这篇教程Query、Key和Value是什么写得很实用,希望能帮到您。
首先抛出一张经典的self-attention计算图,
" target="_blank" title="链接" rel="noopener noreferrer"> https://pic1.zhimg.com/50/v2-3a806e404ec929266fcb917852aa2235_720w.jpg?source=1940ef5c"> 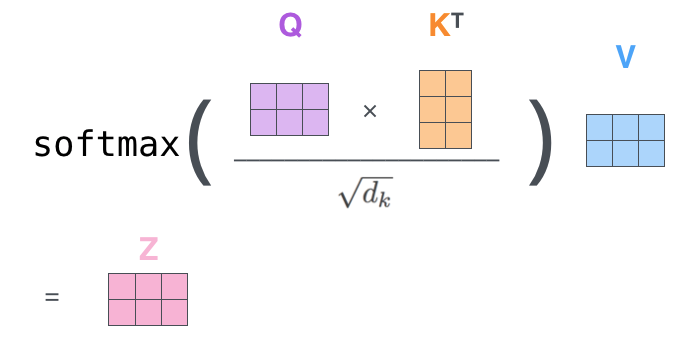
这里定义了三个关键元素:Query、Key和Value。QKV来自于同一个句子表征,Q是目标词 矩阵 ,K是关键词矩阵,V是原始特征,通过三步计算:
- Q和K计算相似度;
- softmax归一化,得到相似度权重;
- 将相似度权重和V 加权求和 ,得到强化表征Z。
下面贴一段代码:
可以看到QKV是通过输入特征X初始化,然后QK点积计算得到相似度矩阵,再经过Softmax归一化得到权重,作用于V上,得到强化表征Z。
class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim = -1)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
qkv = self.to_qkv(x).chunk(3, dim = -1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
attn = self.attend(dots)
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)
返回列表
Transformer 的 PyTorch 实现 |