参考书籍《Tensorflow+Keras 深度学习人工智能实践应用》林大贵著
第九章,第十章。
这是一本很通俗易懂的入门实践书,所有代码,事无巨细地进行了解释
CIFAR-10数据集是60000个32x32的彩色图像,分为10类,飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车。50000个训练图像,10000个测试图像
1.数据集处理
1-1. 下载CIFAR-10数据集
from keras.datasets import cifar10
import numpy as np
np.random.seed(10)
(x_image_train,y_label_train),\
(x_image_test,y_label_test)=cifar10.load_data()
- 1
- 2
- 3
- 4
- 5
- 6
cifar10.load_data()用于下载或者读取CIFAR-10数据集,第一次下载会花费一点时间
1-2. 查看训练数据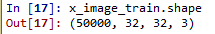
1-3.查看多项训练数据(label and image)
import matplotlib.pyplot as plt
label_dict={0:'airplane',1:'automobile',2:'bird',3:'cat',4:'deer',5:'dog',6:'frog',
7:'horse',8:'ship',9:'truck'}
#用字典dict定义每一个数字所代表的图像类别名称
def plot_images_labels_prediction(images,labels,prediction,idx,num=10):
fig=plt.gcf()
fig.set_size_inches(12,14)
if num>25: num=25
for i in range(0,num):
ax=plt.subplot(5,5,1+i)
ax.imshow(images[idx],cmap='binary')
title=str(i)+','+label_dict[labels[i][0]]
if len(prediction)>0:
title+='=>'+label_dict[prediction[i]]
ax.set_title(title,fontsize=10)
ax.set_xticks([]);ax.set_yticks([])
idx+=1
plt.show()
plot_images_labels_prediction(x_image_train,y_label_train,[],0)#查看训练数据前十项
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
![prediction=[],暂无prediction的查看](https://img-blog.csdnimg.cn/20190317094521751.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQxNjQ3NDM4,size_16,color_FFFFFF,t_70)
1-4.对image,label 数据进行预处理
image 标准化,label转换为独热码(One-Hot Encoding)
数字标准化可以提高模型的准确率,模型精度,提升模型收敛速度。
#image预处理 (RGB各通道除以255标准化)
x_image_train_norm=x_image_train.astype('float32')/255.0
x_image_test_norm=x_image_test.astype('float32')/255.0
x_image_train_norm[0][0][0]
- 1
- 2
- 3
- 4
查看了训练数据第一个图像第一个点的标准化结果,3个数据分别代表RGB
Out[12]: array([ 0.23137255, 0.24313726, 0.24705882], dtype=float32)
对label预处理
查看label形状,前5项数据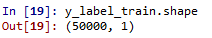

将label转为One-Hot Encoding
(0—(1000000000),1–(0100000000),6对应的就是----(0000001000))
#label 预处理
#Keras 提供了np_utils.to_categorical方法可进行One-Hot Encoding转换
from keras.utils import np_utils
y_label_train_OneHot=np_utils.to_categorical(y_label_train).reshape(50000,10)
y_label_test_OneHot=np_utils.to_categorical(y_label_test).reshape(10000,10)
- 1
- 2
- 3
- 4
- 5
输入:y_label_train_OneHot[:5]
2. Keras 卷积神经网络识别CIFAR-10图像
上接第一部分数据集下载和处理
2-1
卷积神经网络可分为两部分
图像特征提取:卷积层1(conv1),池化层1(pooling1),conv2,pooling2,提取图像特征。
完全连接神经网络:平坦层,隐藏层,输出层所组成的神经网络。
2-2 建立模型
卷积层、池化层、全连接网络(平坦、隐藏、输出层)线性堆叠
model.add() 为模型增加层
#2-1 建立模型
from keras.models import Sequential
from keras.layers import Dense,Dropout,Activation,Flatten
from keras.layers import Conv2D,MaxPooling2D,ZeroPadding2D
#建立线性堆叠模型,后续只要将各个神经网络加入模型即可
model=Sequential()
#建立卷积层1
model.add(Conv2D(filters=32,kernel_size=(3,3),input_shape=(32,32,3),
activation='relu',padding='same'))
#建立池化层1,将32x32的图像缩减为16x16的图像
model.add(MaxPooling2D(pool_size=(2,2)))
#建立卷积层2
model.add(Conv2D(filters=64,kernel_size=(3,3),activation='relu',padding='same'))
#加入Dropout避免过拟合
model.add(Dropout(0.25))
#建立池化层2
model.add(MaxPooling2D(pool_size=(2,2)))
#建立神经网络
#建立平坦层
model.add(Flatten())
model.add(Dropout(0.25))
#建立隐藏层
model.add(Dense(1024,activation='relu'))
model.add(Dropout(0.25))
#建立输出层
model.add(Dense(10,activation='softmax'))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- Conv1层参数
| filters=32, | 设置随机产生32个滤镜 |
|kernel_size=(3,3) |每个滤镜大小为3x3|
| padding=‘same’ |让卷积运算产生的卷积图像大小不变 |
|input_size=(32,32,3)|三维,前两维代表图像形状大小32x32,第3维代表是彩色图像,RGB三个通道 |
|activation=‘relu’ |设置该层激活函数为relu| - Pooling 1参数
- pool_size=(2,2),将32x32图像缩减为16x16
- Conv1层参数
| filters=64, | 设置随机产生64个滤镜 |
|kernel_size=(3,3) |每个滤镜大小为3x3|
| padding=‘same’ |让卷积运算产生的卷积图像大小不变 |
|activation=‘relu’ |设置该层激活函数为relu| - Dropout 避免过度拟合
- model.add(Dropout(0.25)) 每次训练迭代在神经网络放弃25%的神经元
剩下的参数设置和上面相似
输入:print(model.summary()) 查看模型摘要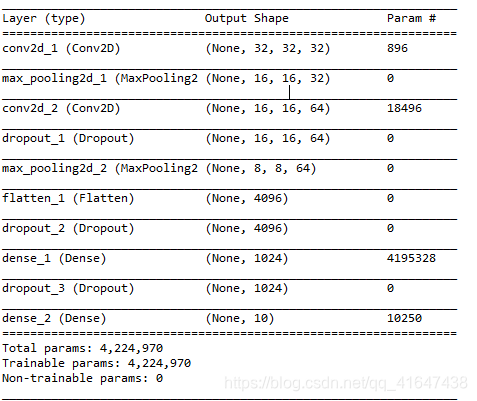
2-3 进行训练
#开始训练
train_history=model.fit(x=x_image_train_norm,y=y_label_train_OneHot,validation_split=0.2,
epochs=20,batch_size=128,verbose=2)
- 1
- 2
- 3
- loss:设置损失函数,在深度学习中使用交叉熵训练效果较好
- optimizer:在训练时,使用adam优化器可以让训练更快收敛,并提高准确率
- metrics设置评估模型的方式是准确率
- model.fit训练,训练过程存在train_history里面,model.fit需要的参数:
- 输入训练数据参数
- x_image_train_norm,y_label_train_OneHot
- 设置训练与验证数据的比例
- validation_split=0.2, 80%为训练数据(50000x0.8=40000),20%为验证数据
- epochs=20,网络训练20次
- batch_size=128,每批次128项数据,共40000/128=313个批次,每次网络训练要处理313个批次的数据
- verbose=2, 显示训练过程
2-3查看训练结果
查看准确率、损失执行过程
def show_train_history(train_history,train,validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train','validation'],loc='upper left')
plt.show()
show_train_history(train_history,'acc','val_acc')
plt.figure()
show_train_history(train_history,'loss','val_loss')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
结果: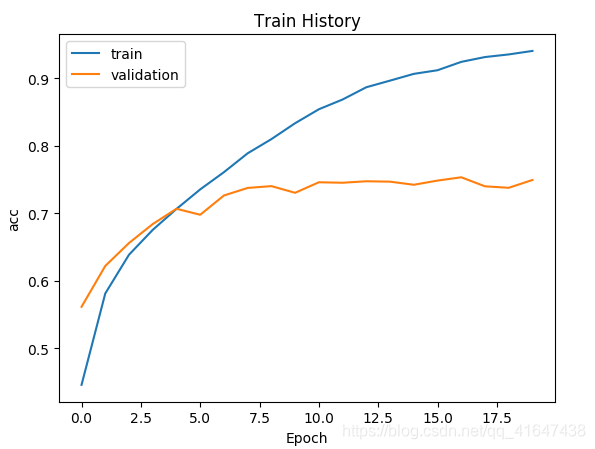
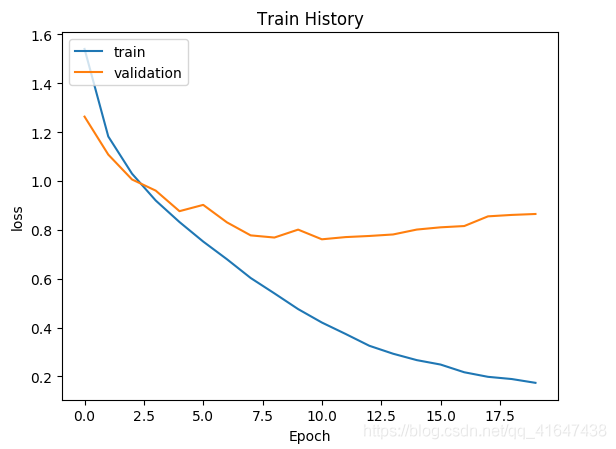
#查看模型正确率
scores=model.evaluate(x_image_test_norm,y_label_test_OneHot,verbose=1)
- 1
- 2

#2-4 进行预测
prediction=model.predict_classes(x_image_test_norm)
#预测结果,前10项数据
prediction[:10]
- 1
- 2
- 3
- 4
#显示前10项结果
plt.figure()
plot_images_labels_prediction(x_image_test,y_label_test,prediction,0,10)
- 1
- 2
- 3

2-5 显示预测概率
查看第1项test数据的概率(被分类为各类的概率)
#2-5 显示预测概率
#预测概率
Predicted_Probability=model.predict(x_image_test_norm)
def show_Predicted_Probability(y_label,prediction,x_image,
Predicted_Probabilty,i):
print('label:',label_dict[y_label[i][0]],
'predict',label_dict[prediction[i]])
plt.figure(figsize=(2,2))
plt.imshow(np.reshape(x_image_test[i],(32,32,3)))
plt.show()
for j in range(10):
print(label_dict[j]+' '+'Probability:%1.9f'%(Predicted_Probability[i][j]))
show_Predicted_Probability(y_label_test,prediction,x_image_test,Predicted_Probability,1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
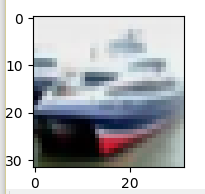
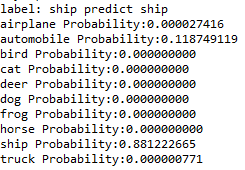
可以看出这张船图片,被分类为船的概率为0.8812,概率最高,最后预测结果是正确的,第0项是分类错误的,也可以查看概率,如上。
2-6 显示混淆矩阵
用pd.crosstab建立混淆矩阵,它的输入要求是一维数组,所有用y_label_test.shape,prediction.shape,分别查看是不是一维数,其中y_label_test为(10000,1),要用reshape,转换为一维数组
#2-6 显示混淆矩阵
y=y_label_test.reshape(-1) #将其转换为一维数组
import pandas as pd
print(label_dict)
pd.crosstab(y,prediction,rownames=['labels'],colnames=['predict'])
- 1
- 2
- 3
- 4
- 5
- 6

对角线是预测正确的,可以分析出最容易混淆的类别,和最不容易混淆的。
2-7 模型的加载与保存
每次训练卷积神经网络都会花费很长时间,,可以在每次完成训练后,保存模型,或者保存权重,下次执行训练先加载模型权重,再继续训练
'''
#2-7 模型的加载与保存
model.save('model.h5')
#保存模型权重
model.save_weights('my_model_weights.h5')
#下次使用的时候
model = load_model('model.h5')
model.load_weights('my_model_weights.h5')
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

在你保存脚本文件的文件夹就会出现保存好的h5文件
END
建立3次的卷积运算神经网络会进一步提高准确率。
遇到的问题:
1.小白问题,变量名手抖打错
2.注意关注维数,原书中的np_utils.to_categorical方法可进行One-Hot Encoding转换,转换后的形状却是(50000,1,10),后面进行网络训练报错,提示输出层需要输入一个二维向量,而收到的是(50000,1,10),所以我又去reshape了一下。也没查明白,这个np_utils.to_categorical怎么不好使了,在之前MNIST手写数字识别,这个就没什么问题。
更改为:
y_label_train_OneHot=np_utils.to_categorical(y_label_train).reshape(50000,10)