这篇教程csv逗号分隔符转换 python导入xlsx转为csv python提出csv中数据 如何将csv文件处理成rdf文件写得很实用,希望能帮到您。
概述
通过pandas处理数据时,数据从何而来呢?基本都是从外部获取的,如纯文本文件、excel、数据库、网页等,所以从外部导入数据的重要性不言而喻。
这篇文章将介绍导入csv和excel文件为Pandas的DataFrame对象。
导入CSV文件
csv文件类型实际是文本文件,由于文本文件没有固定的格式或数据类型等,所以csv文件形式可以是千变万化,下面将介绍如何来导入杂乱无章的csv文件。
主要函数:
read_csv()
由于csv文件中数据、格式等导致杂乱无章,所以read_csv()函数的参数达50多个。
第一个参数filepath_or_buffer为文件名
第二个参数为sep为分隔符,有逗号(',')、制表符('t')等分隔符
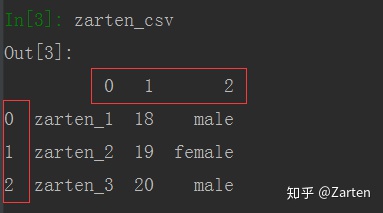
最简单的形式
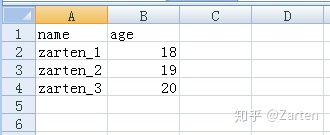
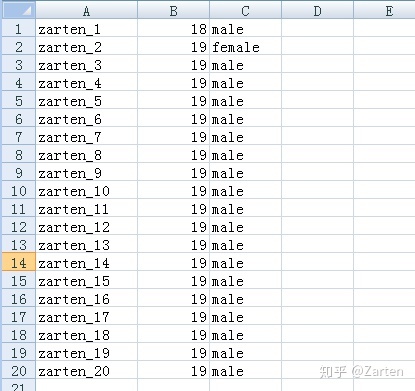
文件如下:
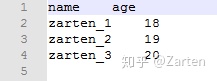
文本编辑器打开如下:
由上图看到,以制表符't'分隔,函数参数使用sep= 't'
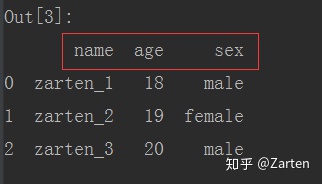
设置列名
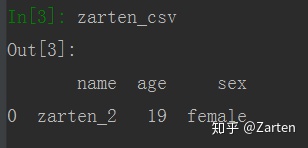
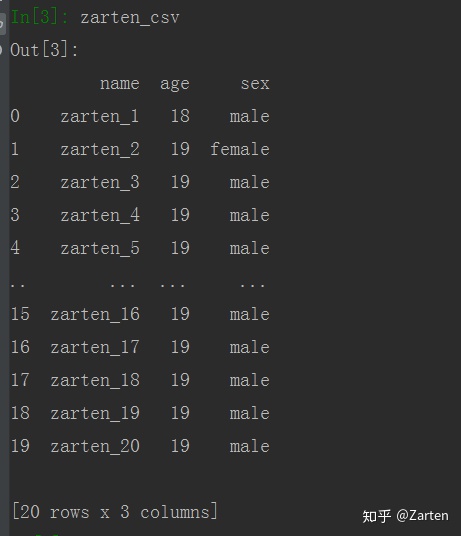
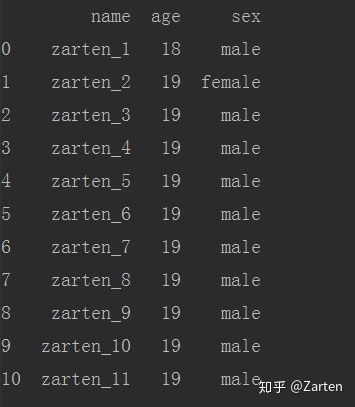
有时csv文件中没有列名,这时若直接读取会自动将第一行数据当做列名,如下所示:
若csv文件中没有列名,可以通过参数自行设置:
names设置列名
header=None 设置默认的列名
默认列名(header=None)
自定义列名(names)
传入一个列表
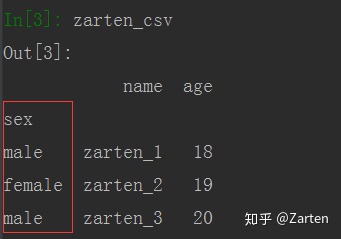
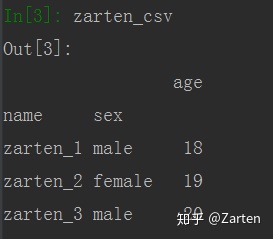
设置行索引
可以将某列的值作为行索引,指定参数index_col即可
若需要将多个列做成一个层次化行索引,传入参数index_col一个列表即可
导入时跳过某行或多行
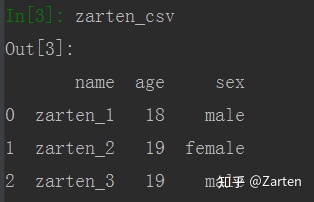
有时某行或多行的数据不是我们想要的,可以设置参数skiprows跳过
下面例子跳过第一行和第三行
csv文件中缺失值及无效值处理
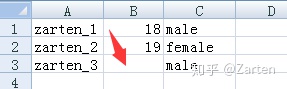
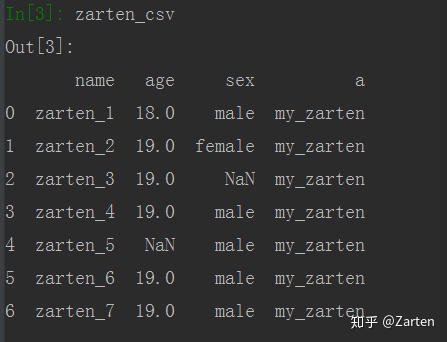
有时文件中难免会有各种情况,如空值等
下图中箭头处是空值
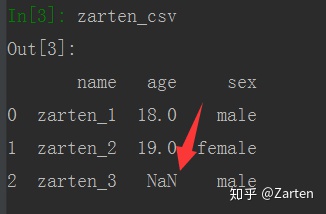
缺失值时,读取后默认为NaN。
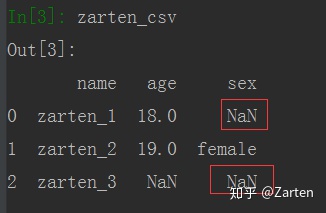
当然有些值是无效值,也可以通过参数na_values来将这个无效值处理成NaN
分块读取csv文件
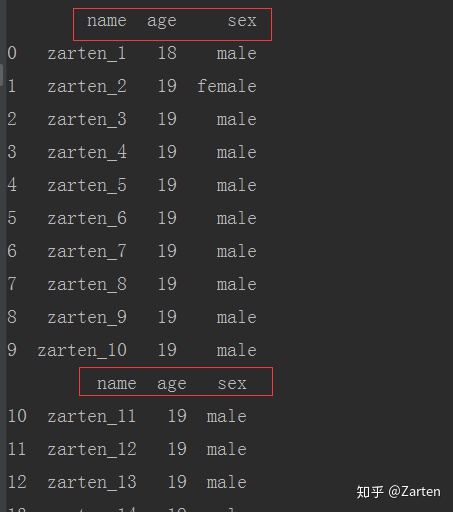
对于大文件而言,有时候一次性导入要花费大量时间,也可能是我们只需要前面多少行的数据,同时显示的时候可能只需要显示多少行等,这时就需要分块的操作。
文件如下:
通过设置 :pd.options.display.max_rows = 10
从上面结果看到,确实是只显示了10行数据,便于查看。
通过设置参数 nrows即可
对于一个大文件可以分块读取,设置参数chunksize即可,若设置这个参数后将返回一个TextFileReader 对象迭代器,可以用这个对象逐块迭代
从上图看到10条为一块,由于太长了就没有全部截图。
同时TextFileReader 对象有个get_chunk()方法可以读取任意大小的块。
read_csv()其他常用参数就不一一阐述,具体可查看下图
数据写入CSV文件
写入与读取是逆过程,主要使用csv文件对象的函数to_csv()
参数
sep:设置分隔符
na_rep:设置缺失值在csv文件中的显示
columns:指定顺序排列
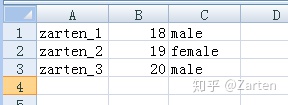
需要写入csv文件的数据如下所示:
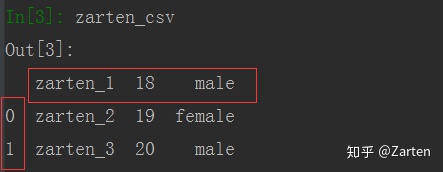
写入数据到csv:
Pandas操作Excel文件
excel也是比较常见的数据文件格式。
使用函数 read_excel()
跟read_csv()类似,若excel中没有列,会将第一行默认作为列,同样用参数names设置
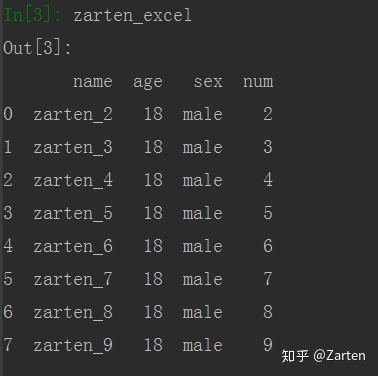
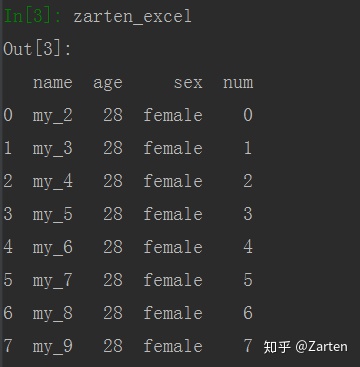
我们知道,excel中有多个表单,通过sheet_name参数来设置表单名,若不知道默认为第一个表单。
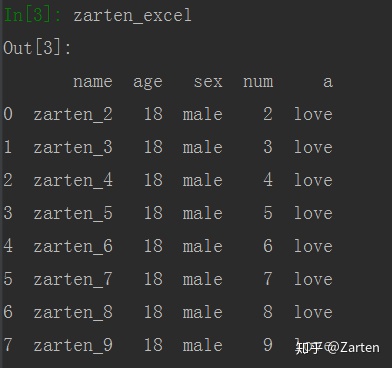
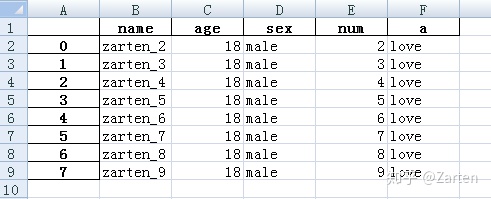
数据写入excel文件
使用函数to_excel()
要写的数据如下:
其他用法跟csv用法类似,可参考前面所讲的。
python 对Excel 文档的基本操作
python代码实现pandas读取Excel数据转换numpy格式数据 |