дкБОНЬГЬжаЃЌЮвУЧНЋНщЩмвЛаЉМђЕЅЖјгааЇЕФЗНЗЈЃЌПЩвдЪЙгУетаЉЗНЗЈЙЙНЈвЛИіЙІФмЧПДѓЕФЭМЯёЗжРрЦїЃЌжЛЪЙгУКмЩйЕФбЕСЗЪ§Он —— УПРрМИАйЛђМИЧЇеХЭМЦЌЁЃ
НЋНщЩмвдЯТФкШнЃК
ДгЭЗПЊЪМбЕСЗаЁаЭЭјТчЃЈзїЮЊЛљЯпЃЉ
ЪЙгУдЄЯШбЕСЗЕФЭјТчЕФЦПОБЙІФм
ЮЂЕїдЄбЕСЗЭјТчЕФtop layers
ЮвУЧНЋЪЙгУЕНвдЯТKerasЕФfeaturesЃК
fit_generator ЪЙгУPythonЪ§ОнЩњГЩЦїЃЌбЕСЗKerasФЃаЭImageDataGenerator гУгкЪЕЪБЪ§ОндіЧПВуЖГНсЃЈlayer freezingЃЉКЭФЃаЭfine-tuning
зЂвтЃКашвЊKeras 2.0.0ЛђИќИпАцБОЗНПЩдЫааЁЃ
ПЊЙЄЃК2000ИібЕСЗбљБОЃЈУПРр1000ИіЃЉ
ЮвУЧНЋДгвдЯТЩшжУПЊЪМЃК
АВзАСЫKerasЃЌSciPyЃЌPILЕФЕчФд(ЕБШЛШчЙћгаNvidia ЕФGPUзюКУСЫ)ЁЃ
бЕСЗЪ§ОнМЏКЭбщжЄЪ§ОнМЏЃЌФПТМШчЯТЃК
data/
train/
dog/
dog001.jpg
dog002.jpg
...
cats /
cat001.jpg
cat002.jpg
...
validation /
dogs /
dog001.jpg
dog002.jpg
...
cats /
cat001.jpg
cat002.jpg
...
БОЪЕбщжаЃЌЮвУЧДгKaggleЛёЕУ СЫ
ЖдгкЩюЖШбЇЯАРДЫЕЃЌетЪЧвЛИіКмаЁЕФЪ§ОнМЏЁЃгУаЁбљБОбЕСЗЩюЖШбЇЯАФЃаЭЪЧвЛИіЗЧГЃгаЬєеНадЕФЮЪЬтЃЌЕЋЫќвВЪЧвЛИіЯжЪЕЕФЮЪЬтЃКдкаэЖрЯжЪЕЪРНчЕФЪЙгУАИР§жаЃЌМДЪЙЪЧаЁЙцФЃЕФЪ§ОнЪеМЏвВПЩФмЗЧГЃАКЙѓЛђгаЪБМИКѕВЛПЩФмЃЈР§ШчдквНбЇГЩЯёжаЃЉЁЃФмЙЛГфЗжРћгУЗЧГЃЩйЕФЪ§ОнЪЧгаФмСІЕФЪ§ОнПЦбЇМвЕФЙиМќММФмЁЃ
етИіЮЪЬтгаЖрФбЃПСНФъЧАЕФKaggleУЈЙЗБШШќЃЈЙВМЦ25,000еХбЕСЗЭМЯёЃЉЃЌгавдЯТЩљУїЃК
“дкЖрФъЧАНјааЕФЗЧе§ЪНУёвтЕїВщжаЃЌМЦЫуЛњЪгОѕзЈМвШЯЮЊЃЌШчЙћУЛгаЯжгаММЪѕЕФжиДѓНјВНЃЌОЋЖШИпгк60ЃЅЕФЗжРрЦїНЋКмФбЪЕЯжЁЃФПЧАЕФЮФЯзБэУїЃЌЛњЦїЗжРрЦїдкДЫШЮЮёЩЯЕФзМШЗЖШПЩвдДяЕН80ЃЅвдЩЯ[ВЮПМ]
дкзюжеЕФБШШќжаЃЌЖЅМЖВЮШќепЭЈЙ§ЪЙгУЯжДњЩюЖШбЇЯАММЪѕЛёЕУСЫГЌЙ§98ЃЅЕФзМШЗТЪЁЃдкЮвУЧЕФР§згжаЃЌвђЮЊЮвУЧНіНЋздМКЯожЦдкЪ§ОнМЏЕФ8ЃЅЃЌЫљвдЮЪЬтвЊРЇФбЕУЖрЁЃ
ЩюЖШбЇЯАгыаЁЪ§Он
ЮвУЧОГЃЬ§ЕНЕФвЛЬѕаХЯЂЪЧ“ЩюЖШбЇЯАжЛгадкгЕгаДѓСПЪ§ОнЪБВХгавтвх”ЁЃЕБШЛЃЌЩюЖШбЇЯАашвЊФмЙЛДгЪ§ОнжаздЖЏбЇЯАЬиеїЃЌетЭЈГЃжЛгадкгаДѓСПбЕСЗЪ§ОнПЩгУЪБВХгаПЩФм ЃЌЬиБ№ЪЧЖдгкЪфШыбљБОЗЧГЃИпЮЌЕФЮЪЬтЃЌШчЭМЯёЁЃШЛЖјЃЌОэЛ§ЩёОЭјТч —— ЩюЖШбЇЯАЕФжЇжљЫуЗЈ —— ЪЧДѓЖрЪ§“ИажЊ”ЮЪЬтЃЈР§ШчЭМЯёЗжРрЃЉЕФзюМбФЃаЭжЎвЛЃЌМДЪЙжЛгаКмЩйЕФбЕСЗЪ§ОнЃЌвРШЛПЩвдбЕСЗвЛИіВЛДэЕФФЃаЭЃЌЖјВЛашвЊШЮКЮздЖЈвхЬиеїЙЄГЬЁЃ
ИќживЊЕФЪЧЃЌЩюЖШбЇЯАФЃаЭБОжЪЩЯЪЧИпЖШПЩдйРћгУЕФЃКР§ШчЃЌФњПЩвдВЩгУдкДѓЙцФЃЪ§ОнМЏЩЯбЕСЗЕФЭМЯёЗжРрЛђгявєЕНЮФБОФЃаЭЃЌШЛКѓдквЛИіВЛЭЌЕФШЮЮёжиИДЪЙгУЫќЃЌжЛашНјааЮЂаЁЕФИќИФЃЌШчЮвУЧНЋдкетЦЊЮФеТжаПДЕНЁЃЬиБ№ЪЧдкМЦЫуЛњЪгОѕЕФШЮЮёжаЃЌаэЖрдЄЯШбЕСЗЕФФЃаЭЃЈЭЈГЃдкImageNetЪ§ОнМЏЩЯбЕСЗЃЉЯждкПЩвдЙЋПЊЯТдиЃЌВЂЧвПЩвдгУгкДгЗЧГЃЩйЕФЪ§ОнжаЭЦЕМЧПДѓЕФЪгОѕФЃаЭЁЃ
Ъ§ОндЄДІРэКЭЪ§ОндіЧП
ЮЊСЫГфЗжРћгУбЕСЗбљБОЃЌЮвУЧНЋЭЈЙ§вЛЯЕСаЫцЛњБфЛЛРД“РЉГф”ЫќУЧЃЌетбљФЃаЭОЭВЛЛсПДЕНЭъШЋЯрЭЌЕФСНДЮЭМЯёЁЃетгажњгкЗРжЙЙ§ФтКЯЃЌВЂдіЧПФЃаЭЕФЗКЛЏадФмЁЃ
дкKerasжаПЩвдЭЈЙ§keras.preprocessing.image.ImageDataGeneratorРр РДЭъГЩЁЃетИіРрдЪаэЮвУЧЃК
ХфжУбЕСЗЙ§ГЬжаЭМЯёЕФИїжжБфЛЛКЭЙщвЛЛЏВйзї
ЭЈЙ§ЕїгУ.flow(data, labels)Лђеп.flow_from_directory(directory)ЗНЗЈЃЌЗЕЛиЩЯЪіВйзїЕФЭМЯёbatchЩњГЩЦїЁЃетИіЩњГЩЦїПЩвдКЭKerasЕФФЃаЭЗНЗЈЃЈfit_generator,evaluate_generatorКЭpredict_generatorЃЉвЛЦ№ЪЙгУЃЌзїЮЊЫћУЧЕФЪфШыЁЃ
ЮвУЧТэЩЯПДвЛИіР§згЃК
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator ЃЈ
rotation_range = 40 ЃЌ
width_shift_range = 0.2 ЃЌ
height_shift_range = 0.2 ЃЌ
rescale= 1 / 255 ЃЌ
shear_range = 0.2 ЃЌ
zoom_range = 0.2 ЃЌ
horizontal_flip = TrueЃЌ
fill_mode = 'nearest' ЃЉ
етаЉжЛЪЧвЛаЉПЩгУбЁЯюЃЈИќЖраХЯЂЃЌЧыВЮдФЮФЕЕ
rotation_range ЪЧвЛИіЖШЪ§ЃЈ0-180ЃЉЕФжЕЃЌБэЪОЫцЛња§зЊЭМЦЌЕФЗЖЮЇwidth_shiftКЭheight_shiftЪЧдкДЙжБЛђЫЎЦНЗНЯђЩЯЫцЛњЦНвЦЭМЦЌЕФЗЖЮЇЃЈзїЮЊзмПэЖШЛђИпЖШЕФвЛВПЗжЃЉrescaleЪЧвЛИіжЕЃЌЖдЭМЯёЕФССЖШжЕНјааЫѕЗХЃЌетИіВйзїдкЫљгаВйзїжЎЧАЃЌР§ШчrescaleЮЊ1/255ЪБЃЌБэЪОАбRGBЕФжЕДг0-255зЊЛЛЕН0-1жЎМфЁЃshear_rangeгУгкЫцЛњгІгУМєЧаБфЛЛ zoom_range гУгкЫцЛњЫѕЗХhorizontal_flip 50%ЕФЫцЛњИХТЪЖдЭМЯёНјааЫЎЦНЗзЊfill_mode ЯёЫиЬюГфВпТдЃЌдкНјааа§зЊЛђЦНвЦжЎКѓЃЌашвЊЖдЭМЯёЯёЫиНјааЬюГфЁЃ
ЯждкШУЮвУЧПЊЪМЪЙгУетИіЙЄОпЩњГЩвЛаЉЭМЦЌВЂНЋЫќУЧБЃДцЕНСйЪБФПТМжаЃЌетбљЮвУЧОЭПЩвдСЫНтЮвУЧЕФдіЧПВпТде§дкзіЪВУД —— НћгУrescaleвдБЃГжЭМЯёПЩЯдЪОЃК
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
img = load_img('data/train/cats/cat.0.jpg') # this is a PIL image
x = img_to_array(img) # this is a Numpy array with shape (3, 150, 150)
x = x.reshape((1,) + x.shape) # this is a Numpy array with shape (1, 3, 150, 150)
# the .flow() command below generates batches of randomly transformed images
# and saves the results to the `preview/` directory
i = 0
for batch in datagen.flow(x, batch_size=1,
save_to_dir='preview', save_prefix='cat', save_format='jpeg'):
i += 1
if i > 20:
break # otherwise the generator would loop indefinitely
ЯТЭМЪЧЮвУЧЕФЪ§ОндіЧПВпТдЕФбљзгЁЃ
ДгЭЗПЊЪМбЕСЗвЛИіаЁОэЛ§ЩёОЭјТчЃК40ааДњТыЃЌзМШЗТЪДяЕН80ЃЅ
ОэЛ§ЩёОЭјТчЪЧЭМЯёЗжРрШЮЮёЕФВЛЖўбЁдёЃЌЫљвдШУЮвУЧДгбЕСЗвЛИіаЁЭјТчПЊЪМЃЌзїЮЊГѕЪМЛљЯпЁЃгЩгкжЛгаЩйСПбЕСЗЪ§ОнЃЌЮвУЧЕФЭЗКХЮЪЬтгІИУЪЧЙ§ФтКЯ ЁЃЕББЉТЖгкЬЋЩйЪОР§ЕФФЃаЭбЇЯАВЛФмЭЦЙуЕНаТЪ§ОнЕФФЃЪНЪБЃЌМДЕБФЃаЭПЊЪМЪЙгУВЛЯрЙиЕФЬиеїНјаадЄВтЪБЃЌОЭЛсЗЂЩњЙ§ЖШФтКЯЁЃР§ШчЃЌШчЙћФузїЮЊвЛИіШЫЃЌжЛФмПДЕНШ§ИіЗЅФОЙЄШЫЕФЭМЯёЃЌШ§ИіЪЧЫЎЪжШЫЕФЭМЯёЃЌЦфжажЛгавЛИіЗЅФОЙЄШЫДїзХУБзгЃЌФуПЩФмЛсПЊЪМШЯЮЊДїУБзгЪЧвЛИізїЮЊвЛУћЗЅФОЙЄШЫЕФБъжОЃЌЖјВЛЪЧвЛУћЫЎЪжЁЃШЛКѓФуЛсзівЛИіЗЧГЃдуИтЕФЗЅФОЙЄ/ЫЎЪжЗжРрЦїЁЃ
Ъ§ОндіМгЪЧЖдПЙЙ§ЖШФтКЯЕФвЛжжЗНЗЈЃЌЕЋетЛЙВЛЙЛЃЌвђЮЊЮвУЧЕФдіЧПбљБОШдШЛЪЧИпЖШЯрЙиЕФЁЃЙ§ЖШФтКЯЕФжївЊНЙЕугІИУЪЧФЃаЭЕФьиФмСІ - ЮвУЧЕФФЃаЭПЩвдДцДЂЖрЩйаХЯЂЁЃЭЈЙ§РћгУИќЖрЙІФмЃЌПЩвдДцДЂДѓСПаХЯЂЕФФЃаЭПЩФмИќМгзМШЗЃЌЕЋПЊЪМДцДЂВЛЯрЙиЕФЙІФмвВДцдкЗчЯеЁЃЭЌЪБЃЌжЛФмДцДЂвЛаЉЙІФмЕФФЃаЭБиаыЙизЂЪ§ОнжаЗЂЯжЕФзюживЊЕФЙІФмЃЌетаЉЙІФмИќгаПЩФмеце§ЯрЙиВЂИќКУЕиЭЦЙуЁЃ
ЕїжЦьиШнСПгаВЛЭЌЕФЗНЗЈЁЃжївЊЕФЪЧбЁдёФЃаЭжаЕФВЮЪ§Ъ§СПЃЌМДВуЪ§КЭУПВуЕФДѓаЁЁЃСэвЛжжЗНЗЈЪЧЪЙгУШЈжие§дђЛЏЃЌР§ШчL1ЛђL2е§дђЛЏЃЌЦфАќРЈЦШЪЙФЃаЭШЈжиНгЪмНЯаЁЕФжЕЁЃ
дкЮвУЧЕФР§згжаЃЌЮвУЧНЋЪЙгУвЛИіЗЧГЃаЁЕФconvnetЃЌУПВугаЩйСПВуКЭЩйСПЙ§ТЫЦїЃЌвдМАЪ§ОндіМгКЭdropoutЁЃDropoutЛЙгажњгкМѕЩйЙ§ЖШФтКЯЃЌЗРжЙЭМВуПДЕНЭъШЋЯрЭЌФЃЪНЕФСНБЖЃЌДгЖјвдРрЫЦгкЪ§ОндіЧПЕФЗНЪНдЫааЃЈФњПЩвдЫЕЖЊЪЇКЭЪ§ОндіМгЖМЛсЦЦЛЕЪ§ОнжаГіЯжЕФЫцЛњЙиСЊЃЉЁЃ
ЯТУцЕФДњТыЦЌЖЮЪЧЮвУЧЕФЕквЛИіФЃаЭЃЌвЛИіАќКЌ3ИіОэЛ§ВуЕФМђЕЅЖбеЛЃЌЦфжаАќКЌReLUМЄЛюЃЌШЛКѓЪЧзюДѓГиЛЏВуЁЃетгыYann LeCunдк20ЪРМЭ90ФъДњЬсГЋЕФгУгкЭМЯёЗжРрЕФМмЙЙЃЈReLUГ§ЭтЃЉЗЧГЃЯрЫЦЁЃ
ПЩвддкДЫДІ
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=(3, 150, 150)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
# the model so far outputs 3D feature maps (height, width, features)
дкЫќЕФЖЅВПЃЌЮвУЧеГЬљСНИіЭъШЋСЌНгЕФВуЁЃЮвУЧгУвЛИіЕЅдЊКЭвЛИіsigmoidМЄЛюНсЪјФЃаЭЃЌетЖдгкЖўНјжЦЗжРрЪЧЭъУРЕФЁЃЮЊДЫЃЌЮвУЧЛЙНЋЪЙгУbinary_crossentropyЫ№ЪЇРДбЕСЗЮвУЧЕФФЃаЭЁЃ
model.add(Flatten()) # this converts our 3D feature maps to 1D feature vectors
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
ШУЮвУЧзМБИЮвУЧЕФЪ§ОнЁЃЮвУЧНЋ.flow_from_directory()жБНгДгИїздЮФМўМажаЕФjpgsЩњГЩХњСПЭМЯёЪ§ОнЃЈМАЦфБъЧЉЃЉЁЃ
batch_size = 16
# this is the augmentation configuration we will use for training
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
# this is the augmentation configuration we will use for testing:
# only rescaling
test_datagen = ImageDataGenerator(rescale=1./255)
# this is a generator that will read pictures found in
# subfolers of 'data/train', and indefinitely generate
# batches of augmented image data
train_generator = train_datagen.flow_from_directory(
'data/train', # this is the target directory
target_size=(150, 150), # all images will be resized to 150x150
batch_size=batch_size,
class_mode='binary') # since we use binary_crossentropy loss, we need binary labels
# this is a similar generator, for validation data
validation_generator = test_datagen.flow_from_directory(
'data/validation',
target_size=(150, 150),
batch_size=batch_size,
class_mode='binary')
ЮвУЧЯждкПЩвдЪЙгУетаЉЗЂЕчЛњРДбЕСЗЮвУЧЕФФЃаЭЁЃУПИіМЭдЊдкGPUЩЯашвЊ20-30УыЃЌдкCPUЩЯашвЊ300-400УыЁЃвђДЫЃЌШчЙћФњВЛИЯЪБМфЃЌдкCPUЩЯдЫааДЫФЃаЭОјЖдПЩааЁЃ
model.fit_generator(
train_generator,
steps_per_epoch=2000 // batch_size,
epochs=50,
validation_data=validation_generator,
validation_steps=800 // batch_size)
model.save_weights('first_try.h5') # always save your weights after training or during training
етжжЗНЗЈЪЙЮвУЧдк50ИіepochжЎКѓДяЕН0.79-0.81ЕФбщжЄзМШЗЖШЃЈетИіЪ§зжЪЧШЮвтбЁдёЕФ - вђЮЊФЃаЭКмаЁВЂЧвЪЙгУСЫЗЧГЃМЄНјЕФdropoutЃЌЕНФЧЪБЫќЫЦКѕВЛЛсЙ§ЖШФтКЯЃЉЁЃвђДЫЃЌдкЭЦГіKaggleБШШќЪБЃЌЮвУЧвбОГЩЮЊ“зюЯШНјЕФ” - гЕга8ЃЅЕФЪ§ОнЃЌВЂЧвУЛгаХЌСІгХЛЏЮвУЧЕФМмЙЙЛђГЌВЮЪ§ЁЃЪТЪЕЩЯЃЌдкKaggleБШШќжаЃЌетИіФЃаЭНЋНјШыЧА100УћЃЈ215УћВЮШќепжаЃЉЁЃЮвЯыжСЩйга115УћВЮШќепУЛгаЪЙгУЩюЖШбЇЯА;ЃЉ
ЧызЂвтЃЌбщжЄзМШЗЖШЕФЗНВюЯрЕБИпЃЌвђЮЊзМШЗЖШЪЧвЛИіИпЗНВюЖШСПЃЌвђЮЊЮвУЧжЛЪЙгУ800ИібщжЄбљБОЁЃдкетжжЧщПіЯТЃЌвЛИіКмКУЕФбщжЄВпТдЪЧНјааkелНЛВцбщжЄЃЌЕЋеташвЊдкУПТжЦРЙРжабЕСЗkИіФЃаЭЁЃ
ЪЙгУдЄЯШбЕСЗЕФЭјТчЕФЦПОБЙІФмЃКвЛЗжжгФкзМШЗТЪДяЕН90ЃЅ
ИќОЋШЗЕФЗНЗЈЪЧРћгУдкДѓаЭЪ§ОнМЏЩЯдЄЯШбЕСЗЕФЭјТчЁЃетбљЕФЭјТчвбОбЇЯАСЫЖдДѓЖрЪ§МЦЫуЛњЪгОѕЮЪЬтгагУЕФЬиеїЃЌВЂЧвРћгУетаЉЬиеїНЋЪЙЮвУЧФмЙЛБШНівРРЕгкПЩгУЪ§ОнЕФШЮКЮЗНЗЈЛёЕУИќКУЕФзМШЗадЁЃ
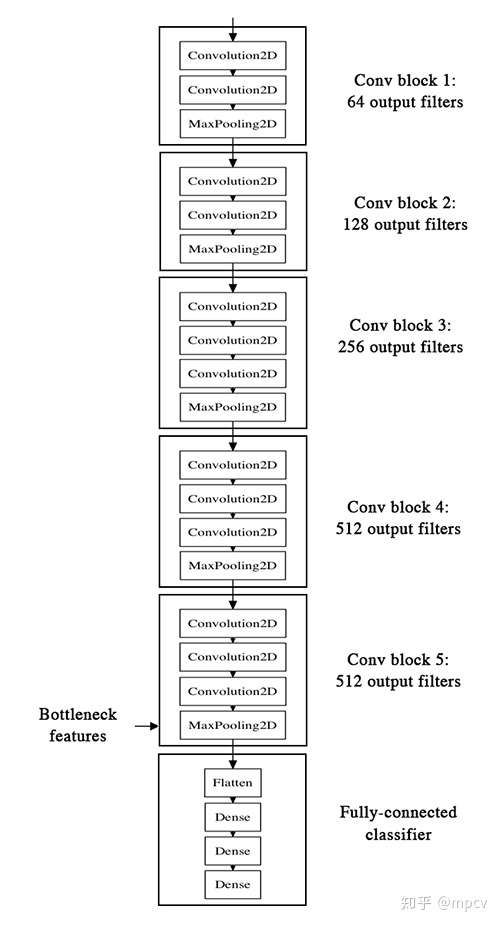
ЮвУЧНЋЪЙгУVGG16МмЙЙЃЌИУМмЙЙдкImageNetЪ§ОнМЏЩЯНјааСЫдЄбЕСЗ - етЪЧДЫВЉПЭжЎЧАЕФФЃаЭЁЃгЩгкImageNetЪ§ОнМЏдкЦфзмЙВ1000ИіРржаАќКЌЖрИі“УЈ”РрЃЈВЈЫЙУЈЃЌхпТоУЈ......ЃЉКЭаэЖр“ЙЗ”РрЃЌвђДЫИУФЃаЭвбОбЇЯАСЫгыЮвУЧЕФЗжРрЮЪЬтЯрЙиЕФЬиеїЁЃЪЕМЪЩЯЃЌНіНіМЧТМФЃаЭЕФsoftmaxдЄВтЖјВЛЪЧЦПОБЬиеїОЭзувдНтОіЮвУЧЕФЙЗгыУЈЕФЗжРрЮЪЬтЁЃШЛЖјЃЌЮвУЧдкетРяЬсГіЕФЗНЗЈИќгаПЩФмКмКУЕиЭЦЙуЕНИќЙуЗКЕФЮЪЬтЃЌАќРЈImageNetжаШБЩйРрЕФЮЪЬтЁЃ
етОЭЪЧVGG16МмЙЙЕФбљзгЃК
ЮвУЧЕФВпТдШчЯТЃКЮвУЧжЛЛсЪЕР§ЛЏФЃаЭЕФОэЛ§ВПЗжЃЌжБЕНЭъШЋСЌНгЕФВуЁЃШЛКѓЃЌЮвУЧНЋдкбЕСЗКЭбщжЄЪ§ОнЩЯдЫааДЫФЃаЭвЛДЮЃЌдкСНИіnumpyеѓСажаМЧТМЪфГіЃЈРДздVGG16ФЃаЭЕФ“ЦПОБЬиеї”ЃКЭъШЋСЌНгЕФВужЎЧАЕФзюКѓвЛИіМЄЛюгГЩфЃЉЁЃШЛКѓЃЌЮвУЧНЋдкДцДЂЕФЙІФмжЎЩЯбЕСЗвЛИіаЁЕФЭъШЋСЌНгФЃаЭЁЃ
ЮвУЧжЎЫљвдРыЯпДцДЂетаЉЙІФмЖјВЛЪЧжБНгдкЖГНсЕФОэЛ§ЛљДЁЩЯЬэМгЮвУЧЕФЭъШЋСЌНгФЃаЭВЂдЫааећИіЙІФмЃЌЪЧвђЮЊМЦЫуаЇТЪЁЃдЫааVGG16КмАКЙѓЃЌЬиБ№ЪЧШчЙћФуе§дкЪЙгУCPUЃЌЮвУЧжЛЯызівЛДЮЁЃЧызЂвтЃЌетЛсзшжЙЮвУЧЪЙгУЪ§ОнРЉГфЁЃ
ФњПЩвддкДЫДІ ДгGithub
batch_size = 16
generator = datagen.flow_from_directory(
'data/train',
target_size=(150, 150),
batch_size=batch_size,
class_mode=None, # this means our generator will only yield batches of data, no labels
shuffle=False) # our data will be in order, so all first 1000 images will be cats, then 1000 dogs
# the predict_generator method returns the output of a model, given
# a generator that yields batches of numpy data
bottleneck_features_train = model.predict_generator(generator, 2000)
# save the output as a Numpy array
np.save(open('bottleneck_features_train.npy', 'w'), bottleneck_features_train)
generator = datagen.flow_from_directory(
'data/validation',
target_size=(150, 150),
batch_size=batch_size,
class_mode=None,
shuffle=False)
bottleneck_features_validation = model.predict_generator(generator, 800)
np.save(open('bottleneck_features_validation.npy', 'w'), bottleneck_features_validation)
ШЛКѓЮвУЧПЩвдМгдиЮвУЧБЃДцЕФЪ§ОнВЂбЕСЗвЛИіаЁЕФЭъШЋСЌНгЕФФЃаЭЃК
train_data = np.load(open('bottleneck_features_train.npy'))
# the features were saved in order, so recreating the labels is easy
train_labels = np.array([0] * 1000 + [1] * 1000)
validation_data = np.load(open('bottleneck_features_validation.npy'))
validation_labels = np.array([0] * 400 + [1] * 400)
model = Sequential()
model.add(Flatten(input_shape=train_data.shape[1:]))
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(train_data, train_labels,
epochs=50,
batch_size=batch_size,
validation_data=(validation_data, validation_labels))
model.save_weights('bottleneck_fc_model.h5')
гЩгкЫќЕФЬхЛ§аЁЃЌетжжаЭКХЩѕжСПЩвддкCPUЃЈУПИіepoch 1УыЃЉЩЯПьЫйбЕСЗЃК
Train on 2000 samples, validate on 800 samples
Epoch 1/50
2000/2000 [==============================] - 1s - loss: 0.8932 - acc: 0.7345 - val_loss: 0.2664 - val_acc: 0.8862
Epoch 2/50
2000/2000 [==============================] - 1s - loss: 0.3556 - acc: 0.8460 - val_loss: 0.4704 - val_acc: 0.7725
...
Epoch 47/50
2000/2000 [==============================] - 1s - loss: 0.0063 - acc: 0.9990 - val_loss: 0.8230 - val_acc: 0.9125
Epoch 48/50
2000/2000 [==============================] - 1s - loss: 0.0144 - acc: 0.9960 - val_loss: 0.8204 - val_acc: 0.9075
Epoch 49/50
2000/2000 [==============================] - 1s - loss: 0.0102 - acc: 0.9960 - val_loss: 0.8334 - val_acc: 0.9038
Epoch 50/50
2000/2000 [==============================] - 1s - loss: 0.0040 - acc: 0.9985 - val_loss: 0.8556 - val_acc: 0.9075
ЮвУЧДяЕН0.90-0.91ЕФбщжЄзМШЗЖШЃКвЛЕувВВЛВюЁЃетдквЛЖЈГЬЖШЩЯВПЗждвђдкгкЛљДЁФЃаЭЪЧдквбООпгаЙЗКЭУЈЃЈЦфЫћЪ§АйИіРрБ№ЃЉЕФЪ§ОнМЏЩЯНјаабЕСЗЕФЁЃ
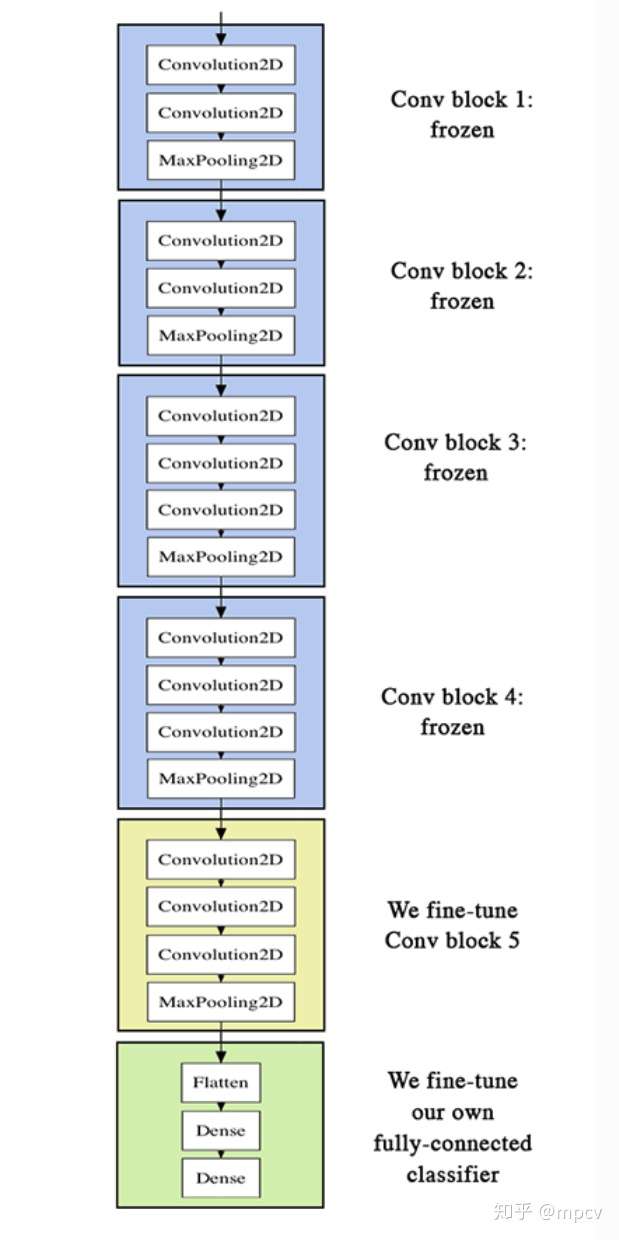
ЮЂЕїдЄбЕСЗЭјТчЕФtop layers ЮЊСЫНјвЛВНИФНјжЎЧАЕФНсЙћЃЌЮвУЧПЩвдЖдVGG16ФЃаЭЕФзюКѓвЛИіОэЛ§ПщКЭзюжеЕФШЋСЌНгВуНјааFine-tuningЁЃЗжвдЯТ3ВНЭъГЩЃК
ЪЕР§ЛЏVGG16ОэЛ§ЭјТчЃЌВЂМгдидЄбЕСЗШЈжи
дкЖЅВПЬэМгЮвУЧЯШЧАЖЈвхЕФЭъШЋСЌНгФЃаЭЃЌВЂМгдиЦфШЈжи
ЖГНсVGG16ФЃаЭЕФВуЕНзюКѓвЛИіОэЛ§Пщ
зЂвтЃК
ЮЊСЫНјааЮЂЕїЃЌЫљгаВуЖМгІИУДгбЕСЗгаЫиЕФШЈжиПЊЪМЃКР§ШчЃЌФуВЛгІИУдкдЄЯШбЕСЗКУЕФОэЛ§ЛљДЁЩЯДђвЛИіЫцЛњГѕЪМЛЏЕФШЋСЌНгЭјТчЁЃетЪЧвђЮЊгЩЫцЛњГѕЪМЛЏЕФШЈжиДЅЗЂЕФДѓЬнЖШИќаТНЋЦЦЛЕОэЛ§ЛљДЁжаЕФбЇЯАШЈжиЁЃдкЮвУЧЕФР§згжаЃЌетОЭЪЧЮЊЪВУДЮвУЧЪзЯШбЕСЗЖЅМЖЗжРрЦїЃЌШЛКѓВХПЊЪМЮЂЕїОэЛ§ШЈжиЁЃ
ЮвУЧбЁдёНіЮЂЕїзюКѓЕФОэЛ§ПщЖјВЛЪЧећИіЭјТчвдЗРжЙЙ§ЖШФтКЯЃЌвђЮЊећИіЭјТчНЋОпгаЗЧГЃДѓЕФьиШнСПВЂвђДЫОпгаЙ§ЖШФтКЯЕФЧПСвЧуЯђЁЃЕЭМЖОэЛ§ПщбЇЯАЕФЬиеїБШНЯИпМЖЕФОэЛ§ПщИќМгЭЈгУЃЌВЛФЧУДГщЯѓЃЌЫљвдБЃГжЧАМИИіПщЙЬЖЈЃЈИќвЛАуЕФЬиеїЃЉВЂЧвжЛЕїећзюКѓвЛИіПщЃЈИќзЈвЕЕФЬиеїЃЉЪЧУїжЧЕФ ЃЉЁЃ
ЮЂЕїгІИУвдЗЧГЃТ§ЕФбЇЯАЫйТЪЭъГЩЃЌЭЈГЃЪЙгУSGDгХЛЏЦїЖјВЛЪЧЪЪгІадбЇЯАЫйТЪгХЛЏЦїЃЌР§ШчRMSPropЁЃетЪЧЮЊСЫШЗБЃИќаТЕФЗљЖШБЃГжЗЧГЃаЁЃЌвдУтЦЦЛЕвдЧАбЇЙ§ЕФЙІФмЁЃ
етРя га
дкЪЕР§ЛЏVGGЛљДЁВЂМгдиЦфШЈжиКѓЃЌЮвУЧдкЖЅВПЬэМгСЫжЎЧАбЕСЗгаЫиЕФЭъШЋСЌНгЗжРрЦїЃК
# build a classifier model to put on top of the convolutional model
top_model = Sequential()
top_model.add(Flatten(input_shape=model.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(1, activation='sigmoid'))
# note that it is necessary to start with a fully-trained
# classifier, including the top classifier,
# in order to successfully do fine-tuning
top_model.load_weights(top_model_weights_path)
# add the model on top of the convolutional base
model.add(top_model)
ШЛКѓЮвУЧМЬајНЋЫљгаОэЛ§ВуЖГНсЕНзюКѓвЛИіОэЛ§ПщЃК
# set the first 25 layers (up to the last conv block)
# to non-trainable (weights will not be updated)
for layer in model.layers[:25]:
layer.trainable = False
# compile the model with a SGD/momentum optimizer
# and a very slow learning rate.
model.compile(loss='binary_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
зюКѓЃЌЮвУЧПЊЪМбЕСЗећИіЪТЧщЃЌбЇЯАЫйЖШЗЧГЃТ§ЃК
batch_size = 16
# prepare data augmentation configuration
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary')
# fine-tune the model
model.fit_generator(
train_generator,
steps_per_epoch=nb_train_samples // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=nb_validation_samples // batch_size)
етжжЗНЗЈЪЙЮвУЧдк50ИіepochжЎКѓДяЕН0.94ЕФбщжЄзМШЗЖШЁЃОоДѓЕФГЩЙІЃЁ
вдЯТЪЧвЛаЉФњПЩвдГЂЪдДяЕН0.95вдЩЯЕФЗНЗЈЃК
ИќОпЧжТдадЕФЪ§ОнРЉГф
ИќЛ§МЋЕФъЁбЇ
ЪЙгУL1КЭL2е§дђЛЏЃЈвВГЦЮЊ“жиСПЫЅМѕ”ЃЉ
ЮЂЕївЛИіОэЛ§ПщЃЈЭЌЪБИќДѓЕФе§дђЛЏЃЉ
етЦЊЮФеТдкетРяНсЪјЃЁЛиЙЫвЛЯТЃЌдкетРяФњПЩвдевЕНЮвУЧШ§ИіЪЕбщЕФДњТыЃК
зЂЃКБОЮФеТЗвыздЃК
Building powerful image classification models using very little data