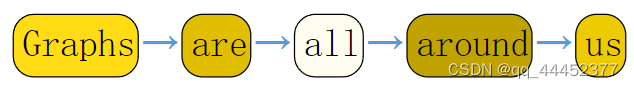这篇教程什么是图神经网络GNN?写得很实用,希望能帮到您。一、什么是GNN
一句话概括图神经网络(Graphic Nuaral Network,GNN): 将一个数据(一个图)输入到网络(GNN)中,会得到一个输出数据(同样是图),输出的图和输入的图相比,顶点、边、以及全局信息会发生一些改变。(注意,顶点之间的连接情况不会变,后面进行解释)
类似于一般的神经网络(DNN)一样,会对输入的数据进行改变得到输出数据,不同的是GNN的输入是一个图,输出也是一个图。
二、如何将数据表示成一个图(输入) 图是什么应该都很好理解,就是一些相互连接的顶点,那么,怎样将输入的数据表示成图的形式呢?GNN的输入到底是什么样的呢?
先说结论:GNN的输入包含以下几个部分,(1)顶点信息(2)边信息(3)全局信息(4)顶点之间的连接信息。这几个名词在下面的阅读中会慢慢理解。
为了更加形象的解释,举几个实际的例子:
第一个例子:
一张大小为5x5x3(3表示RGB通道,5x5表示图片长和宽)的图片,我们可以用下面的方法表示成一个图。
首先进行建模:
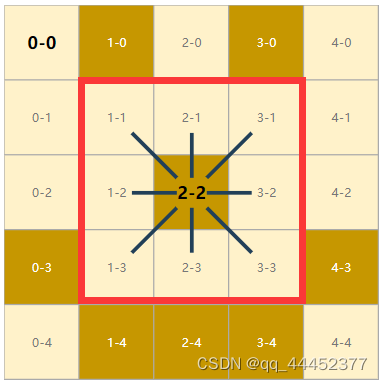
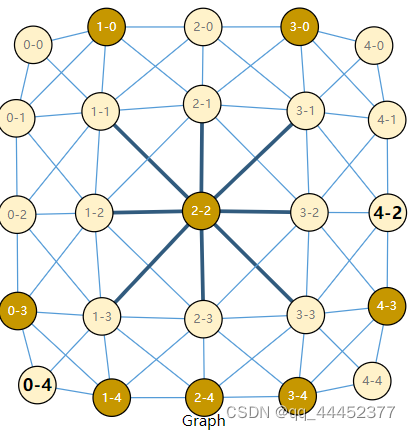
每一个像素在图中都表示成一个顶点,如果在图片中两个像素点是相邻关系,那么在图中,这两个顶点会有一条边进行相连。下面有个示例图(图1a和图1b)帮助理解,红色框里面的像素点都与2-2相邻,在图中他们之间会有边进行相连。
用数字表达一个图:
(1)每一个像素都有三个通道RGB,我们用一个三维向量 来表示每一个顶点, 所有顶点向量embedding组成一个顶点特征矩阵。 (这里就是一个25x3的矩阵)
(2)顶点的连接信息 可以用一个邻接矩阵 来表示。(这里就是一个25x25的矩阵)
(3)每条边也用一个有意义的向量embedding 来表示(比如像素之间的连接方向用向量表示出来),组成一个边的特征矩阵 (72x?的矩阵,?表示每条边的向量维度)
(4)全局信息embedding (比如这个图是否含有环就是一个全局信息)
所以最后输入到GNN中的数据就包括一个 顶点特征矩阵 、一个邻接矩阵、一个边的特征矩阵以及一个全局信息
图1a 图1b
第二个例子:
有一句话,包含这几个单词:Graphs are all around us。可以用下面的方式表示成一个图。
首先进行建模
就和下面的图2a一样,每个单词表示一个顶点,相邻的两个单词之间会有一条边相连
用数字表达一个图:
(1)每一个单词可以用一个向量embedding来编码,所有单词组成一个单词的特征矩阵
(2)顶点的连接情况可以用一个邻接矩阵来表示
(3)每一条边可以用一个有意义的向量embeddind来表示,所有边向量组成一个边的特征矩阵
(4)全局信息
所以最后输入到GNN中的数据就包括一个 顶点特征矩阵 、一个邻接矩阵、一个边的特征矩阵以及一个全局信息
总结一下:从上面的例子可以得出,输入到GNN中的一个图包含四个部分,一个顶点的特征矩阵 ,一个边的特征矩阵 ,一个顶点连接情况的邻接矩阵 以及一个全局信息 。
其中顶点的连接情况我们在稍后进行优化表示,用一个邻接表来表示,放弃使用邻接矩阵,这会有一些好处。全局信息比较抽象,会单独有一个部分进行讲解。
现实中还有很多数据可以用图来进行表示,比如在一个社交网络中,各个人物之间的关系。商品推荐系统中,不同客户之间、不同商品之间、以及商品和客户之间的关系。而且这些数据都有一个特点,就是组成非常复杂,这也是图神经网路的优点之一,可以处理极为复杂的网络关系。
三、训练过程
1、训练目标
想要了解GNN的训练过程,我们首先得知道GNN的最终目的是什么。
图上的预测任务一般分为三种类型:对图进行预测(也就是全局信息) 、对顶点信息进行预测 和对边信息进行预测 。
下面举一些例子来形象的解释每一种预测任务
在图级任务中 ,我们的目标是预测整个图的属性。 例如,对于以图形表示的一句话,我们可能想要预测这句话的语义,是一个陈述句还是一个疑问句,说话的人是高兴的还是生气的,这就是对图的全局信息进行预测。
那边级预测任务呢?
在边级预测任务中, GNN模型可用于预测顶点之间的关系(即每条边的信息)。 例如我们希望预测这些节点中的哪些节点共享一条边或该边的值是什么。
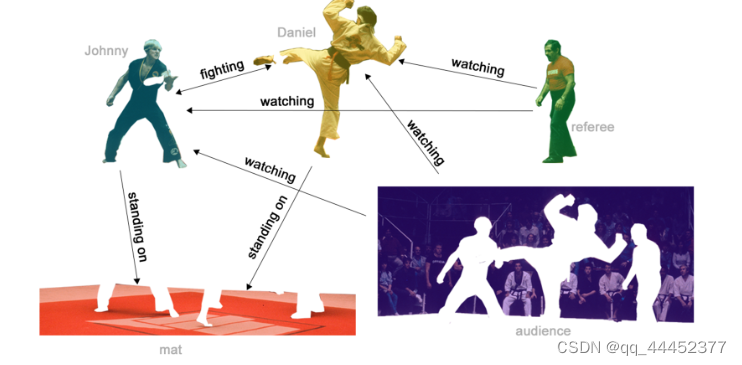
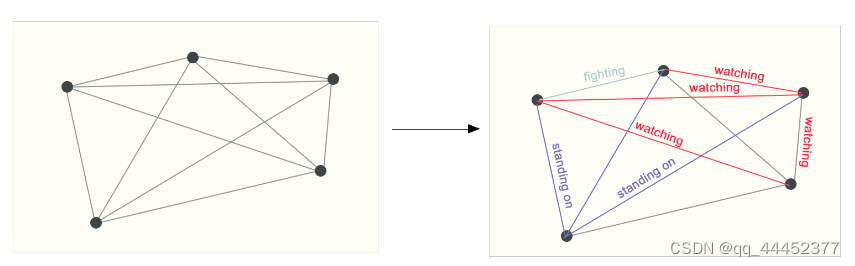
在一场搏击比赛中,现场有很多观众,台上有两个对抗者和一个裁判,我们可以把每个人看作是一个顶点,预测任务就是得出不同顶点之间的关系。我们用一张现场的图片来解释这个过程,图片中包含所有人物。对图2a进行抽象,得到图2b,对其进行预测得到每个人之间的关系(图2c中的每条边的标记)。
图2a
图2c
最后讲一下顶点级的预测
在顶点预测任务中 ,我们预测图中每个顶点的一些属性。
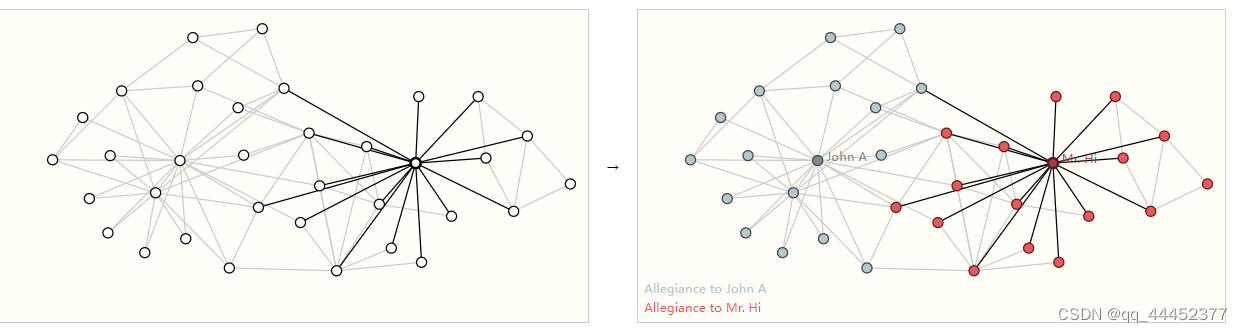
一个典型例子是 空手道俱乐部。 该数据集是一个单一的社交网络图,Hi先生(教练)和John H(管理员)之间的争执在空手道俱乐部造成了分裂。 每个空手道练习者是一个顶点,边代表这些成员之间的社交关系。预测问题是在Hi先生(教练)和John H(管理员)争执之后对给定成员是忠于 Mr. Hi (蓝色)还是 John H(红色) 进行分类。
2、GNN网络结构
下面使用消息传递神经网络 来构建GNN。 GNN采用“图入图出”架构,也就是说模型将图作为输入,改变图的信息后进行输出。
(1)最简单的GNN层
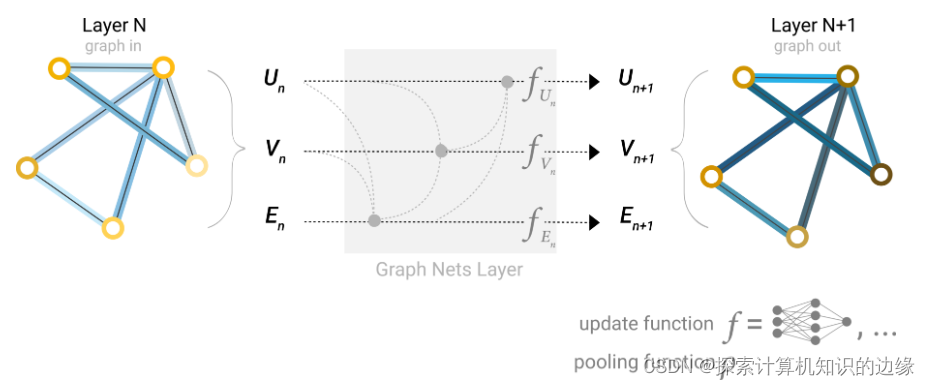
GNN的一层: 对顶点向量embedding、边向量embedding和全局向量embedding分别构造一个多层感知机(MLP) ,这三个MLP就共同组成了一个GNN的层,输入是embedding,输出也是embedding,embedding的值进行了更新,但维度不变。
顶点embedding,边embedding和全局embedding的输入-处理(MLP)-输出是分开进行的,因为有3个MLP,分别各自处理顶点、边或者全局信息
Un代表全局信息,Vn代表所有的顶点embedding,En代表所有的边embedding,每个f(带有下标)就是一个多层感知机,共同组成了GNN的一层。
多层这样的结构就构成了一个最简单的图神经网络
(2)对图信息进行预测
当一个图的embedding经过了多层GNN层的处理后,输出的embedding中可能就含有了大量丰富的信息,将这些embedding通过若干全连接层处理(或者其他分类器)就可以对顶点进行预测了
但是可能存在一些问题,例如,有一些顶点中信息缺失(embedding无法表征顶点的特点),但是和它相连的边以及全局含有有用的信息,我们就需要将边和全局的信息传递给对应的顶点。
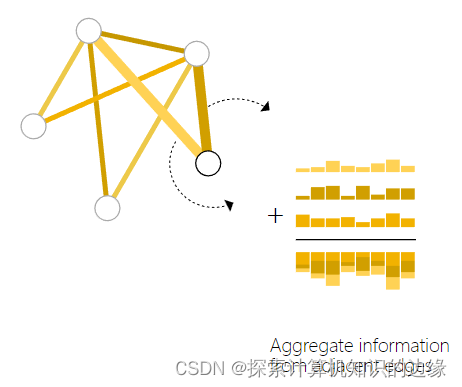
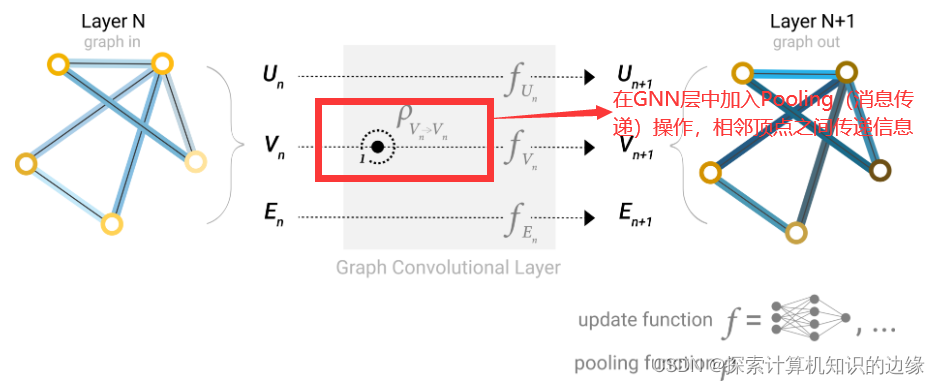
方法:将与该顶点相连接的边的embedding与全局embedding求和(或者其他方式),得到的结果加到顶点embedding中(如果维度不同需要做映射),如下图所示。这个方法我们称为Pooling
这样经过池化Pooling以后每个顶点中都含有丰富信息,对于边信息缺失或者全局信息缺失我们采用对称的方法进行处理,这里就不重复讲述了。
可以将最简单的GNN模型总结成如下的结构。
一张图输入,经过GNN层(实质上就是三个分别对应点、边和全局的MLP),输出一个属性已经变换的图,在经过全连接层,得到输出。
这只是最简单的GNN,因为我们没有在GNN层内使用图的连通性信息。 顶点、边和全局信息都是独立处理的,只在最后Pooling时使用了连通性信息。
(3)对GNN层进行优化
上面讲解的GNN层存在一个缺点,就是每一层GNN层单独地对顶点、边、全局信息进行处理,没有利用顶点之间的连接信息。
仔细的读者可能已经发现,GNN的输入有四个部分,顶点信息、边信息、全局信息、顶点之间的连接信息,但是目前为止,GNN层中只利用了前三种信息,那么如何有效利用顶点之间的连接信息呢?
我们从(2)对图信息进行预测 得到启发,考虑是否可以在每一层GNN层中加入Pooling,让相邻顶点、边、以及全局信息之间进行信息传递,而不是等到最后进行预测的时候才进行Pooling。 那么,在每一次Pooling(也就是消息传递)操作中我们就利用了顶点之间的连接信息,因为在进行消息传递的时候需要知道那些顶点是相邻的,每个顶点有哪些边。
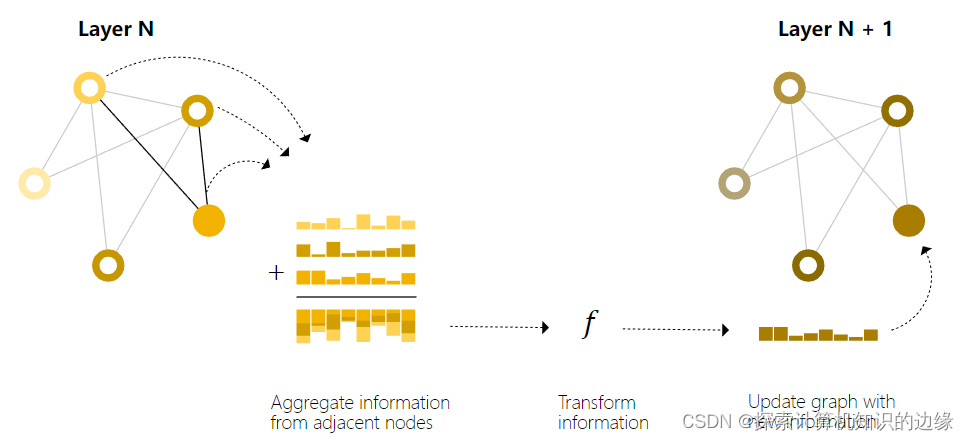
信息传递(或者说Pooling)包括三个步骤:
a. 对于图中的每个顶点,收集所有相邻顶点或边的embedding。
b. 通过聚合函数(如求和)聚合所有收集到的embedding。
c. 合并的embedding通过一个更新函数传递,通常是一个学习过的神经网络。
通过将消息传递 GNN 层堆叠在一起,一个节点最终可以整合来自整个图的信息:在三层之后,一个节点拥有离它三步之遥的节点的信息。
消息传递步骤
将加入了消息传递 的GNN 层堆叠在一起,一个顶点最终可以整合来自整个图的信息:在三层之后,一个顶点拥有离它三步距离的顶点的信息。我们将优化后的GNN模型用图来表示
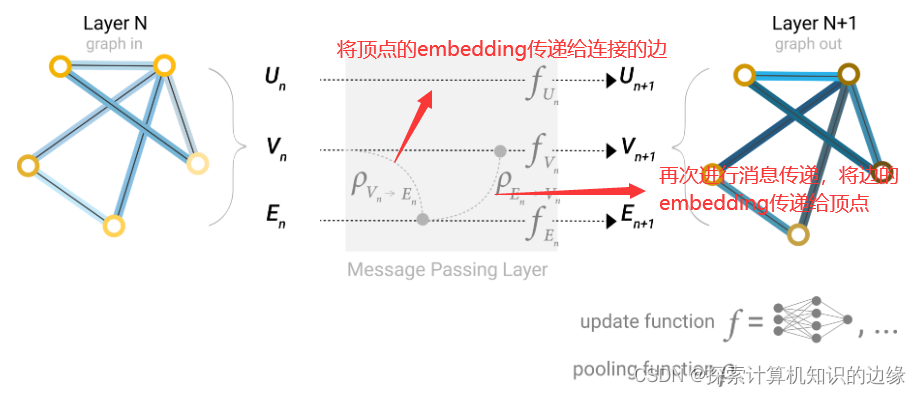
为了让GNN网络能更好的对图进行预测,提取出图中更加丰富的特征信息,我们不局限于在相邻顶点之间进行消息传递,顶点和边之间,边和边之间,顶点和全局信息之间,以及边和全局信息之间都可以进行消息传递。
之前的消息传递,只考虑了邻接的顶点和边,如果一个顶点想要聚合距离它很远的顶点和边的信息,怎么办呢?
为此提出master node(一个虚拟的顶点,它和图中所有的顶点和边虚拟地连接),这个顶点的embedding就是全局信息U。
在顶点信息传递给边的时候,也会把U一起传递,把边信息传递给顶点的时候,也会把U一起传递;然后更新边和顶点后,将边和顶点的信息一起汇聚给U,之后做MLP更新。