@staticmethoddef_get_split_mse(col:array,score:array,split:float):# Split score.score_left=score[col<split]score_right=score[col>=split]# Calculate the means of score.avg_left=score_left.mean()avg_right=score_right.mean()# Calculate the mse of score.mse=(((score_left-avg_left)**2).sum()+((score_right-avg_right)**2).sum())/len(score)returnmse,avg_left,avg_right
def_choose_split(self,col:array,score:array):# Feature cannot be splitted if there's only one unique element.unique=set(col)iflen(unique)==1:returnNone,None,None,None# In case of empty splitunique.remove(min(unique))# Get split point which has min mseite=map(lambdax:(*self._get_split_mse(col,score,x),x),unique)mse,avg_left,avg_right,split=min(ite,key=lambdax:x[0])returnmse,avg_left,avg_right,split
def_choose_feature(self,data:array,score:array):# Compare the mse of each feature and choose best one.ite=map(lambdax:(*self._choose_split(data[:,x],score),x),range(data.shape[1]))ite=filter(lambdax:x[0]isnotNone,ite)# Terminate if no feature can be splittedreturnmin(ite,default=None,key=lambdax:x[0])
def_get_rules(self):que=[[self.root,[]]]self._rules=[]# Breadth-First Searchwhileque:node,exprs=que.pop(0)# Generate a rule when the current node is leaf nodeifnot(node.leftornode.right):# Convert expression to textliterals=list(map(self._expr2literal,exprs))self._rules.append([literals,node.score])# Expand when the current node has left childifnode.left:rule_left=copy(exprs)rule_left.append([node.feature,-1,node.split])que.append([node.left,rule_left])# Expand when the current node has right childifnode.right:rule_right=copy(exprs)rule_right.append([node.feature,1,node.split])que.append([node.right,rule_right])
2.8 训练模型
仍然使用队列+广度优先搜索,训练模型的过程中需要注意:
1. 控制树的最大深度max_depth;
2. 控制分裂时最少的样本量min_samples_split;
3. 叶子结点至少有两个不重复的y值;
4. 至少有一个特征是没有重复值的。
deffit(self,data:array,score:array,max_depth=5,min_samples_split=2):# Initialize with depth, node, indexesself.root.score=score.mean()que=[(self.depth+1,self.root,data,score)]# Breadth-First Searchwhileque:depth,node,_data,_score=que.pop(0)# Terminate loop if tree depth is more than max_depthifdepth>max_depth:depth-=1break# Stop split when number of node samples is less than# min_samples_split or Node is 100% pure.iflen(_score)<min_samples_splitorall(_score==score[0]):continue# Stop split if no feature has more than 2 unique elementssplit_ret=self._choose_feature(_data,_score)ifsplit_retisNone:continue# Split_,avg_left,avg_right,split,feature=split_ret# Update properties of current nodenode.feature=featurenode.split=splitnode.left=Node(avg_left)node.right=Node(avg_right)# Put children of current node in queidx_left=(_data[:,feature]<split)idx_right=(_data[:,feature]>=split)que.append((depth+1,node.left,_data[idx_left],_score[idx_left]))que.append((depth+1,node.right,_data[idx_right],_score[idx_right]))# Update tree depth and rulesself.depth=depthself._get_rules()
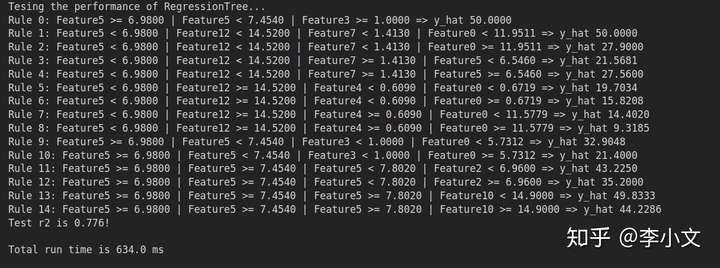
defmain():print("Tesing the performance of RegressionTree...")# Load datadata,score=load_boston_house_prices()# Split data randomly, train set rate 70%data_train,data_test,score_train,score_test=train_test_split(data,score,random_state=200)# Train modelreg=RegressionTree()reg.fit(data=data_train,score=score_train,max_depth=5)# Show rulesprint(reg)# Model evaluationget_r2(reg,data_test,score_test)