这篇教程【深度学习】知识图谱――K-BERT详解写得很实用,希望能帮到您。
【深度学习】知识图谱——K-BERT详解
阿里巴巴 算法工程师
论文地址:https://arxiv.org/abs/1909.07606v1
项目地址:https://github.com/autoliuweijie/K-BERT
一、背景介绍:
参考:PaperWeekly:BERT+知识图谱:北大-腾讯联合推出知识赋能的K-BERT模型
BERT它是一种从大规模语料库中学得语言表征的模型,但是,在专业领域表现不佳。
为了解决该问题,作者提出了一个基于知识图谱的语言表示模型K-BERT。
然而过多的考虑领域知识可能导致语句语义出现错误,这个问题被称为知识噪声(Knowledge noies, KN)。为了解决KN问题,K-BERT引入了soft-position和可视化矩阵(visible matrix)来限制来现在领域知识的影响。
BERT是基于大规模开放预料的预训练模型,对于下游任务,只需微调就可吸收专业领域知识。但是由于预训练和微调之间存在领域知识差异,因而在领域知识驱动型任务上,BERT无法取得满意的表现。
一种解决办法就是基于领域知识的语料库进行预训练,但是这样做耗时耗力,对大多数用户是不能承受的。因此作者认为引入知识图谱来使得模型成为领域专家是一个很好的解决方案,因为:
- 很多领域的知识图谱都是结构化数据;
- 在减小预训练成本的同时还能将领域知识植入模型;
- 模型有更好的可解释性,因为植入的知识是可手工编辑的。
但是,这种方法面临2个挑战:
- Heterogeneous Embedding Space (HES)
即文本中的词嵌入向量和从知识图谱中实体的词嵌入向量,它们的向量空间不一致。
- Knowledge Noise (KN)
过多的考虑领域知识可能导致句子的语义出现错误。
于是作者提出了K-BERT模型,K-BERT可以加载任意BERT模型,然后很容易植入领域知识,而不需要在进行预训练。
随着2018年Google推出BERT模型,很多人从预训练过程和编码器两方面进行了优化,具体列举如下:
- 对预训练过程的优化
- Baidu-ERNIE和BERT-WWM:在中文语料库上对全词掩码,而不是对单个字进行掩码训练了BERT.
- SpanBERT:通过对连续的随机跨度的词进行掩码,并提出了跨度边界目标
- RoBERTa:主要通过三个方面对BERT的预训练过程进行了优化,1)删除了预测下一句的训练目标;2)动态掩码策略;3)采用更长的语句作为训练样本
- 对编码器的优化
- XLNet:用Transformer-XL替代Transformer,改进对长句子的处理;
- THU-ERNIE:修改了BERT的编码器,实现单词和实体的相互集成。
另一方面,知识图谱与词向量结合的研究早在预训练LR(Language Representation)模型之前就有人在做了:
- Wang et al. (2014)基于word2vec(Mikolov et al. 2013) [1]的思想提出了一种将实体和单词联合嵌入同一连续向量空间的新方法;
- Toutanova et al. (2015)提出了一个模型[2],该模型捕获文本关系的组成结构,并以联合方式优化实体,知识库和文本关系表示;
- Han, Liu, and Sun (2016) 用CNN和KG学习文本和知识的联合表示[3];
- Cao et al. (2018) 利用注意力远程监督方法学习词和实体的跨语言表示[4]。
上述方法的主要缺点是:
- 这些方法是基于"word2vec + transE"的思想,而不是预训练语言表示模型;
- 仍然存在HES(Heterogeneous Embedding Space)问题;
- 实体太多,超出了GPU的内存大小,无法计算
二、模型介绍:
2.1 模型结构
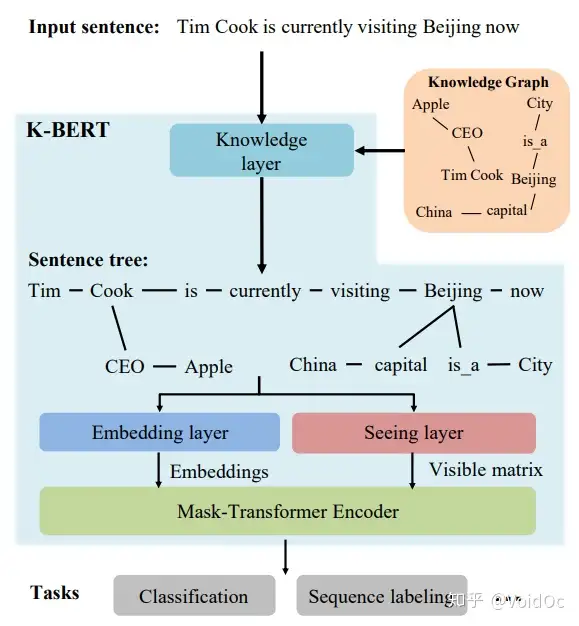 与其他RL模型相比,K-BERT具有可编辑的KG,可以适应其应用领域
与其他RL模型相比,K-BERT具有可编辑的KG,可以适应其应用领域
模型结构包含如下4层:
Knowledge layer
Embedding layer
Seeing layer
Mask-Transformer Encoder
Knowledge layer(KL)的作用是:
- 将知识图谱注入到句子中;
- 完成句子树的转换。
给定知识图谱K,输入一句话s={w0,w1,w2,...,wn},经KL层后输出句子树t={w0,w1,...,wi {(ri0, wi0),....(rik,wik)},...,wn}。公式化表达为:t = K_Inject(s, K_Query(s, K))
该过程分为两步:知识查询(K-Query)和知识注入(K-Inject)

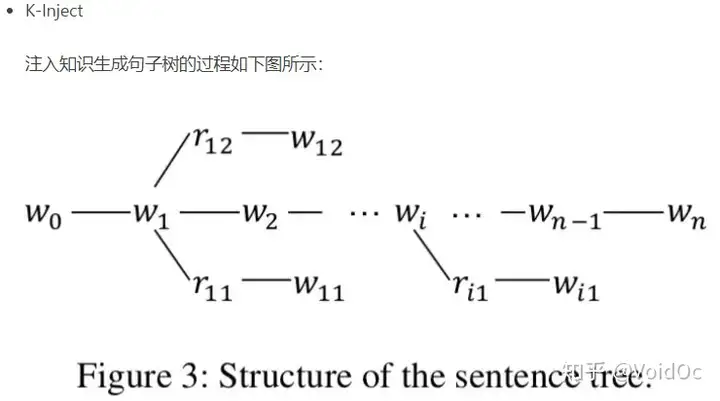 图3
图3
例如,当一个句子“Tim Cook is currently visiting Beijing now”输入时,首先会经过一个知识层(Knowledge Layer),知识层将知识图谱中关联到的三元组信息(Apple-CEO-Tim Cook、Beijing-capital-China 等)注入到句子中,形成一个富有背景知识的句树(Sentence tree)。
可以看出,通过知识层,一个句子序列被转换成了一个树结构或图结构,其中包含了句子中原本没有的背景知识,即我们知道“苹果的 CEO 现在在中国”。
得到了句子树以后,问题出现了。传统的 BERT 类模型,只能处理序列结构的句子输入,而图结构的句子树是无法直接输入到 BERT 模型中的。如果强行把句子树平铺成序列输入模型,必然造成结构信息的丢失。
Embedding layer(EL)的作用是将句子树转换成嵌入表达。和BERT一样,K-BERT的嵌入表示包括三部分:token embedding, position embedding 和 segment embedding。关键是如何将句子树转换成一个序列,同时保留它的结构信息。
- Token Embedding
在这里,K-BERT 中提出了一个很巧妙的解决办法,那就是软位置(Soft-position)和可见矩阵(Visible Matrix)。因为K-BERT的输入是句子树,所以需要对句子树转换成一个序列,作者的做法是:直接将句子树的分子插入到对应的节点
- Soft-position embedding
我们知道,BERT引入position embedding是为了建模句子的结构信息(比如词序的影响)。因此作者用所谓的soft-position embedding来解决句子树重排序后导致句子不通顺的问题。
Soft-position embedding的位置编码示例见图2.
从图2可以看到,存在位置不同编码相同的问题,作者的解决办法是所谓的Mask-Self-Attention,见后文。
- Segment embedding
与BERT一致,见图2.
 图2
图2
将句子树转换为嵌入表示和可见矩阵的过程。在句子树中,红色的数字是软位置索引,灰色的是硬位置索引。
(1)对于令牌嵌入,将句子树中的令牌按其硬位置索引平铺成令牌嵌入序列;
(2)软位置索引与令牌嵌入一起作为位置嵌入;
(3)在分段嵌入中,第一句中的所有标记都标记为“A”;
(4)在可见矩阵中,红色表示可见,白色表示不可见。例如,第4行第9列的单元格是白色的,表示“Apple(4)”看不到“China(9)”。
在 K-BERT 中,首先会将句子树平铺,例如图 2 中的句子树平铺以后是“[CLS] Tim Cook CEO Apple is currently visiting Beijing capital China is_a City now”。
显然,平铺以后的句子是杂乱不易读的,K-BERT 通过软位置编码恢复句子树的顺序信息,即“[CLS](0) Tim(1) Cook(2) CEO(3) Apple(4) is(3) visiting(4) Beijing(5) capital(6) China(7) is_a(6) City(7) now(6)”,可以看到“CEO(3)”和“is(3)”的位置编码都 3,因为它们都是跟在“Cook(2)”之后。但只用软位置还是不够的,因为会让模型误认为 Apple (4) 是跟在 is (3) 之后,这是错误的。
前文已经讲了引入KG可能造成KN问题,于是Seeing layer层的作用就是通过一个visible matrix(可见矩阵)来限制词与词之间的联系。

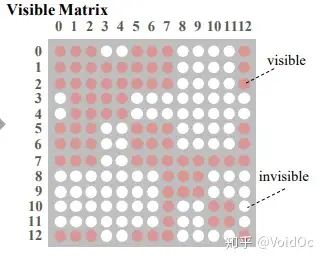 可见矩阵
可见矩阵
Mask-Transformer 核心思想就是让一个词的词嵌入只来源于其同一个枝干的上下文,而不同枝干的词之间相互不影响。这就是通过可见矩阵来实现的,图 2 中的句子树对应的可见矩阵如上图所示,其中一共有 13 个 token,所以是一个 13*13 的矩阵,红色表示对应位置的两个 token 相互可见,白色表示相互不可见。对于一个可见矩阵 M,相互可见的红色点取值为 0,相互不可见的白色取值为负无穷。
有了可见矩阵以后,可见矩阵该如何使用呢?其实很简单,就是 Mask-Transformer。因为Transformer的编码器不能接收visible matrix作为输入,因此作者对其进行了改造,称为Mask-Transformer。所谓Mask-Transformer,其实就是mask-self-attention块的堆叠,从而将图或树结构中的结构信息引入到模型中。
上面说过,对于一个可见矩阵 M,相互可见的红色点取值为 0,相互不可见的白色取值为负无穷,然后我们把 M 加到计算 self-attention 的 softmax 函数里就好,即如下公式:

其中:
1. Wq,Wk,Wv是需要学习的模型参数
2. ℎ� 是隐状态的第i个mask-self-attention块
3. �� 是缩放因子
以上公式只是对 BERT 里的 self-attention 做简单的修改,多加了一个 M,其余并无差别。如果两个字之间相互不可见, ���=−∞ ,它们之间的影响系数 ��+1 就会是 0,也就使这两个词的隐藏状态 h 之间没有任何影响。这样,就把句子树中的结构信息输入给 BERT 了。
 Mask-Transformer:掩码转换器,它是多个掩码自我注意块的堆栈。 hi[Apple]对hi[CLS]是不可见的,只能通过hi[Cook]间接作用于hi[CLS],从而降低了知识噪声的影响。
Mask-Transformer:掩码转换器,它是多个掩码自我注意块的堆栈。 hi[Apple]对hi[CLS]是不可见的,只能通过hi[Cook]间接作用于hi[CLS],从而降低了知识噪声的影响。
除了软位置和可见矩阵,其余结构均与 Google BERT 保持一致,这就给 K-BERT 带来了一个很好的特性——兼容 BERT 类的模型参数。K-BERT 可以直接加载 Google BERT、Baidu ERNIE、Facebook RoBERTa 等市面上公开的已预训练好的 BERT 类模型,无需自行再次预训练,给使用者节约了很大一笔计算资源。
三、训练任务
论文代码github仓给出了文本分类(CLS)和实体识别(NER)两类训练任务的样例代码:
run_kbert_cls.py
run_kbert_ner.py
3.1 数据准备
torch>=1.0
argparse==1.1
WikiZh:
WebtextZh:一个高质量的、大规模的中文问答预料库
需要引入的知识图谱以.spo格式保存在/brain/kgs目录下,内容格式为:
(Subject-Predicate-Object),如下例

第1列是Subject,第2列是Predicate,第3列是Object。
CN-DBpedia:包含5168865条通用中文SPO的知识图谱;
HowNet:包含52576条通用中文SPO的知识图谱;
MedicalKG:包含13864条中文医疗领域专业SPO的知识图谱。
Google BERT:Google基于WikiZh预料库训练的BERT;
Our-BERT:作者用WikiZh和WebtextZh两个语料库训练的BERT
3.2 参数设置和训练细节
为了反应KG和RL(Representation Language)模型之间的角色关系,作者在训练K-BERT时保持与BERT的参数一致。
- (mask-)self-attention的层数L=12
- (mask-)self-attention的多头数A=12
- 隐层向量维度H=768
- 嵌入层维度E=768
- feed-forward/filter的size设置为4H,即H=768时为3072
3.3 训练
python -u run_kbert_cls.py \
--train_path ./datasets/book_review/train.tsv \
--dev_path ./datasets/book_review/dev.tsv \
--test_path ./datasets/book_review/test.tsv \
--kg_name ./brain/kgs/CnDbPedia.spo \
--output_model_path ./outputs/kbert_bookreview_CnDbpedia.bin
四、代码详解
五、自适应
- 替换自己任务领域适用的知识图谱:./brain/kgs 下面的的spo知识图谱自己重新定义,注意遵守格式(Subject-Predicate-Object)
- 替换自己的数据集:./brain/datasets下面加入自己的train.tsv、test.tsv和dev.tsv
标注数据的格式要符合BIO标注格式:即将每个元素标注为“B-X”、“I-X”或者“O”。其中,“B-X”表示此元素所在的片段属于X类型并且此元素在此片段的开头,“I-X”表示此元素所在的片段属于X类型并且此元素在此片段的中间位置,“O”表示不属于任何类型。
- B-X:名词短语的开头
- I-X:名词短语的中间
- O:不是名词短语
例如:
疼 痛 不 适 3 个 月 加 重 2 0 天 收 入 院 。 B-Symptom I-Symptom O O O O O O O O O O O O O O
ps:一些中、英文标注工具连接:
PaperWeekly:构想:中文文本标注工具(内附多个开源文本标注工具)
自然语言处理标记工具汇总_wangyizhen的博客-CSDN博客
我用2019年MIT出的doccano,教程参考:
LINUX:文本数据标注工具Doccano_Steven灬的博客-CSDN博客_doccano
Windows:doccano--NLP标注工具新秀_NLP翟-CSDN博客
六、总结
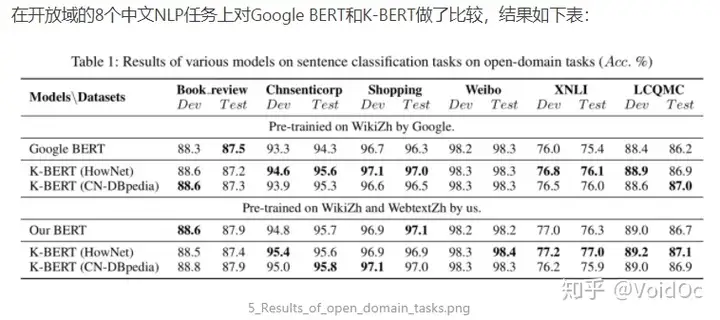
- 对于情感分析任务,KG的帮助不大。因为根据语句中的情感词本身就能做出情感判断;
- 对于语义相似任务(XNLI,LCQMC),语义知识图谱(HowNet)的帮助更大;
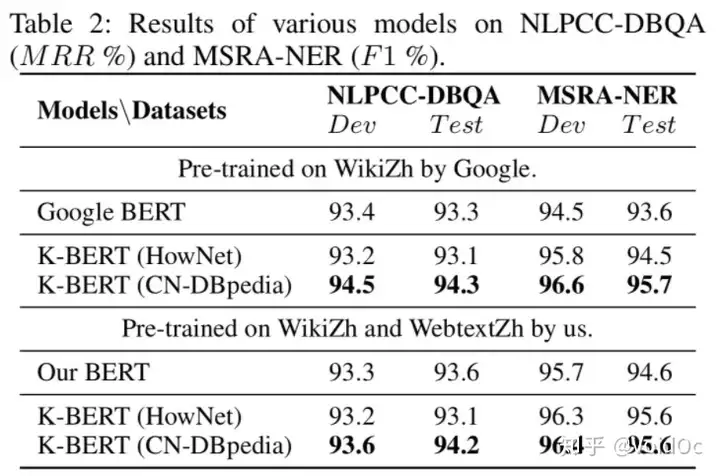
- 对于Q&A和NER任务(NLPCC-DBQA and MSRA-NER),有更多知识的KG比语言知识图谱更有帮助,见下表
引用
- K-BERT理解
作者:qzlydao
链接:https://www.jianshu.com/p/8ea58fc24301
来源:简书
2. K-BERT详解_小岁月太着急-CSDN博客
3. 自然语言处理标记工具汇总_wangyizhen的博客-CSDN博客
4.文本数据标注工具Doccano_Steven灬的博客-CSDN博客_doccano
声明
所有文章都为本人的学习笔记,非商用,
目的只求在工作学习过程中通过记录,梳理清楚自己的知识体系。
文章或涉及多方引用,如有纰漏忘记列举,请多指正与包涵
参考
- ^https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.671.1250&rep=rep1&type=pdf
- ^https://www.aclweb.org/anthology/W15-4007.pdf
- ^https://arxiv.org/abs/1611.04125
- ^https://arxiv.org/pdf/1904.04969.pdf
返回列表
终端基础:Linux终端中的目录切换 |