这篇教程Python使用OPENCV的目标跟踪算法实现自动视频标注效果写得很实用,希望能帮到您。
先上效果 
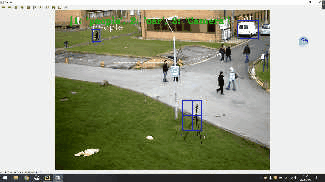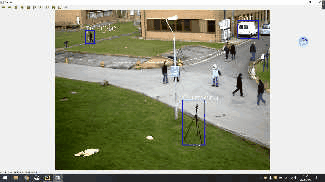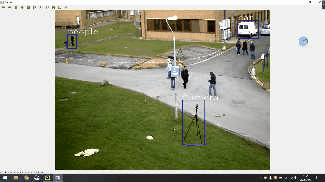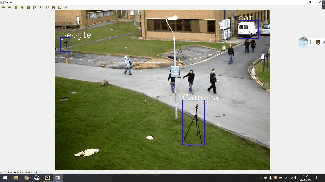
1.首先,要使用opencv的目标跟踪算法,必须要有opencv环境 使用:opencv==4.4.0 和 opencv-contrib-python==4.4.0.46,lxml 这三个环境包。 也可以使用以下方法进行下载 : pip install opencv-python==4.4.0
pip install opencv-contrib-python==4.4.0.4 pip install lxml
2.使用方法: (1):英文状态下的 “s” 是进行标注 (2):使用小键盘 1-9 按下对应的标签序号,标签序号和标签可自定义(需要提前定义) (3):对目标进行绘制 (4):按空格键继续 重复进行 (1)(2)(3)(4)步骤,可实现多个目标的跟踪绘制 英文状态下的 “r” 是所有清除绘制 英文状态下的 “q” 是退出 当被跟踪目标丢失时,自动清除所有绘制 import cv2import osimport timefrom lxml import etree #视频路径Vs = cv2.VideoCapture('peaple.avi')#自定义标签Label = {1:"people",2:"car",3:"Camera"}#图片保存路径 ,一定使用要用绝对路径!!imgpath = r"C:/Users/BGT/Desktop/opencv/img"#xml保存路径 ,一定使用要用绝对路径!!xmlpath = r"C:/Users/BGT/Desktop/opencv/xml"#设置视频缩放cv2.namedWindow("frame", 0)#设置视频宽高cv2.resizeWindow("frame", 618, 416) #定义生成xml类class Gen_Annotations: def __init__(self, json_info): self.root = etree.Element("annotation") child1 = etree.SubElement(self.root, "folder") child1.text = str(json_info["pic_dirname"]) child2 = etree.SubElement(self.root, "filename") child2.text = str(json_info["filename"]) child3 = etree.SubElement(self.root, "path") child3.text = str(json_info["pic_path"]) child4 = etree.SubElement(self.root, "source") child5 = etree.SubElement(child4, "database") child5.text = "My name is BGT" def set_size(self, witdh, height, channel): size = etree.SubElement(self.root, "size") widthn = etree.SubElement(size, "width") widthn.text = str(witdh) heightn = etree.SubElement(size, "height") heightn.text = str(height) channeln = etree.SubElement(size, "depth") channeln.text = str(channel) segmented = etree.SubElement(self.root, "segmented") segmented.text = "0" def savefile(self, filename): tree = etree.ElementTree(self.root) tree.write(filename, pretty_print=True, xml_declaration=False, encoding='utf-8') def add_pic_attr(self, label, x0, y0, x1, y1): object = etree.SubElement(self.root, "object") namen = etree.SubElement(object, "name") namen.text = label pose = etree.SubElement(object, "pose") pose.text = "Unspecified" truncated = etree.SubElement(object, "truncated") truncated.text = "0" difficult = etree.SubElement(object, "difficult") difficult.text = "0" bndbox = etree.SubElement(object, "bndbox") xminn = etree.SubElement(bndbox, "xmin") xminn.text = str(x0) yminn = etree.SubElement(bndbox, "ymin") yminn.text = str(y0) xmaxn = etree.SubElement(bndbox, "xmax") xmaxn.text = str(x1) ymaxn = etree.SubElement(bndbox, "ymax") ymaxn.text = str(y1) #定义生成xml的方法def voc_opencv_xml(a,b,c,d,e,f,boxes,Label,Label_a,save="1.xml"): json_info = {} json_info["pic_dirname"] = a json_info["pic_path"] = b json_info["filename"] = c anno = Gen_Annotations(json_info) anno.set_size(d, e, f) for box in range(len(boxes)): x,y,w,h = [int(v) for v in boxes[box]] anno.add_pic_attr(Label[Label_a[box]],x,y,x+w,y+h) anno.savefile(save) if __name__ == '__main__': Label_a = [] contents = os.path.split(imgpath)[1] trackers = cv2.MultiTracker_create() while True: Filename_jpg = str(time.time()).split(".")[0] + "_" + str(time.time()).split(".")[1] + ".jpg" Filename_xml = str(time.time()).split(".")[0] + "_" + str(time.time()).split(".")[1] + ".xml" path_Filename_jpg = os.path.join(imgpath,Filename_jpg) path_Filename_xml = os.path.join(xmlpath,Filename_xml) ret,frame = Vs.read() if not ret: break success,boxes = trackers.update(frame) if len(boxes)>0: cv2.imwrite(path_Filename_jpg, frame) judge = True else: judge = False if success==False: print("目标丢失") trackers = cv2.MultiTracker_create() Label_a = [] judge = False if judge: voc_opencv_xml(contents,Filename_jpg,path_Filename_jpg,frame.shape[1],frame.shape[0],frame.shape[2],boxes,Label,Label_a,path_Filename_xml) if judge: for box in range(len(boxes)): x,y,w,h = [int(v) for v in boxes[box]] cv2.putText(frame, Label[Label_a[box]], (x, y), cv2.FONT_HERSHEY_COMPLEX, 1, (255, 255, 255), 1) cv2.rectangle(frame,(x,y),(x+w,y+h),(255,0,0),2) cv2.imshow('frame',frame) var = cv2.waitKey(30) if var == ord('s'): imgzi = cv2.putText(frame, str(Label), (50, 50), cv2.FONT_HERSHEY_TRIPLEX, 1, (0, 255, 0), 2) cv2.imshow('frame', frame) var = cv2.waitKey(0) if var-48<len(Label) or var-48<=len(Label): Label_a.append(int(var-48)) box = cv2.selectROI("frame", frame, fromCenter=False,showCrosshair=True) tracker = cv2.TrackerCSRT_create() trackers.add(tracker,frame,box) elif var == ord("r"): trackers = cv2.MultiTracker_create() Label_a = [] elif var == ord('q'): #退出 break Vs.release() cv2.destroyAllWindows() 3.得到xml和img数据是VOC格式,img和xml文件以时间戳进行命名。防止同名覆盖。 
4.最后使用 labelImg软件 对获取到的img和xml进行最后的检查和微调 
到此这篇关于Python使用OPENCV的目标跟踪算法进自动视频标注效果的文章就介绍到这了,更多相关OPENCV目标跟踪自动视频标注内容请搜索51zixue.net以前的文章或继续浏览下面的相关文章希望大家以后多多支持51zixue.net!
脚本测试postman快速导出python接口测试过程示例
python教程十行代码教你语音转文字QQ微信聊天 |



