етЦЊНЬГЬДюНЈЭМЯёЫбЫїв§ЧцЃЈжЎ0ЃЉЃКЛєБШЬиШЫ&жБЗНЭМаДЕУКмЪЕгУЃЌЯЃЭћФмАяЕНФњЁЃ
ЗвыздЃК
Hobbits and Histograms – A How-To Guide to Building Your First Image Search Engine in Pythonhttp://www.pyimagesearch.com/2014/01/27/hobbits-and-histograms-a-how-to-guide-to-building-your-first-image-search-engine-in-python/
ЮвУЧНЋвЊДюНЈЕФетИіЭМЯёЫбЫїв§ЧцПДЩЯШЅСюШЫЩњЮЗЃЌЫќгаПЩФмЦЦЛЕСЫ“жСз№ФЇНф”ЃЌЖјУЛга“ЖдФЉШеЛ№ЩН”ЕФДѓЛ№ДјРДШЮКЮАяжњЁЃЕБШЛЃЌБОШЫвбОЖрДЮЙлЩЭСЫ“The Hobbit and the Lord of the Rings”ЃЌВЂВЛЖЯИцЫпздМКЃЌЪЧЪВУДСюШЫЩњЮЗФиЃПЦфЪЕвВжЛЪЧгУгАЦЌРяЕФНиЭМЖјвбЁЃ
вдЯТЪЧПьЫйИХРРЃК
ЮвУЧЕФФПБъЃКЪЙгУгАЦЌ“Hobbit and Lord of the Rings”ЃЌЕФНиЭМДгЭЗЕНЮВДюНЈЭМЦЌЫбЫїв§ЧцЁЃ
ФуНЋДгжабЇЕНЪВУДЃКАќРЈДњТыЪОР§дкФкЕФ4ИіДюНЈЭМЯёЫбЫїв§ЧцЕФБиаыВНжшЁЃДгетаЉР§ГЬЕБжаЃЌФуНЋФмАДздМКЕФЯыЗЈДюНЈЭМЦЌЫбЫїв§ЧцЁЃ
ФуашвЊзМБИЪВУДЃКPythonЃЌNumPyКЭOpenCVЁЃвЛаЉЭМЯёЛљБОИХФюЃЌБШШчЃКЯёЫиЁЂжБЗНЭМЁЃВЛЙ§етаЉВЛЪЧБиБИЃЌвђЮЊЃЌБОЮФНЋЪжАбЪжжИЕМФуЭъГЩЭМЦЌЫбЫїв§Ц№ЕФДюНЈЁЃ
ЮвЛЙУЛМћЙ§гаЙи“ШчКЮДюНЈЭМЦЌЫбЫїв§Чц”ЕФМђЕЅжИФЯЃЌЕБШЛетвВЪЧетЦЊВЉЮФЕФвтвхЫљдкЁЃЮвУЧНЋЪЙгУзюЛљБОЕФЭМЯёУшЪізг——жБЗНЭМЃЌРДСПЛЏКЭУшЪіетаЉНиЭМЁЃ
дкжЎЧАЕФЮФеТжаЬсЕНЙ§беЩЋжБЗНЭМЃЌШчЙћФуУЛЖСЙ§вВУЛЙиЯЕЃЌЕЋЮвНЈвщФуШчЙћЪЕдкВЛФмКмКУРэНтБОЮФФЧзюКУЛиЭЗШЅЖСЖСФЧЮФеТЁЃдкНјШыДюНЈЭМЯёЫбЫїв§ЧцжЎЧАЃЌШУЮвУЧПДПДЪ§ОнМЏ——“Hobbit and Lord of the Rings”ЕФНиЭМЁЃ

ЭМ1 Ъ§ОнМЏзмЙВга25еХЃЌЗжЮЊ5РрЃЌАќРЈСЫDol Guldur, Goblin Town, MordorЃЈBlack GateЃЉ, RivendellКЭShire
ШчЭМЫљЪОЃЌет25еХЭМЯёБЛЗжЮЊ5РрЃЌУПРргжАќКЌвдЯТГЁОАЃК
- Dol Guldur:ЫРСщЗЈЪІЕФЕиРЮ, SauronдкMirkwoodЕФДѓБОгЊ
- Goblin Town: УдЮэЩНТіЕФЪоШЫГЧеђ, б§ОЋЭѕЕФМв.
- Mordor/The Black Gate: SauronЕФБЄРнМАЛЗШЦЕФЩНТіКЭЛ№ЩНМЙЦНд.
- Rivendell: жаЭСЪРНчЕФОЋСщВПТф.
- The Shire:ЛєБШЬиШЫЕФЯчЭС.
вдЩЯЭМЦЌбЁзд“ The Hobbit: An Unexpected Journey”ЃЌ“ The Lord of the Rings”ЃЌ“The Return of the King.”ЁЃ
ФПБъЃК
ЪзЯШЮвУЧвЊЖдЪ§ОнМЏРяЕФ25еХЭМЯёНЈСЂЫїв§ЁЃетРяЃЌЮвУЧЭЈЙ§гУЭМЯёУшЪізгГщШЁУПЗљЭМЯёЕФЬиеїРДСПЛЏЭМЯёЪ§ОнМЏЃЌШЛКѓаЮГЩЫїв§ЃЌВЂНЋаЮГщШЁЕФЬиеїБЃДцвдБИКѓгУЃЌБШШчдЫааЫбЫїв§ЧцЁЃ
вЛИіЭМЯёУшЪізгОіЖЈСЫСПЛЏЕФжЪСПЃЌвђДЫЃЌГщШЁЭМЯёЬиеївВОЭГЦЮЊУшЪіЭМЯёЁЃвЛИіЭМЯёУшЪізгЕФЪфГіОЭЪЧвЛИіЬиеїЯђСПвВОЭЪЧЖдЭМЯёБОЩэЕФЬсШЁЁЃМђЖјбджЎЃЌОЭЪЧгУвЛСаЪ§зжРДДњБэвЛЗљЭМЯёЁЃСНИіЯђСППЩвдЭЈЙ§ОрРыЖШСПРДБШНЯЁЃЯђСПЕФОрРывВОЭУшЪіСЫЭМЯёЕФЯрЫЦГЬЖШЁЃжСгкЭМЦЌЫбЫїв§Ц№ЃЌЮвУЧИјГівЛИіВщбЏЭМЦЌЕФУшЪіЃЌВЂШУИљОнгыВщбЏЭМЦЌЕФЯрЫЦЖШдкЫїв§жаНЈСЂвЛИіХХађЁЃ
ПМТЧвЛЯТЯТУцетжжЗНЪНЃКЕБФудкGoogleЪфШы“Lord of the Rings”ЃЌФуЯЃЭћGoogleЗЕЛигыTolkienЕФЪщвдМАетВПгАЦЌЯрЙиЕФЭМЦЌЁЃРрЫЦЕФЃЌШчЙћЮвУЧгУЭМЦЌЫбЫїв§ЧцВщбЏЭМЦЌЃЌЮвУЧЯЃЭћЗЕЛиЕФЪЧФкШнЯрЙиЕФЭМЦЌ——вђДЫЃЌЮвУЧгаЪБКђАбЭМЦЌЫбЫїв§ЧцГЦЮЊбЇЪѕШІИќГЃМћЕФЛљгкФкШнЕФЭМЯёМьЫї(CBIR)ЯЕЭГЁЃ
ЫЕСЫетУДЖрЃЌФЧУДетИіЭМЦЌЫбЫїв§ЧцЕФФПБъЕНЕзЪЧЪВУДФиЃП
ФПБъОЭЪЧЃЌЕБИјЖЈвЛЗљет5РрЕФВщбЏЭМЦЌЕФЪБКђЃЌЗЕЛизюЯрЫЦЕФ10ИіЭМЯёЕФРрЃЈецЪЧЮогяЃЉЁЃЯТУцЮвУЧгУР§згРДЬНЧхетИіЫбЫїв§ЧцЁЃ
ШчЙћЮвЬсНЛвЛЗљЙигкShireЕФЭМЯёИјЮвУЧЕФЯЕЭГЃЌЮвНЋЯЃЭћЫћИјГіЕФЪЧЪ§ОнМЏРя10ИіНсЙћжаЕФ5ИіShireЭМЦЌЁЃЭЌбљЕФЃЌЕБЮвЬсНЛвЛЗљЙигкRivendellЕФЭМЯёИјЮвУЧЕФЯЕЭГЃЌЮвНЋЯЃЭћЫћИјГіЕФЪЧЪ§ОнМЏРя10ИіНсЙћжаЕФ5ИіRivendellЭМЦЌЁЃ
етвтвхдкФФЃПЮвУЧДгЯТУц4ИіДюНЈЭМЦЌЫбЫїв§ЧцВНжшЫЕЦ№ЁЃ
ДюНЈЭМЦЌЫбЫїв§ЧцЕФ4ИіВНжшЃК
1 ЖЈвхЭМЯёУшЪізгЃКФуНЋЪЙгУЪВУДЭМЯёУшЪізгРДУшЪібеЩЋЃЌЮЦРэЃЌаЮзДЃП
2 НЈСЂЪ§ОнМЏЫїв§ЃКгУФуЕФУшЪізгБэЪОЪ§ОнМЏЃЌГщШЁУПЗљЭМЯёЕФЬиеїЁЃ
3 ЖЈвхЯрЫЦЖШЃКФуШчКЮЖЈвхСНЗљЭМЯёЯрЫЦгыЗёЃПФуПЩФмЛсЪЙгУвЛаЉаЮЫЦЕФЯрЫЦЖШСПЃЌР§ШчГЃМћЕФХЗЪЯОрРыЃЌТќЙўЖйОрРыЃЌгрЯвОрРыЃЌПЈЗНОрРыЕШЁЃ
4 ЫбЫїЃКПЊЪМЫбЫїЕФЪБКђЃЌФувЊгУУшЪізгГщШЁЭМЯёЃЌИљОнФуЕФОрРыЖШСПРДХХСагыВщбЏЭМЯёЯрЫЦЕФЭМЯёЁЃЭЈЙ§ЯрЫЦЖШЖдНсЙћНјааХХађЃЌШЛКѓМьВтЁЃ
Step1ЃКУшЪізг——вЛИіШ§ЮЌЕФRGBбеЩЋжБЗНЭМ
ЮвУЧЕФУшЪізгЪЧвЛИіШ§ЮЌЕФRGBВЪЩЋПеМфжБЗНЭМЃЌКьТЬРЖЭЈЕРЖМЪЧ8ИіbinБэЪОЁЃНтЪЭвЛИіШ§ЮЌжБЗНЭМзюКУЕФЗНЪНЪЧСЌНг“гы”(AND)ЁЃУшЪізгНЋЛсВщбЏвЛЗљИјЖЈЕФЭМЯёгаЖрЩйКьЩЋЯёЫиТфШыЕквЛИіbin ВЂЧвгаЖрЩйТЬЩЋЯёЫиТфШыЕкЖўИіbin ВЂЧв гаЖрЩйРЖЩЋЯёЫиТфШыЕквЛИіbinЁЃетИіЙ§ГЬдкУПИіbinЕФСЌНгжаЛсвЛжБжиИДЃЌ етНЋЛсдкМЦЫуЛњРяИпаЇдЫааЁЃ
МЦЫувЛИі8binЕФШ§ЮЌжБЗНЭМЪБЃЌOpencVЪЧгУРрЫЦвЛИіЃЈ8,8,8ЃЉЕФЃЈШ§ЮЌЃЉЪ§зщРДДцДЂЬиеїЯђСПЁЃЮвУЧЖдЫќНјааМђЕЅЕФРЉГфжиЫмЕНЃЈ512ЃЌЃЉвЛЕЉРЉГфЭъЃЌЬиеїжЎМфЕФБШНЯОЭШнвзЖрСЫЁЃ
ЦШВЛМАД§ПДПДДњТыЃК
-
-
-
-
-
-
def __init__(self, bins):
-
-
-
-
def describe(self, image):
-
-
-
-
-
hist = cv2.calcHist([image], [0, 1, 2],
-
None, self.bins, [0, 256, 0, 256, 0, 256])
-
hist = cv2.normalize(hist)
-
-
-
е§ШчДњТыЫљЪОЃЌЮввбОЖЈвхСЫвЛИіRGBHistogramРрЃЌЮвИіШЫИќЧуЯђгкгУРрРДЖЈвхЭМЯёУшЪізгЖјВЛЪЧКЏЪ§ЁЃвђЮЊЮвУЧКмЩйЕЅЖРЖдвЛЗљЭМЯёНјааЬсШЁЬиеїЃЌЖјЪЧДгЪ§ОнМЏжаХњСПЬсШЁЁЃДЫЭтЃЌЮвУЧЯЃЭћДгЫљгаЭМЯё ЬсШЁЕФЬиеї гУЯрЭЌЕФВЮЪ§——етбљвЛРДОЭгаЯрЭЌИіЪ§ЕФbinЁЃШчЙћвЛЗљЭМЯёгУ32ИіbinБэЪОСэЭтвЛЗљШДгУ128ИіbinРДБэЪОЃЌ ФугУгУЫќУЧРД БШНЯЯрЫЦадФЧУЛЪВУДвтвхЁЃ
ДњТыЙ§ГЬЯъНтЃК
Lines 6-8: ЖЈвхRGBHistogramНсЙЙЬхЁЃЮЈвЛЕФВЮЪ§ОЭЪЧжБЗНЭМжаУПИіЭЈЕРbinЕФИіЪ§ЁЃдйДЮЫЕУїЃЌетОЭЪЧЮЊЪВУДЮвИќЯВЛЖгУРрЖјВЛЪЧгУКЏЪ§РДЪЕЯжУшЪізг——ЭЈЙ§ЪфШыНсЙЙЬхжаЕФЯрЙиВЮЪ§ЃЌФуФмШЗБЃЭМЯёФмЪЙгУетаЉЯрЭЌЕФВЮЪ§ЁЃ
line 10ЃЛВТВТПДЁЃЖЈвхетжжУшЪіЗНЗЈ; ИУЗНЗЈФмНЋвЛЗљЭМЯёЗЕЛивЛИіЬиеїЯђСПЁЃ
line 15ЃКЪЕМЪЬсШЁЕФШ§ЮЌRGBжБЗНЭМЃЈЪЕМЪЩЯЪЧBGRЃЌвђЮЊOpenCVЪЧАДееNumPyЪ§зщДцДЂЭМЯёЕФЃЌвВОЭЪЧЭЈЕРЫГађЕФЕїЛЛЃЉЁЃЮвУЧМйЩшself.binЪЧШ§ИіећЪ§ЕФСаБэЃЌжИЖЈСЫУПИіЭЈЕРЕФbinЕФИіЪ§ЁЃ
line 16ЃКИљОнЯёЫиМЦЪ§РДБъзМЛЏжБЗНЭМЪЎЗжживЊЁЃМйШчЮвУЧЪЙгУвЛЗљЭМЯёЕФдЪМЃЈећЪ§ЃЉЕФЯёЫиМЦЪ§ЃЌШЛКѓЫѕНј50%ЃЌдйДЮНјааУшЪіЃЌФЧУДЖдгкЭЌвЛЗљЭМОЭгаСНИіЬиеїЯђСПЃЌЫљвдвЊБмУтетжжЧщаЮЁЃЮвУЧЭЈЙ§НЋдЪМећЪ§МЦЪ§зЊЛЛЕНЪЕЪ§АйЗжБШРДЛёШЁЭМЯёГпЖШВЛБфадЁЃР§ШчЃЌЮвУЧЛсгУЕквЛИіbinеМСЫ20%ЕФЯёЫиЖјВЛЪЧЕквЛИіbinга120ИіЯёЫиЁЃдйДЮЫЕУїЃЌЭЈЙ§ЪЙгУЯёЫиМЦЪ§ЕФАйЗжБШЃЌПЩвдШУСНЗљжЛгадкГпДчЩЯгаВюБ№ЕФЭМЯёОпгаЯрЭЌЕФЬиеїЯђСПЁЃ
line 20ЃКМЦЪ§Ш§ЮЌжБЗНЭМЪБЃЌжБЗНЭМгУРрЫЦЃЈN,N,NЃЉbinЕФЗНЪНРДБэЪОЁЃЮЊСЫИќШнвзМЦЫужБЗНЭМЕФОрРыЃЌЮвУЧНЋШ§ЮЌЪ§зщРЉеЙЮЊЃЈN*N*NЃЌЃЉЕФвЛЮЌЪ§зщЁЃР§ШчЃЌЕБЮвУЧЪЕР§ЛЏRGBHistoramЕФЪБКђЃЌУПИіЭЈЕР8ИіbinЁЃУЛгаРЉеЙЕФЛАЃЌФЧУДжБЗНЭМЕФаЮЫЦЪЧЃЈ8,8,8ЃЉЕФЪ§зщЁЃЭЈЙ§РЉеЙжБЗНЭМЃЌаЮШчЃЈ512ЃЌЃЉЕФЪ§зщОЭЗНБуЖрСЫЁЃ
Step 2ЃКЫїв§Ъ§ОнМЏ
ЯждкЮвУЧвбОгУШ§ЮЌжБЗНЭМзїЮЊЭМЯёУшЪізгЃЌЯТвЛВНОЭЪЧНЋетИіЭМЯёУшЪізггІгУгкЪ§ОнМЏжЎжаЁЃетОЭвтЮЖзХЮвУЧвЊШЅбЛЗБщРњет25еХЭМЯёЪ§ОнЃЌДгУПЗљЭМЯёжаЬсШЁШ§ЮЌжБЗНЭМЃЌШЛКѓДцЮЊзжЕфЃЌаДЕНЮФМўжаЁЃЪЕМЪЩЯЃЌПЩАДФуЫљашНЈСЂМђЕЅЛђепИДдгЕФЫїв§ЁЃЫїв§ЪЧвЛжжКмШнвзВЂаадЫааЕФШЮЮёЁЃШчЙћЮвУЧгаЫФКЫЕФЛњЦїЃЌПЩвдЭЈЙ§ЗжХфЫФИіКЫЕФЙЄзїЬсИпЫїв§Й§ГЬЫйЖШЁЃЕЋЪЧЮвУЧжЛга25ИіЭМЯёЃЌФЧбљзігаЕугоДРЃЌгШЦфПМТЧЕНМЦЫужБЗНЭМЕФЫйЖШЁЃ
МћДњТыЃК
-
-
from pyimagesearch.rgbhistogram import RGBHistogram
-
-
-
-
-
-
-
ap = argparse.ArgumentParser()
-
ap.add_argument("-d", "--dataset", required = True,
-
help = "Path to the directory that contains the images to be indexed")
-
ap.add_argument("-i", "--index", required = True,
-
help = "Path to where the computed index will be stored")
-
args = vars(ap.parse_args())
-
-
-
-
-
ЪзЯШЃЌЕМШыЮвУЧЫљашвЊЕФАќЁЃЮввбООіЖЈНЋRGBHistoramРрДцЗХдк pyimagesearchЕФвЛИіФЃПщЕБжаЁЃетРягУcPickleНЋЪ§ОнзЊДЂЕНДХХЬЁЃгУglobКЏЪ§ЛёШЁНЋвЊЫїв§ЕФЭМЯёТЗОЖЁЃ"--dataset"ВЮЪ§ОЭЪЧЭМЯёЪ§ОнЕФТЗОЖЃЌ“--index”бЁЯюЪЧМЦЫуКѓЫїв§ДцЗХЕФТЗОЖЁЃзюКѓЃЌгУPythonзжЕфФкжУЕФРраЭГѕЪМЛЏЫїв§ЁЃзжЕфЕФЙиМќзжОЭЪЧЭМЯёЮФМўУћЃЌВЂМйЩшЫљгаЕФЮФМўУћЮЈвЛЃЌЪТЪЕЩЯвВЪЧШчДЫЁЃзжЕфЕФжЕОЭЪЧМЦЫуГіЭМЯёЕФжБЗНЭМЁЃ
ЪЙгУзжЕфЖдгкБОР§РДЫЕОпгаКмДѓЕФвтвхЃЌЬиБ№ЪЧЖдгкНтЪЭФПЕФЁЃИјЖЈвЛИіМќжЕЃЌзжЕфОЭжИЯђвЛаЉФПБъЁЃЕБгУЮФМўУћзїЮЊМќЃЌжБЗНЭМзїЮЊжЕЃЌФЧОЭвтЮЖзХЖдгквЛИіИјЖЈЕФжБЗНЭМHЪЧгУРДСПЛЏКЭБэЪОЮФМўУћЮЊKЕФЭМЯёЁЃИќИДдгЕФУшЪізггУДЪЦЕ—ЗДЮФЕЕЦЕТЪЃЈTF-IDFЃЉМгШЈКЭЗДЯђЫїв§ЃЌЕЋЮвУЧвЊБмУтетаЉЁЃВЛЙ§Б№ЕЃаФЃЌЮвНЋДјРДИќЖрЕФВЉЮФЬжТлШчКЮЪЙгУИќИДдгЕФММЪѕЃЌЕЋзїЮЊШыУХЃЌДгМђЕЅПЊЪМЁЃ
-
-
-
desc = RGBHistogram([8, 8, 8])
етРяЮвУЧЪЕР§ЛЏСЫ RGBHistogramЁЃдйДЮЫЕУїЃЌУПИіКьТЬРЖЭЈЕР8ИіbinЁЃ
-
-
for imagePath in glob.glob(args["dataset"] + "/*.png"):
-
-
k = imagePath[imagePath.rfind("/") + 1:]
-
-
-
-
image = cv2.imread(imagePath)
-
features = desc.describe(image)
-
етЪЧЪЕМЪЕФЫїв§ЃЌЮвУЧЗжЮіЯТЃК
line 2ЃКгУglobзЅШЁЭМЯёТЗОЖЃЌПЊЪМбЛЗЪ§ОнМЏЁЃ
line 4ЃКЬсШЁзжЕфМќжЕЁЃбљБОЪ§ОнМЏЮФМўУћЮЈвЛЃЌЫљвдЮФМўУћБОЩэзувдГЩЮЊМќжЕЁЃ
line 8-10ЃКДгДХХЬМгдиЭМЯёЃЌШЛКѓгУRGBHistogramЬсШЁжБЗНЭМЃЌНЋжБЗНЭМДцДЂдкЫїв§ЁЃ
-
-
-
f = open(args["index"], "w")
-
f.write(cPickle.dumps(index))
-
жСДЫЃЌЮвУЧвбОНЈСЂКУСЫЫїв§ЃЌОЭНЋЫќаДШыДХХЬвдБужЎКѓЕФЫбЫїжЎгУЁЃ
step 3:ЫбЫї
вбОдкДХХЬЩЯНЈСЂСЫЫїв§ЃЌФЧОЭзМБИНјааЫбЫїАЩЁЃ
ГЬађРяашвЊвЛаЉДњТыРДЪЕЯжЪЕМЪЫбЫїЁЃФЧУДЃЌгІИУШчКЮБШНЯСНИіЬиеїЯђСПЃПШчКЮШЗЖЈЫќУЧЕФЯрЫЦЖШФиЃПЧвМћвдЯТДњТыЃК
-
-
-
-
-
def __init__(self, index):
-
-
-
-
def search(self, queryFeatures):
-
-
-
-
-
for (k, features) in self.index.items():
-
-
-
-
-
d = self.chi2_distance(features, queryFeatures)
-
-
-
-
-
-
-
-
-
-
-
results = sorted([(v, k) for (k, v) in results.items()])
-
-
-
-
-
def chi2_distance(self, histA, histB, eps = 1e-10):
-
-
d = 0.5 * np.sum([((a - b) ** 2) / (a + b + eps)
-
for (a, b) in zip(histA, histB)])
-
-
-
ЪзЯШЃЌетРяЕФДњТызЂЪЭОгЖрЃЌВЛБидквтга41аажЎЖрЃЌШчФуЫљСЯЃЌЮвОЭЪЧЯВЛЖДјЖрЕузЂЪЭЕФДњТыЃЌЮвУЧРДвЛПњОПОЙЁЃ
line 4-7ЃКЮвЫљзіЕФЕквЛМўЪТОЭЪЧЖЈвхвЛИіЫбЫїЦїРрКЭвЛИіжЛгавЛИіВЮЪ§ЕФЫїв§НсЙЙЬхЁЃИУЫїв§ЪЧЩшЖЈЮЊЮвУЧдкНЈСЂЫїв§ЪБаДШыЕНЮФМўЕФФЧИіЫїв§зжЕфЁЃ
line 11ЃКетРяЖЈвхвЛИізжЕфРДДцДЂНсЙћЁЃМќОЭЪЧЭМЯёЮФМўУћЃЈЫїв§РяЃЉЃЌжЕОЭЪЧВщбЏЭМЯёКЭИјЖЈЭМЯёЕФЯрЫЦЖШЁЃ
line 14-26ЃКетЪЧЪЕМЪЫбЫїДњТыЖЮЁЃЮвУЧБщРњЫїв§жаЕФЫљгаЭМЯёЮФМўУћКЭЖдгІЕФЬиеїЁЃгУПЈЗНОрРыРДБШНЯбеЩЋжБЗНЭМЃЌВЂАбМЦЫуЕФОрРыДцДЂдкзжЕфжаЃЌвВБэЪОСЫСНИіЭМЯёжЎМфЕФЯрЫЦГЬЖШЁЃ
line 30-33ЃКНЋНсЙћАДееЯрЙиадХХађЃЈПЈЗНОрРыдНаЁЃЌЯрЙиад/ЯрЫЦаддНДѓЃЉВЂЗЕЛиЁЃ
line 35-41ЃКетЖЮДњТыЖЈвхСЫБШНЯСНИіжБЗНЭМЕФПЈЗНОрРыКЏЪ§ЁЃЭЈГЃЃЌгУДѓЕФbinКЭаЁЕФbinЕФЧјБ№ВЂВЛживЊЃЌгІИУвЊгУМгШЈРДБэЪОЃЌПЈЗНОрРыЕФзїгУОЭдкгкДЫЁЃЭЌЪБЃЌгУвЛИіащжЕepsilonРДБмУтЬжбсЕФГ§вд0ДјРДЕФДэЮѓЁЃШчЙћЬиеїЯђСПЕФПЈЗНОрРыЮЊСуЃЌФЧУДСНЗљЭМЯёОЭБЛШЯЮЊЪЧвЛФЃвЛбљЕФЁЃЕУЕНЕФОрРыдНДѓЃЌЯрЫЦГЬЖШдНаЁЁЃ
ЯждкФуУїАзСЫАЩЃЌвЛИіPythonРр,ОЭПЩвдНЈСЂЫїв§КЭжДааЫбЫїЁЃНгЯТРДОЭЪЧШУЫбЫїЦїЙЄзїСЫЁЃ
зЂвтЃКЖдгкФЧаЉИќЧуЯђгкбЇЪѕЕФХѓгбЃЌФуЖджБЗНЭМОрРыЖШСПИааЫШЄЃЌПЩФмЛсЯыПДECCV2010ЛсвщЩЯЕФЃКThe Quadratic-Chi Histogram Distance FamilyЁЃ
Step 4ЃКжДааЫбЫї
зюКѓЃЌЮвУЧе§НгНќгкЭъГЩвЛИіЙІФмадЕФЭМЯёЫбЫїв§ЧцЁЃЕЋЪЧЛЙВЛЙЛЃЌЛЙашвЊвЛаЉЖюЭтЕФДњТыРДДІРэЭМЯёЕФдиШыКЭжДааЫбЫїЁЃ
-
-
from pyimagesearch.searcher import Searcher
-
-
-
-
-
-
-
ap = argparse.ArgumentParser()
-
ap.add_argument("-d", "--dataset", required = True,
-
help = "Path to the directory that contains the images we just indexed")
-
ap.add_argument("-i", "--index", required = True,
-
help = "Path to where we stored our index")
-
args = vars(ap.parse_args())
-
-
-
index = cPickle.loads(open(args["index"]).read())
-
searcher = Searcher(index)
живЊЕФЪТЯШРДЃКЕМШыЫљашвЊЕФАќЁЃПЩвдПДЕНЃЌЮввбОАбЫбЫїЦїРрДцДЂдкpyimagesearchФЃПщРяЁЃШЛКѓАДеежЎЧАНЈСЂЫїв§ВНжшРяЕФЗНЪНЖЈвхБфСПЁЃзюКѓЃЌгУcPickleРДдиШыЫїв§ВЂГѕЪМЛЏЫбЫїЦїЁЃ
-
-
-
for (query, queryFeatures) in index.items():
-
-
results = searcher.search(queryFeatures)
-
-
-
path = args["dataset"] + "/%s" % (query)
-
queryImage = cv2.imread(path)
-
cv2.imshow("Query", queryImage)
-
print "query: %s" % (query)
-
-
-
-
-
-
montageA = np.zeros((166 * 5, 400, 3), dtype = "uint8")
-
montageB = np.zeros((166 * 5, 400, 3), dtype = "uint8")
-
-
-
-
-
-
(score, imageName) = results[j]
-
path = args["dataset"] + "/%s" % (imageName)
-
result = cv2.imread(path)
-
print "\t%d. %s : %.3f" % (j + 1, imageName, score)
-
-
-
-
montageA[j * 166:(j + 1) * 166, :] = result
-
-
-
-
montageB[(j - 5) * 166:((j - 5) + 1) * 166, :] = result
-
-
-
cv2.imshow("Results 1-5", montageA)
-
cv2.imshow("Results 6-10", montageB)
-
ДѓВПЗжЕФДњТыДІРэЯдЪОНсЙћЃЌЪЕМЪЕФЫбЫїЖЏзїдкЕк31ааЁЃВЛЙмдѕУДбљЃЌПДПДдйЫЕЃК
line 3ЃКетРяНЋЫїв§ЕФУПеХЭМЦЌЕБзїВщбЏЭМЯёЃЌПДПДЛсЕУЕНЪВУДНсЙћЁЃе§ГЃЧщПіЯТЃЌВщбЏЭМЯёЪЧЭтВПЭМЯёЖјВЛЪЧЪ§ОнМЏЕФвЛВПЗжЃЌдкДЫжЎЧАЃЌЯШПДПДвЛаЉЪОР§ЫбЫїНсЙћЁЃ
line 5ЃКетЪЧЪЕМЪЫбЫїжДааВПЗжЃЌНЋЕБЧАЭМЯёзїЮЊВщбЏЭМЯёШЛКѓжДааЫбЫїЁЃ
line 8-11ЃКдиШыВЂЯдЪОВщбЏЭМЯёЁЃ
line 17-35ЃКЮЊСЫЯдЪОзюгХЕФ10ИіНсЙћЃЌЪЙгУСНИіЛьЦДЭМЯёЁЃЕквЛИіЯдЪОНсЙћ1-5ЃЌЕкЖўИіЯдЪО6-10ЁЃЭМЯёУћКЭОрРыдкЕк27ааЁЃ
line 38-40ЃКзюКѓЃЌЯёгУЛЇЯдЪОЫбЫїНсЙћЁЃ
ЯждкУїАзСЫАЩЃЌетОЭЪЧећИіPythonЯТЕФЭМЯёЫбЫїв§ЧцЃЌПДПДетЪЧШчКЮжДааЕФЁЃ
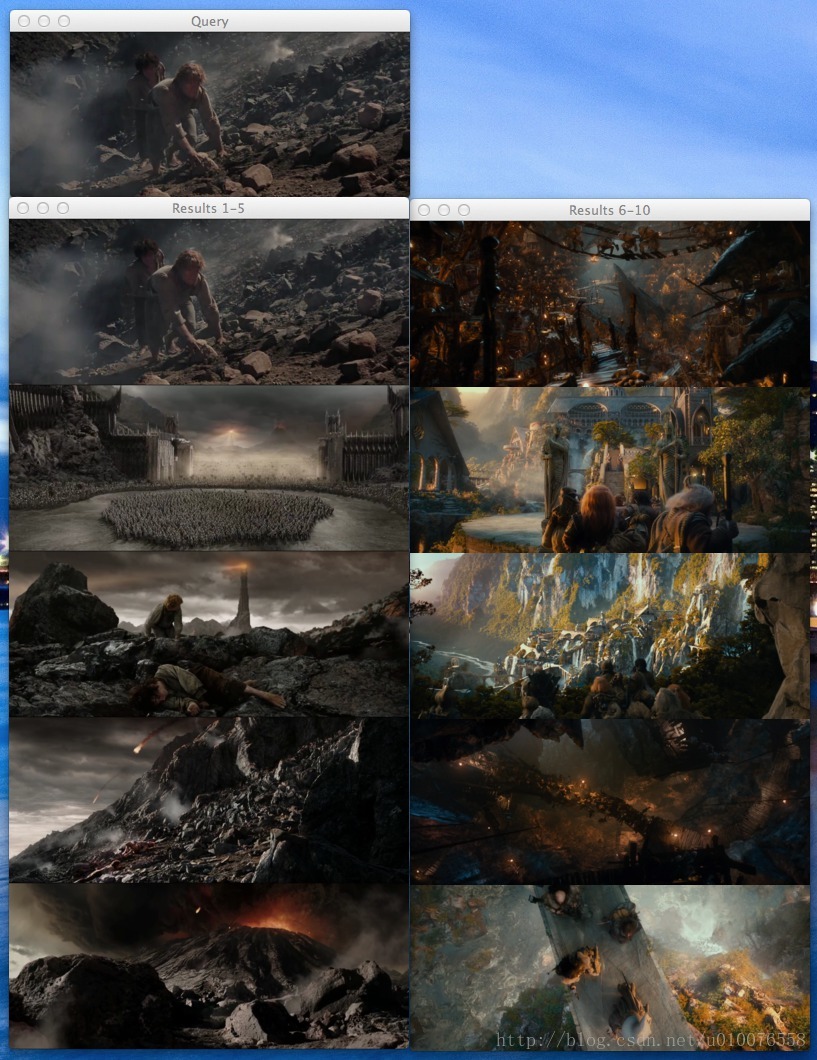
ЭМ2ЃКMordor-002.png зїЮЊВщбЏЭМЯёЕФНсЙћЁЃЮвУЧЕФЭМЯёЫбЫїв§ЧцЪЧФмЙЛДгMordorКЭBlack GateЗЕЛиНсЙћЭМЯёЕФЁЃ
Яждквд“The Return of the King ”ФЉЖЮжаFrodoКЭSamЩ§ШыЛ№ЩНПЊЪМзїЮЊВщбЏЭМЯёЁЃШчЭМЫљЪОЃЌ5Иі“Mordor”РрРязюКУЕФНсЙћЁЃ
вВаэФуЛЙВЛУїАзЮЊЪВУДFrodoКЭSamЕФВщбЏЭМЯёвВдкЫбЫїНсЙћЕФЕквЛЮЛЃПЛиЯывЛЯТЮвУЧЕФОрРыЖЈвхЃЌШчЙћСНЗљЭМЯёЪЧвЛФЃвЛбљЕФЃЌФЧУДОрРыЮЊ0ЁЃЖјЧвЃЌЮвУЧЪЙгУЕФВщбЏЭМЯёвВдкЫїв§ЭМЯёжЎжаЃЌФЧУДЫќУЧЕФОрРыБиЖЈЮЊ0ЃЌГіЯждкЫбЫїЕквЛЮЛВЛзуЮЊЦцСЫЁЃ
ЯждкЪдЪдЦфЫћЭМЯёАЩЃЌThe Goblin King in Goblin Town

ЭМ3ЃК Goblin-004.png зїЮЊВщбЏЭМЯёЕФЫбЫїНсЙћ
ОЋСщЭѕПДЦ№РДВЛЪЧФЧУДИпаЫЃЌЕЋЪЧЮвУЧШДКмИпаЫЃЌвђЮЊет5ИіGabin DownЕФЫбЫїНсЙћдкЧА10ИіНсЙћжаЁЃ
зюКѓЪЧ3Иі Rivendell, The ShireКЭDol-GuldurЕФЪОР§ЫбЫїНсЙћЁЃШчЭМЫљЪОЃЌЫљгаЕФИїздРрРяЕФЫбЫїНсЙћЖМдкећИібљБОЕФЧА10РяЁЃ

ЭМ4ЃК Dol-Guldur (Dol-Guldur-004.png), Rivendell (Rivendell-003.png),КЭThe Shire (Shire-002.png) зїЮЊВщбЏЭМЯёЕФЫбЫїНсЙћЁЃ
BonusЃКЭтВПВщбЏ
ЕНФПЧАЮЊжЙЃЌЮвУЧжЛПДЕНгУДцдкЫїв§РяЕФЭМЯёЕФзїЮЊВщбЏЭМЯёЕФЫбЫїНсЙћЃЌЕЋКмУїЯдЃЌетВЛЪЧЫїв§ЫбЫїв§ЧцЖМетУДИЩЃЌGoogleдЪаэФуЩЯДЋФуздМКЕФЭМЯёЃЌTinTyeвВШчДЫЃЌЮЊЪВУДЮвУЧВЛааФиЃПЯТУцРДПДПДШчКЮЫбЫїВЛдкЫїв§РяУцЕФЭМЯёЁЃ
-
-
from pyimagesearch.rgbhistogram import RGBHistogram
-
from pyimagesearch.searcher import Searcher
-
-
-
-
-
-
-
ap = argparse.ArgumentParser()
-
ap.add_argument("-d", "--dataset", required = True,
-
help = "Path to the directory that contains the images we just indexed")
-
ap.add_argument("-i", "--index", required = True,
-
help = "Path to where we stored our index")
-
ap.add_argument("-q", "--query", required = True,
-
help = "Path to query image")
-
args = vars(ap.parse_args())
-
-
-
-
queryImage = cv2.imread(args["query"])
-
cv2.imshow("Query", queryImage)
-
print "query: %s" % (args["query"])
-
-
-
-
-
-
desc = RGBHistogram([8, 8, 8])
-
queryFeatures = desc.describe(queryImage)
-
-
-
-
index = cPickle.loads(open(args["index"]).read())
-
searcher = Searcher(index)
-
results = searcher.search(queryFeatures)
-
-
-
-
-
-
-
montageA = np.zeros((166 * 5, 400, 3), dtype = "uint8")
-
montageB = np.zeros((166 * 5, 400, 3), dtype = "uint8")
-
-
-
-
-
-
-
(score, imageName) = results[j]
-
path = args["dataset"] + "/%s" % (imageName)
-
result = cv2.imread(path)
-
print "\t%d. %s : %.3f" % (j + 1, imageName, score)
-
-
-
-
-
montageA[j * 166:(j + 1) * 166, :] = result
-
-
-
-
-
montageB[(j - 5) * 166:((j - 5) + 1) * 166, :] = result
-
-
-
-
cv2.imshow("Results 1-5", montageA)
-
cv2.imshow("Results 6-10", montageB)
-
line 2-17ЃКетаЉгІИУЪЧОѕЕУЗЧГЃБъзМЕФЖЋЮїСЫЁЃЕМШыСЫАќЃЌНЈСЂСЫЮвУЧЕФВЮЪ§НтЮіЦїЃЌШЛЖјЃЌЛЙвЊзЂвтаТВЮЪ§——queryЁЃетЪЧВщбЏЭМЯёЕФТЗОЖЁЃ
line 20-21ЃКМДНЋдиШыВщбЏЭМЯёЃЌЯдЪОЭМЯёЃЌетПЩвдЗРжЙФуЭќМЧФувЊВщбЏЕФЭМЯёЪЧЪВУДФЃбљЁЃ
line 27-28ЃКгУКЭдкНЈСЂЫїв§ВНжшРяЯрЭЌЪ§СПЕФbinЪЕР§ЛЏRGBHistoramЁЃЮвгУДжЬхКЭаБЬхБэЪООЭЪЧЮЊСЫШУШЫУїАзгУЯрЭЌЕФВЮЪ§ЪЧЖрУДживЊЁЃШЛКѓОЭПЩвдДгВщбЏЭМЯёЬсШЁЬиеїЁЃ
line 31-33ЃКЪЙгУcPickleДгДХХЬдиШыЫїв§ЃЌжДааЫбЫїЁЃ
line 39-62ЃКОЭЯёЩЯЫпЕФДњТыжДааЫбЫїЃЌетРяЪЧЯдЪОНсЙћЁЃ
дкаДетЦЊВЉПЭжЎЧАЃЌЮвдкGoogleЯТдиСНеХВЛдкЮвУЧЕФЫїв§РяУцЕФЭМЯёЃЌRivendell КЭThe ShireИївЛЁЃетСНеХЭМЯёзїЮЊЮвУЧЕФВщбЏЭМЯёЃЌЫбЫїНсЙћШчЯТЃК

БОР§жаЫбЫїСЫгУСНеХЮДМћЙ§ЕФЭМЯёЃЌзѓБпЕФЪЧRivendellЃЌПЩвдПДЕНЯЕЭГЗЕЛиСЫЦфЫћ5еХЮвУЧЫїв§жаЕФRivendellНсЙћЭМЯёЁЃБэУїЮвУЧЕФЫбЫїв§ЧцЙЄзїВЛДэЁЃгвБпЕФЪЧThe ShireЃЌНсЙћдйДЮжЄУїЮвУЧЕФЭМЦЌЫбЫїв§ЧцФмЗЕЛигявхЯрЫЦЕФЭМЯёЁЃ
змНсЃК
дкБОВЉЮФжаЃЌЮвУЧбЇЯАСЫШчКЮДгЭЗЕНЮВДДНЈвЛИіЭМЯёЫбЫїв§ЧцЁЃЕквЛВНЪЧбЁдёЭМЯёУшЪізг——етРяЪЙгУШ§ЮЌRGBжБЗНЭМРДБэеїЭМЯёЁЃШЛКѓЮвУЧЭЈЙ§ЪЙгУУшЪізгЬсШЁЬиеїЯђСПЖдЪ§ОнМЏНЈСЂСЫЫїв§ЁЃжЎКѓгУПЈЗНОрРыЖЈвхЭМЯёЕФЯрЫЦЖШЁЃзюКѓЃЌЮвУЧАбетаЉСЌНгЦ№РДДДНЈСЫЭМЦЌЫбЫїв§ЧцЁЃ
ФЧУДЃЌЯТвЛВНФиЃП
ЮвУЧВХИеПЊЪМЃЌЛЙжЛЪЧЭъГЩЭМЦЌЫбЫїв§ЧцЕФЦЄУЋЃЌВЉЮФжаЕФММЪѕЛЙКмЛљБОЃЌЛЙгаКмЖрашвЊДюНЈЁЃР§ШчЃЌЮвУЧжЛзХСІгкгУжБЗНЭМзЅШЁВЪЩЋЃЌЕЋЪЧШчКЮЬсШЁЮЦРэЁЂаЮзДФиЃПЩёУиЕФSIFTУшЪізггжЪЧЪВУДбљЕФФиЃП
вдЩЯжжжжЮЪЬтНЋдкЮДРДМИИідТРяМћЗжЯўЁЃ
PythonЪ§ОнВЩМЏДІРэЗжЮіЭкОђПЩЪгЛЏгІгУЪЕР§НЬГЬ
pythonАбЖрИіЮФМўМажаЮФМўКЯВЂЕНвЛИіЮФМўМажа |