictions[ 0 ] ) )