这篇教程Python自动检测requests所获得html文档的编码写得很实用,希望能帮到您。
使用chardet库自动检测requests所获得html文档的编码 使用requests和BeautifulSoup库获取某个页面带来的乱码问题 使用requests配合BeautifulSoup库,可以轻松地从网页中提取数据。但是,当网页返回的编码格式与Python默认的编码格式不一致时,就会导致乱码问题。 以如下代码为例,它会获取到一段乱码的html: import requestsfrom bs4 import BeautifulSoup# 目标 URLurl = 'https://finance.sina.com.cn/realstock/company/sh600050/nc.shtml'# 发送 HTTP GET 请求response = requests.get(url)# 检查请求是否成功if response.status_code == 200: # 获取网页内容 html_content = response.text # 使用 BeautifulSoup 解析 HTML 内容 soup = BeautifulSoup(html_content, 'html.parser') # 要查找的 ID target_id = 'hqDetails' # 查找具有特定 ID 的标签 element = soup.find(id=target_id) if element: # 获取该标签下的 HTML 内容 element_html = str(element) print(f"ID 为 {target_id} 的 HTML 内容:/n{element_html}/n") # 查找该标签下的所有 table 元素 tables = element.find_all('table') if tables: for i, table in enumerate(tables): print(f"第 {i+1} 个 table 的 HTML 内容:/n{table}/n") else: print(f"ID 为 {target_id} 的标签下没有 table 元素") else: print(f"未找到 ID 为 {target_id} 的标签")else: print(f"请求失败,状态码: {response.status_code}")
我们可以通过通过手工指定代码的方式来解决这个问题,例如在response.status_code == 200后,通过response.encoding = 'utf-8'指定代码,又或通过soup = BeautifulSoup(html_content, 'html.parser', from_encoding='utf-8') 来指定编码。 然而,当我们获取的html页面编码不确定的时候,有没有更好的办法让编码监测自动执行呢?这时候chardet编码监测库是一个很好的帮手。 使用 chardet 库自动检测编码 chardet 是一个用于自动检测字符编码的库,可以更准确地检测响应的编码。 安装chardet库 代码应用示例 import requestsfrom bs4 import BeautifulSoupimport chardet# 目标 URLurl = 'https://finance.sina.com.cn/realstock/company/sh600050/nc.shtml'# 发送 HTTP GET 请求response = requests.get(url)# 检查请求是否成功if response.status_code == 200: # 自动检测字符编码 detected_encoding = chardet.detect(response.content)['encoding'] # 设置响应的编码 response.encoding = detected_encoding # 获取网页内容 html_content = response.text # 使用 BeautifulSoup 解析 HTML 内容 soup = BeautifulSoup(html_content, 'html.parser') # 要查找的 ID target_id = 'hqDetails' # 查找具有特定 ID 的标签 element = soup.find(id=target_id) if element: # 获取该标签下的 HTML 内容 element_html = str(element) print(f"ID 为 {target_id} 的 HTML 内容:/n{element_html}/n") # 查找该标签下的所有 table 元素 tables = element.find_all('table') if tables: for i, table in enumerate(tables): print(f"第 {i+1} 个 table 的 HTML 内容:/n{table}/n") else: print(f"ID 为 {target_id} 的标签下没有 table 元素") else: print(f"未找到 ID 为 {target_id} 的标签")else: print(f"请求失败,状态码: {response.status_code}")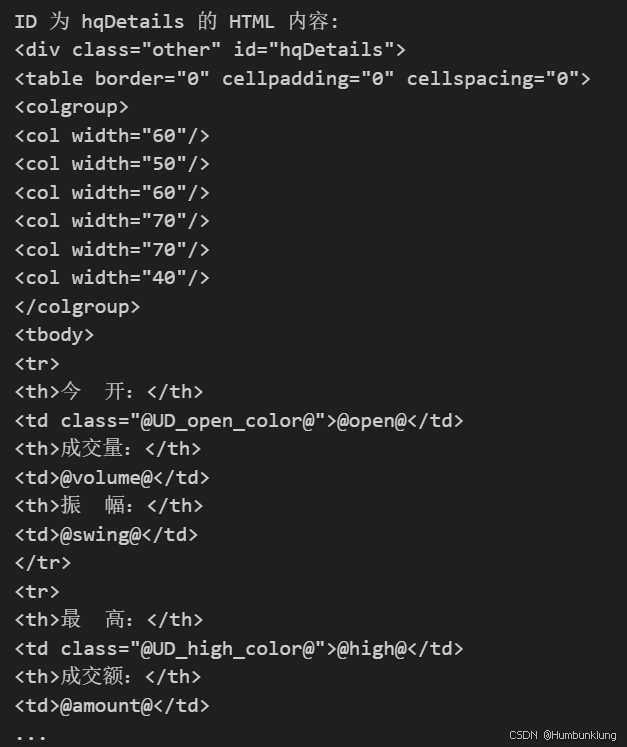
可见,通过使用chardet库,可以有效实现代码的自动检测。 以上就是Python自动检测requests所获得html文档的编码的详细内容,更多关于Python检测requests获得html文档编码的资料请关注本站其它相关文章!
python中的post请求解读
Python实战之使用PyQt5构建HTTP接口测试工具 |

