这篇教程DeepSeek R1本地化部署以及API调用写得很实用,希望能帮到您。
目录
收起
1、DeepSeek简介
2、本地化部署步骤
第一步:下载Ollama
第二步:通过命令行下载R1模型
第三步:安装可视化交互工具
3、通过API调用本地大模型
3.1 代码示例1:兼容OpenAI的接口调用:
3.2 代码示例2:使用ollama简易API:
3.3 代码示例3:基于历史消息的多轮问答:
4、总结
1、DeepSeek简介
最近火出圈的AI科技公司,不用多介绍了。


2、本地化部署步骤
网上已经有很多视频教程告诉大家如何部署了,过程其实非常简单,此处不再赘述了,只略作总结。另外,部署过程中最耗时的是资源和工具的下载。我把已经下载好的资源通过网盘分享出来,帮大家节约点时间。
总的来说,本地化部署DeepSeek R1,我总结了以下三个步骤,完成之后,你就可以愉快地与大模型聊天了,本地化部署之后的使用不依赖任何网络,零成本,用了都说好!
第一步:下载Ollama
进入Ollama网站,直接点击download即可(注意自己是windows还是mac还是Linux), 本教程以Windows为例,其余操作系统大同小异。
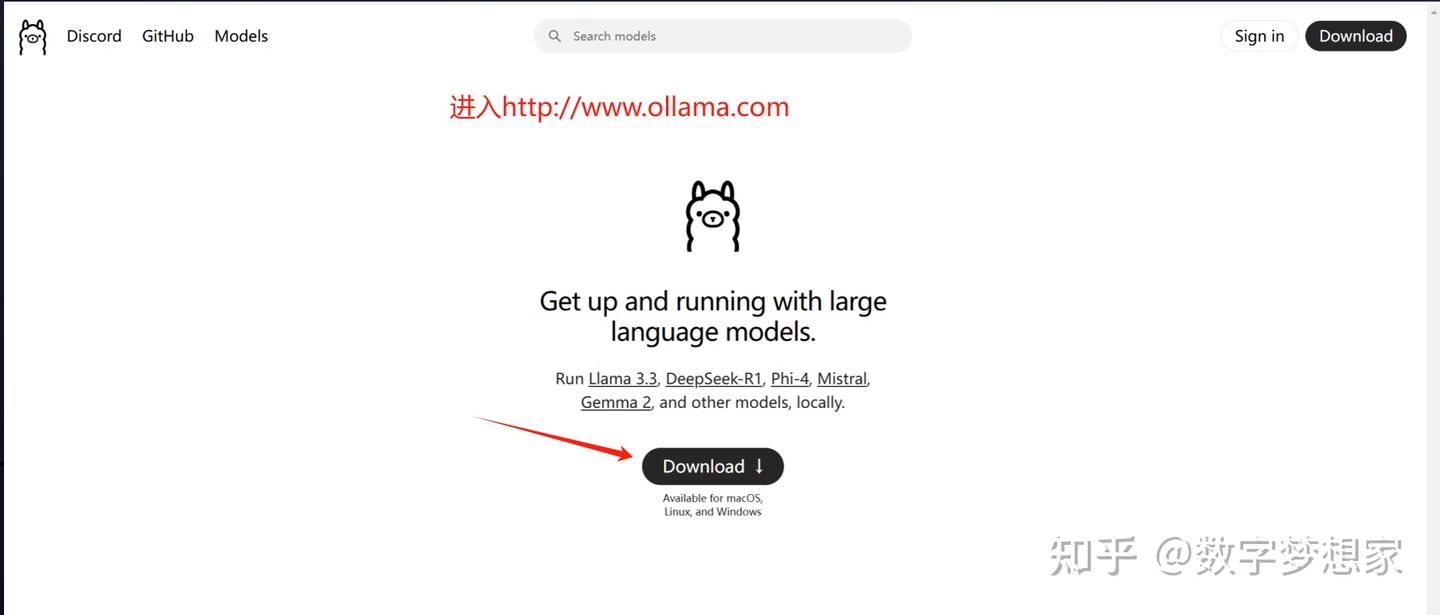

快速下载地址:通过网盘分享的文件:OllamaSetup.exe
链接: https://pan.baidu.com/s/1lDW71bAYdba71BHQpesNcg?pwd=j7vm 提取码: j7vm
第二步:通过命令行下载R1模型
这一步也很简单,直接进入DeepSeek R1模型下载页面:deepseek-r1
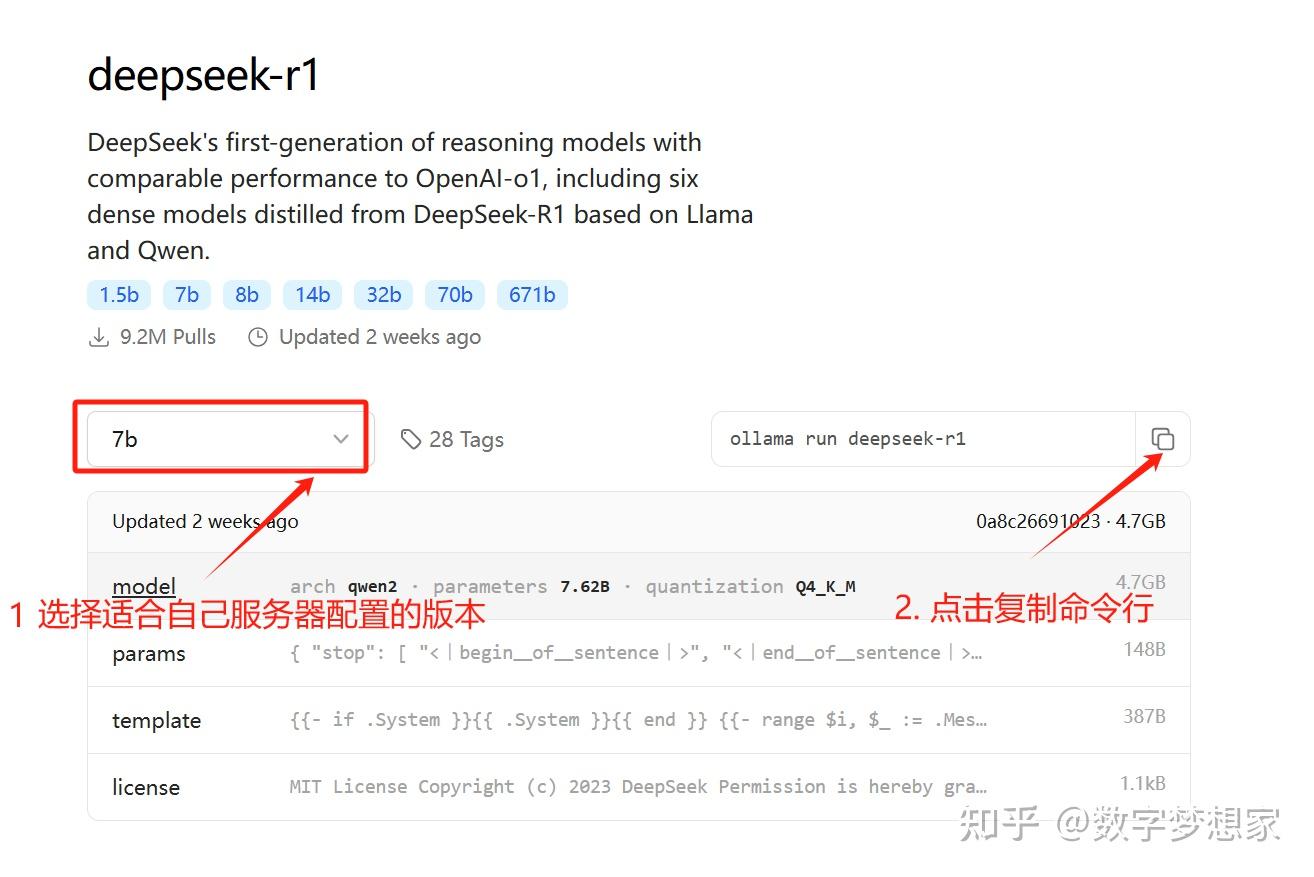
将复制的命令行,直接黏贴到命令行窗口按回车执行即可:

接下去就是一个较长时间的等待,等安装完毕就可以直接通过命令行与大模型交互了:
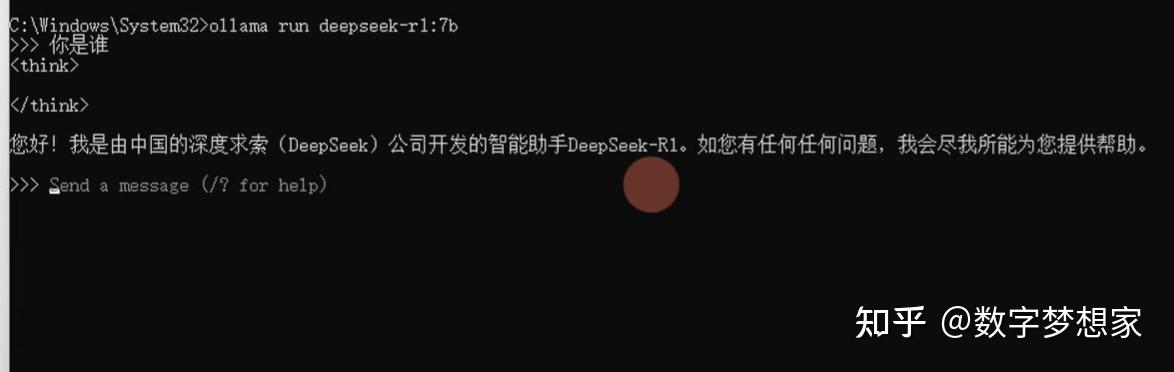
当然,这种交互方式还是不够人性化,所以接下去我们就需要安装一个客户端来连接本地大模型,并提供一个美观的交互UI,这样使用起来就方便多了。所以,我们接着做第三步:
第三步:安装可视化交互工具
现在比较流行的客户端有chatBox和Cherry Studio,此处推荐后者:
可以去官方(Cherry Studio - 全能的AI助手)下载,如果官方下载比较慢的话(如果不出意外的话,确实会比较慢),也可以直接通过我的网盘下载:
https://pan.baidu.com/s/1o6VeNhNycuSHEHQCFUhFnA?pwd=d97s 提取码: d97s
这个工具的安装没啥好说的,直接下一步点到底完成安装。
安装好之后,直接运行即可:
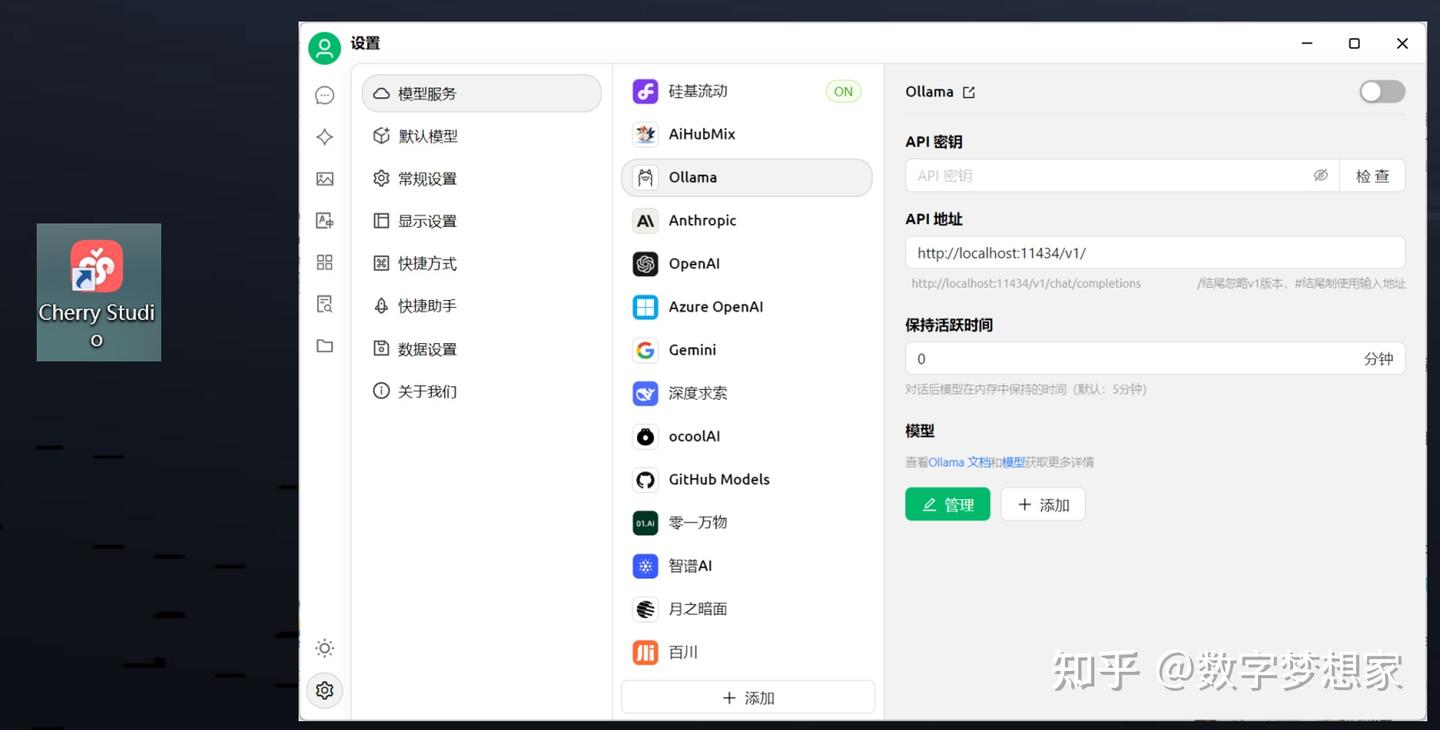
在上述界面中,点击左下角的小齿轮,进入ollama的配置界面,点击添加,把本地部署的模型添加进来:
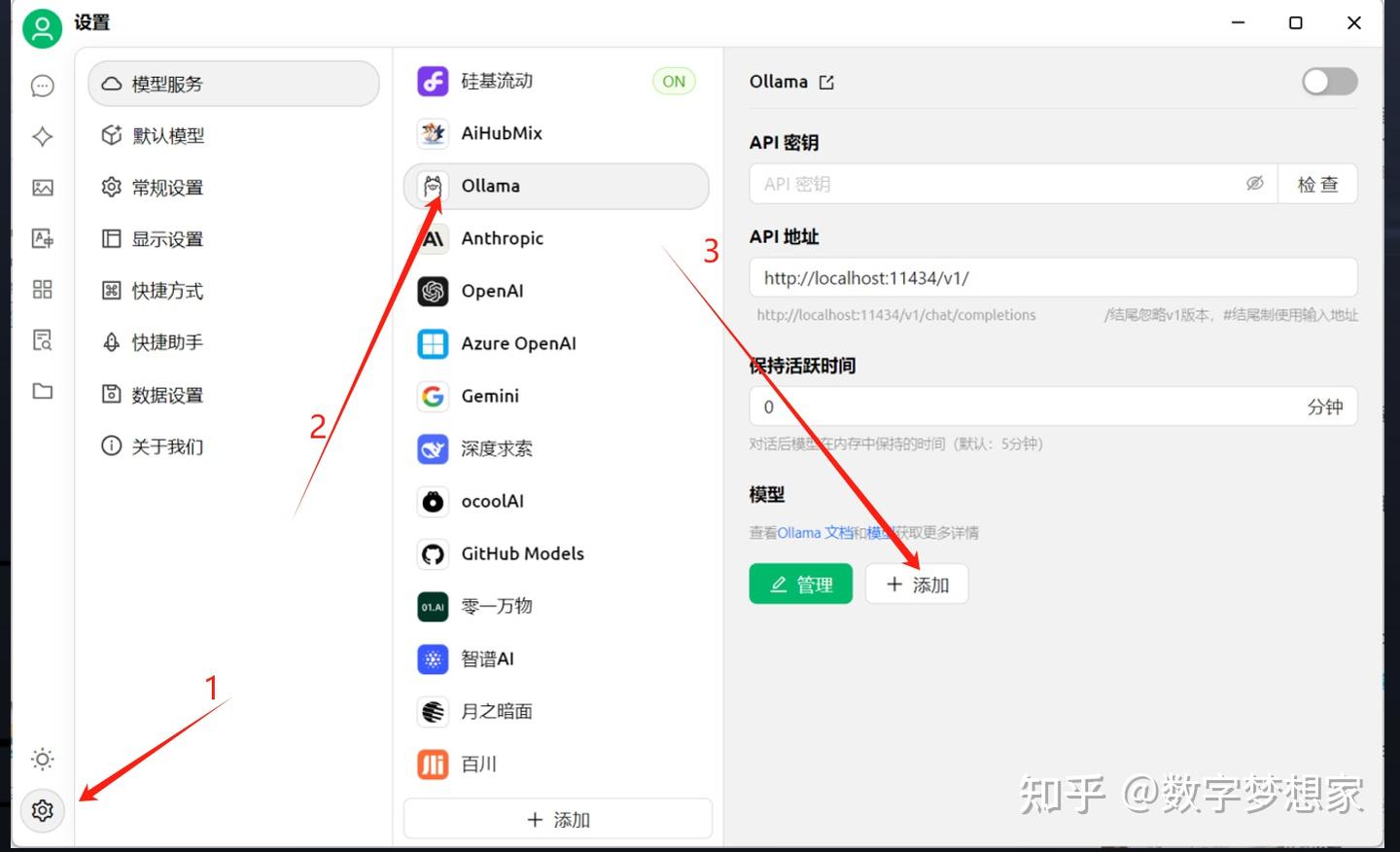
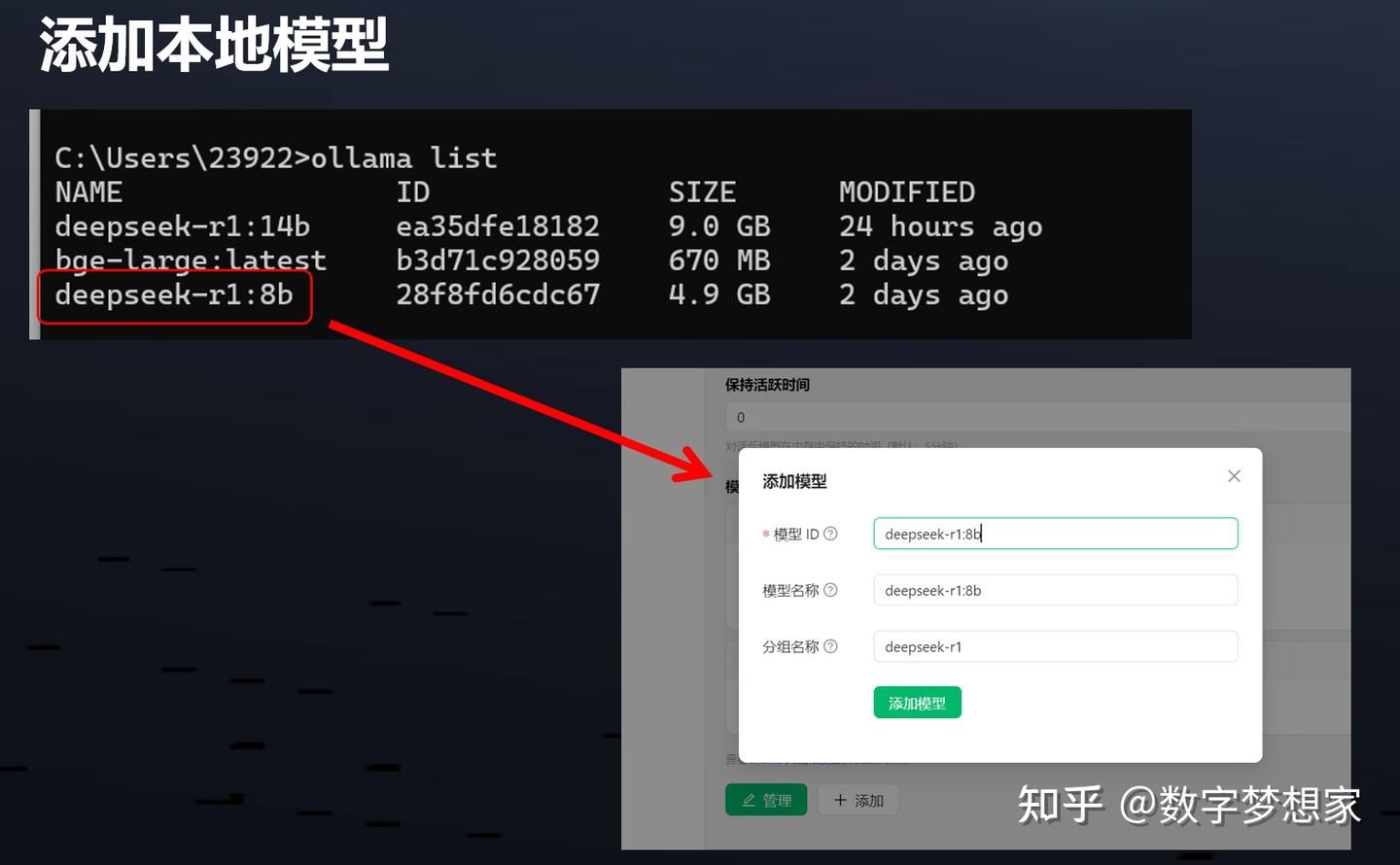 通过ollama list查找本地部署的模型,直接拷贝模型name即可
通过ollama list查找本地部署的模型,直接拷贝模型name即可
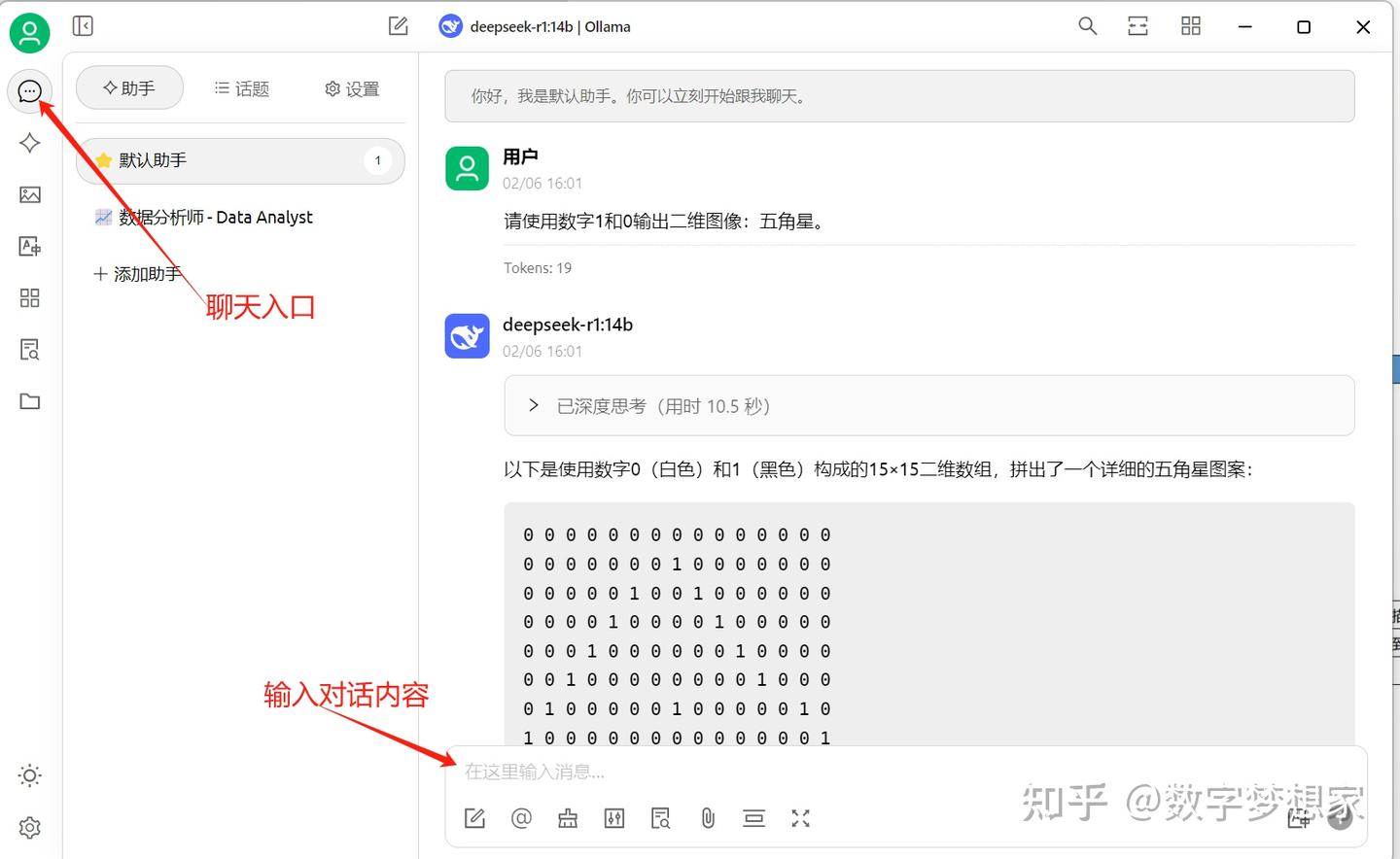
当在CherryStudio中添加了本地部署的deepSeek模型之后,就可以通过聊天入口进行聊天了:
3、通过API调用本地大模型
对于有开发需求的小伙伴来说,仅仅用一个客户端怎么能满足需求呢? 当然是要开启API模式,可以无拘无束地通过API集成的方式,集成到各种第三方系统和应用当中。
在本实例中,因为我们是基于Ollama框架运行了deepSeek R1模型,ollama相当于一个代理,我们直接调用ollama的API即可实现大模型接口的调用。
Ollama包装了完善的接口与大模型进行交互,详情可以自行查阅,在本例中,我们仅测试对话接口(chat)。
3.1 代码示例1:兼容OpenAI的接口调用:
import base64
from pathlib import Path
from openai import OpenAI
client = OpenAI(
base_url='http://localhost:11434/v1/',
# required but ignored
api_key='ollama',
)
chat_completion = client.chat.completions.create(
messages=[
{
'role': 'user',
'content': '9.9和9.11哪个更大?',
}
],
model='deepseek-r1:8b',
# stream=True,
temperature=0.0, # 可以根据需要调整温度值,决定生成的随机性程度
)
# 打印结果
print("模型返回的内容:")
print(chat_completion.choices[0].message.content)
# outputStr = ""
# for chunk in response_stream:
# outputStr += chunk.choices[0].delta.content
# print(chunk.choices[0].delta.content)
3.2 代码示例2:使用ollama简易API:
可以发现,使用Ollama封装的api明显简洁了很多:
from ollama import chat
from ollama import ChatResponse
response: ChatResponse = chat(model='deepseek-r1:8b', messages=[
{
'role': 'user',
'content': '请用python写一段代码,可获取A股所有的股票代码。',
},
])
print(response['message']['content'])
# or access fields directly from the response object
print(response.message.content)
3.3 代码示例3:基于历史消息的多轮问答:
from ollama import chat
messages = [
]
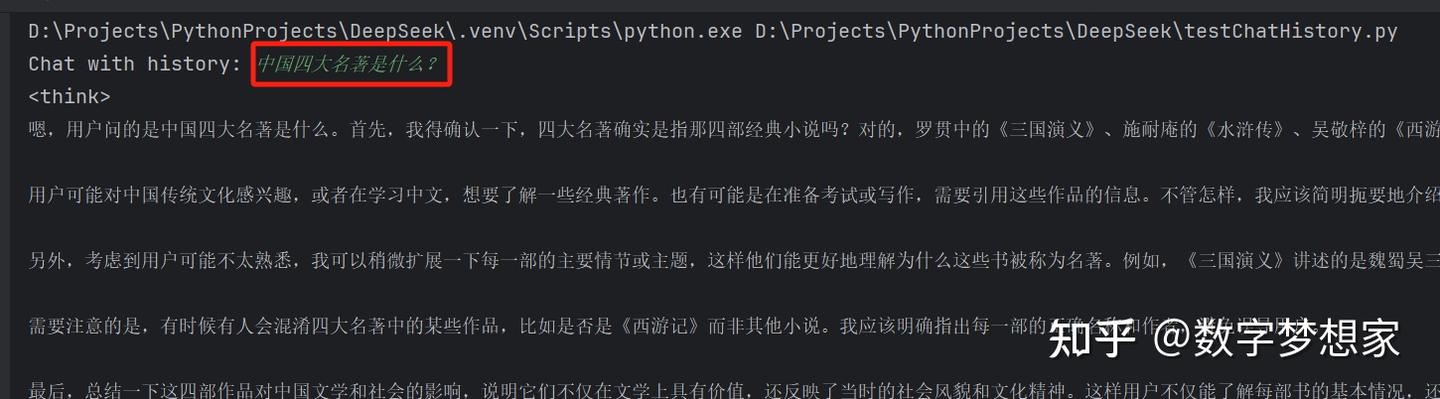
while True:
user_input = input('Chat with history: ')
response = chat(
'deepseek-r1:14b',
messages=messages
+ [
{'role': 'user', 'content': user_input},
],
)
# Add the response to the messages to maintain the history
messages += [
{'role': 'user', 'content': user_input},
{'role': 'assistant', 'content': response.message.content},
]
print(response.message.content + '\n')
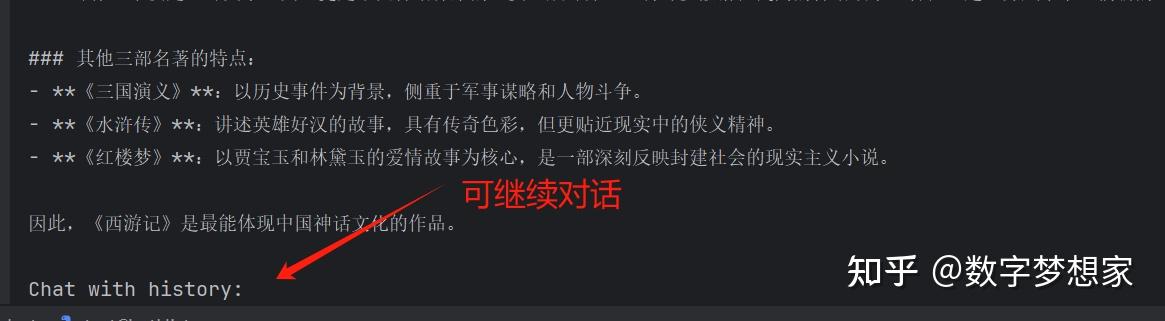
运行此代码,可以在控制台进行多轮交互问答,大模型每次都会基于既往已经回答的内容进行反馈,避免存在“失忆”的情况:

4、总结
总的来说,DeepSeek真的是普惠大众,国货之光!开源了这么优秀的大模型,为加速推进AI行业的发展做足了贡献。由于个人电脑配置(物理内存32G,显卡4060/8G)有限,只测试了8b, 14b两个模型,8b的版本理解力明显低于14b版本,一些初代模型都能很好回答的问题,8b版本竟不之所云。所以如果要对使用场景有一定要求的话,还是要使用更大参数量的版本。
返回列表
情感数据集大全 |