----------此方法仅供参考---------
文末附fashion_mnist数据集
错误情况说明:
在使用keras的接口加载fashion_mnist数据集时,由于网络限制的原因加载的很慢或者加载失败:
解决方法:
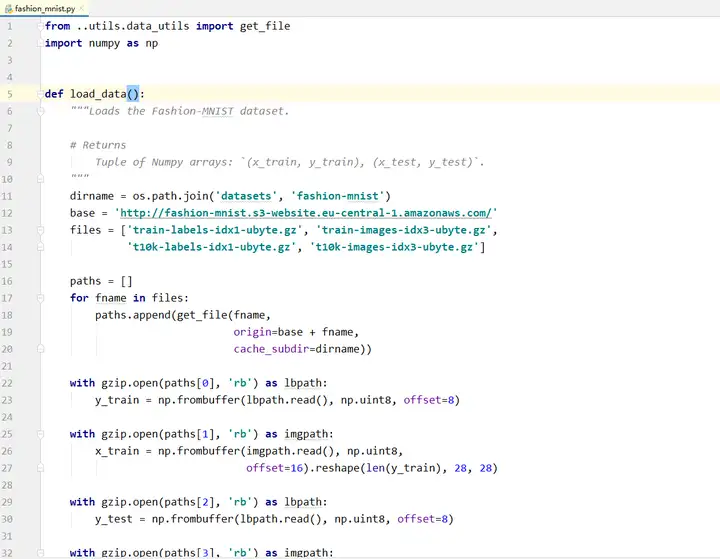
找到fashion_mnist的源代码:
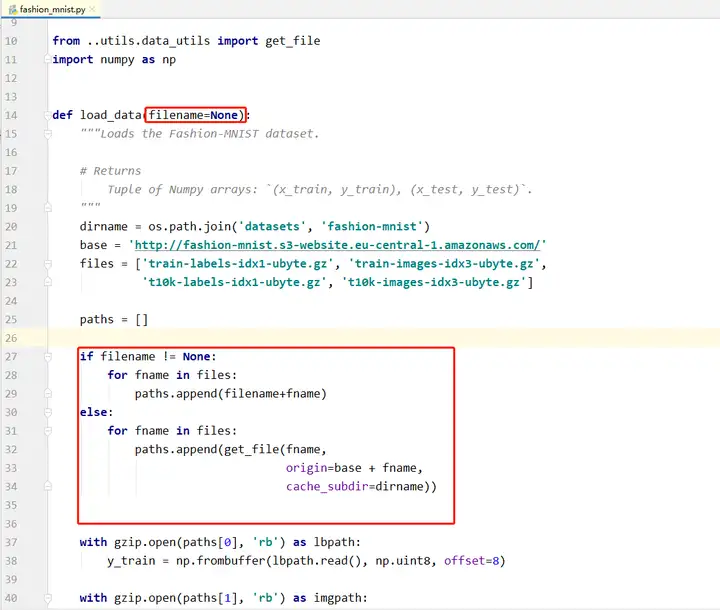
稍微修改一下这两个地方,其他地方不变:
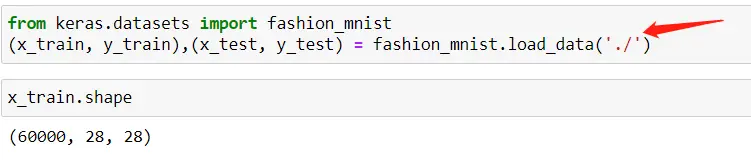
然后把fashion_mnist的四个文件下载到本地,就可以愉快的加载本地的文件了,括号里面要添加四个文件的文件夹位置:
附:fashion_mnist数据集和fashion_mnist.py修改后的全部代码:
链接:https://pan.baidu.com/s/1etbR_yU2zKJkwMTNg4esYQ
提取码:9l5z
"""Fashion-MNIST dataset.
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import gzip
import os
from ..utils.data_utils import get_file
import numpy as np
def load_data(filename=None):
"""Loads the Fashion-MNIST dataset.
# Returns
Tuple of Numpy arrays: `(x_train, y_train), (x_test, y_test)`.
"""
dirname = os.path.join('datasets', 'fashion-mnist')
base = 'http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/'
files = ['train-labels-idx1-ubyte.gz', 'train-images-idx3-ubyte.gz',
't10k-labels-idx1-ubyte.gz', 't10k-images-idx3-ubyte.gz']
paths = []
if filename != None:
for fname in files:
paths.append(filename+fname)
else:
for fname in files:
paths.append(get_file(fname,
origin=base + fname,
cache_subdir=dirname))
with gzip.open(paths[0], 'rb') as lbpath:
y_train = np.frombuffer(lbpath.read(), np.uint8, offset=8)
with gzip.open(paths[1], 'rb') as imgpath:
x_train = np.frombuffer(imgpath.read(), np.uint8,
offset=16).reshape(len(y_train), 28, 28)
with gzip.open(paths[2], 'rb') as lbpath:
y_test = np.frombuffer(lbpath.read(), np.uint8, offset=8)
with gzip.open(paths[3], 'rb') as imgpath:
x_test = np.frombuffer(imgpath.read(), np.uint8,
offset=16).reshape(len(y_test), 28, 28)
return (x_train, y_train), (x_test, y_test)