这篇教程Python常用的数据清洗方法详解写得很实用,希望能帮到您。
Python常用的数据清洗方法在数据处理的过程中,一般都需要进行数据的清洗工作,如数据集是否存在重复、是否存在缺失、数据是否具有完整性和一致性、数据中是否存在异常值等。当发现数据中存在如上可能的问题时,都需要有针对性地处理,本文介绍如何识别和处理重复观测、缺失值和异常值。
重复观测处理重复观测是指观测行存在重复的现象,重复观测的存在会影响数据分析和挖掘结果的准确性,所以在数学分析和建模之前,需要进行观测的重复性检验,如果存在重复观测,还需要进行重复项的删除。 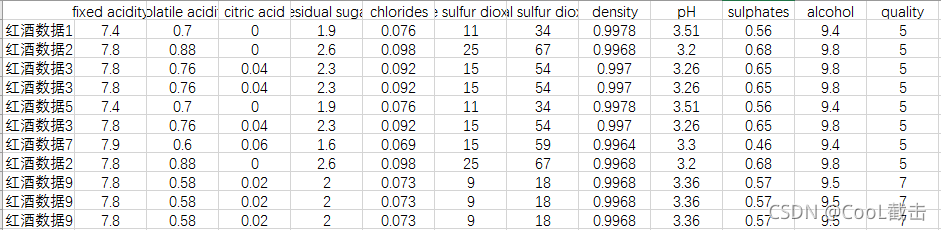
检测数据集的是否重复,pandas 使用duplicated方法,该方法返回的是数据行每一行的检验结果,即每一行返回一个bool值,再使用drop_duplicates方法移除重复值。 import pandas as pddataset= pd.read_csv("red_wine_repetition.csv")print("是否存在重复值:",any(dataset.duplicated())) #输出:Truedataset.drop_duplicates(inplace=True)dataset.to_csv('red_wine_repetition2.csv',index=False) #保存移除重复值后的数据集
缺失值处理数据缺失在大部分数据分析应用中都很常见,pandas使用浮点值NaN表示浮点或非浮点数组中的缺失数据,python内置的None值也会被当做缺失值处理。
pandas使用isnull方法检测是否为缺失值,检测对象的每个元素返回一个bool值 from numpy import NaNfrom pandas import Seriesdata=Series([5, None, 15, NaN, 25])print(data.isnull()) #输出每个元素的检测结果print('是否存在缺失值:',any(data.isnull())) #输出 :True缺失值的处理可以采用三种方法:过滤法、填充法和插值法。过滤法又称删除法,是指当缺失的观测比例非常低时(如5%以内),直接删除存在缺失的观测;或者当某变量缺失的观测比例非常高时(如85%以上),直接删除这些缺失的变量。填充法又称替换法,是指用某种常数直接替换那些缺失值,例如:对于连续值变量采用均值或中位数替换,对于离散值变量采用众数替换。插值法是指根据其他非缺失的变量或观测来预测缺失值,常见的插值法有线性插值法、KNN插值法和Lagrange插值法等。 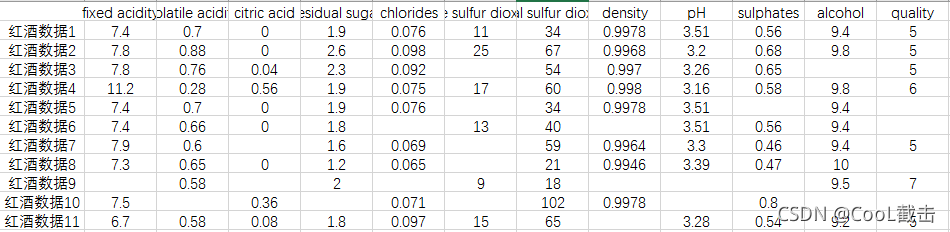
数据过滤数据过滤dropna 语法格式如下:dropna(axis=0, how='any', thresh=None)
(1)axis=0 表示删除行变量;axis=1 表示删除列变量
(2)how 参数可选值为any或all ,all表删除全为 NaN的行
(3)thresh 为整数类型,表示删除的条件 import pandas as pddataset= pd.read_csv("red_wine_deficiency.csv")data1=dataset.dropna() #删除所有的缺失值data2=dataset.dropna(axis=1, thresh=9) #删除有效属性小于9的列data3=dataset.drop("free sulfur dioxide", axis=1) #删除free sulfur dioxide的数据print(data1,'/n---------------/n',data2,'/n---------------/n',data3)
数据填充当数据中出现缺失值时,可以用其他的数值进行填充,常用的方法是fillna,其语法格式为:fillna(value=None, method=None, axis=None,inplace=Flase)
其中value值除了基本类型外,还可以使用字典,实现对不同的列填充不同的值,method 表示采用填充数据的方法,常用“ffill”、“bfill”。 import pandas as pddataset= pd.read_csv("red_wine_deficiency.csv")data1=dataset.fillna(0) #用0填补所有的缺失值data2=dataset.fillna(method='ffill') #用前一行的值填补缺失值data3=dataset.fillna(method='bfill') #用后一行的值填补缺失值,最后一行缺失不处理data4=dataset.fillna(value={'pH':dataset.pH.mode()[0], #使用众数填补 'density':dataset.density.mean(), #使用均值填补 'alcohol':dataset.alcohol.median()}) #使用中位数填补print(data1,'/n-----/n',data2,'/n-----/n',data3,'/n-----/n',data4)
插值法当出现缺失值时,也可以使用插值法来对缺失值进行插补,常见的方法为:'linear','nearest','zero','slinear','quadratic','cubic','spline','barycentric','polynomial'. import pandas as pddataset= pd.read_csv("red_wine_deficiency.csv")data=dataset.fillna(value={'pH':dataset.pH.mode()[0], #使用众数填补 'density':dataset.density.interpolate(method='polynomial',order=2), #使用二项式插值填补 'alcohol':dataset.alcohol.interpolate()}) #使用线性插值填补print(data)
异常值处理异常值是指那些远离正常值的观测值,异常值的出现会给模型的常见和预测产生严重的后果,但有时也会利用异常值进行异常数据查找。
对于异常值的检测,一般采用两种方法,一种是标准差法,另一种是箱线图判别法。标准差法的判别公式是outlier > x+nδ 或者outlier < x-nδ,其中x为样本均值,δ为样本标准差。当n=2时,满足条件的观测就是异常值;当n=3时,满足条件的观测就是极端异常值。箱线图的判别公式是outlier > Q3+nIQR 或者outlier < Q1-nIQR,其中Q1为下四分位数,Q3为上四分位数,IQR为上四分位数和下四分位数的差,当n=1.5时,满足条件的观测为异常值,当n=3时,满足条件的观测为极端异常值。
这两种方法的选择标准如下,如果数据近似服从正态分布,因为数据的分布相对比较对称,优先选择标准差法。否则优先选择箱线图法,因为分位数并不会受到极端值的影响。当数据存在异常时,若异常观测的比例不太大,一般可以使用删除法将异常值删除,也可以使用替换法,可以考虑使用低于判别上限的最大值替换上端异常值、高于判别下限的最小值替换下端异常值,或者使用均值、中位数替换 
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltdataset= pd.read_csv("red_wine_abnormal.csv")dataset=dataset['fixed acidity']mu=dataset.mean() #计算平均值δ=dataset.std() #计算标准差print('标准差法异常值上限检测:',any(dataset > mu+2*δ)) #输出:Trueprint('标准差法异常值下限检测:',any(dataset < mu-2*δ)) #输出:TrueQ1=dataset.quantile(0.25) #计算下四分位数Q3=dataset.quantile(0.75) #计算上四分位数IQR=Q3-Q1print('箱线图法异常值上限检测:',any(dataset > Q3+1.5*IQR)) #输出:Trueprint('箱线图法异常值下限检测:',any(dataset < Q1-1.5*IQR)) #输出:Trueplt.style.use('ggplot')dataset.plot(kind='hist',bins=30,density=True) dataset.plot(kind='kde')plt.show()#替换异常值UB=Q3+1.5*IQRst=dataset[dataset < UB].max() #找出低于判断上限的最大值dataset.loc[dataset >UB] = stplt.style.use('ggplot')dataset.plot(kind='hist',bins=30,density=True) dataset.plot(kind='kde')plt.show()运行不同dataset 得到的图像 (1)异常值处理前 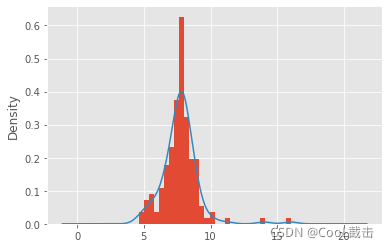
(2)替换异常值后 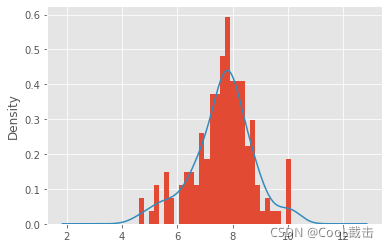
到此这篇关于Python常用的数据清洗方法详解的文章就介绍到这了,更多相关Python数据清洗方法内容请搜索wanshiok.com以前的文章或继续浏览下面的相关文章希望大家以后多多支持wanshiok.com!
Python 中如何使用 setLevel() 设置日志级别
用Python进行数据清洗以及值处理 |




