Because the set of high-dimensional one-hot vectors does not admit infinitesimal perturbation, we define the perturbation on continuous word embeddings instead of discrete word inputs.
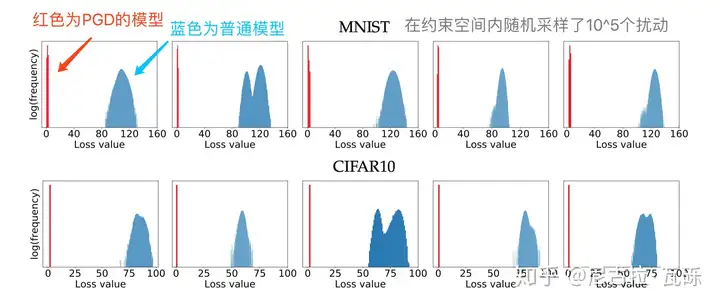
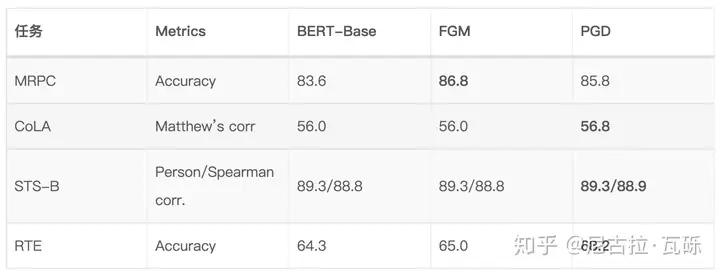
While adversarial training boosts the robustness, it is widely accepted by computer vision researchers that it is at odds with generalization, with classification accuracy on non-corrupted images dropping as much as 10% on CIFAR-10, and 15% on Imagenet (Madry et al., 2018; Xie et al., 2019). Surprisingly, people observe the opposite result for language models (Miyato et al., 2017; Cheng et al., 2019), showing that adversarial training can improve both generalization and robustness.
import torch
class FGM():
def __init__(self, model):
self.model = model
self.backup = {}
def attack(self, epsilon=1., emb_name='emb.'):
# emb_name�������Ҫ������ģ����embedding�IJ�����
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
self.backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0 and not torch.isnan(norm):
r_at = epsilon * param.grad / norm
param.data.add_(r_at)
def restore(self, emb_name='emb.'):
# emb_name�������Ҫ������ģ����embedding�IJ�����
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.backup
param.data = self.backup[name]
self.backup = {}
import torch
class PGD():
def __init__(self, model):
self.model = model
self.emb_backup = {}
self.grad_backup = {}
def attack(self, epsilon=1., alpha=0.3, emb_name='emb.', is_first_attack=False):
# emb_name�������Ҫ������ģ����embedding�IJ�����
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
if is_first_attack:
self.emb_backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0 and not torch.isnan(norm):
r_at = alpha * param.grad / norm
param.data.add_(r_at)
param.data = self.project(name, param.data, epsilon)
def restore(self, emb_name='emb.'):
# emb_name�������Ҫ������ģ����embedding�IJ�����
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.emb_backup
param.data = self.emb_backup[name]
self.emb_backup = {}
def project(self, param_name, param_data, epsilon):
r = param_data - self.emb_backup[param_name]
if torch.norm(r) > epsilon:
r = epsilon * r / torch.norm(r)
return self.emb_backup[param_name] + r
def backup_grad(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
self.grad_backup[name] = param.grad.clone()
def restore_grad(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
param.grad = self.grad_backup[name]
ʹ�õ�ʱ��Ҫ�鷳һ�㣺
pgd = PGD(model)
K = 3
for batch_input, batch_label in data:
# ����ѵ��
loss = model(batch_input, batch_label)
loss.backward() # �������õ�������grad
pgd.backup_grad()
# �Կ�ѵ��
for t in range(K):
pgd.attack(is_first_attack=(t==0)) # ��embedding�����ӶԿ��Ŷ�, first attackʱ����param.data
if t != K-1:
model.zero_grad()
else:
pgd.restore_grad()
loss_adv = model(batch_input, batch_label)
loss_adv.backward() # ����������������grad�����ϣ��ۼӶԿ�ѵ�����ݶ�
pgd.restore() # �ָ�embedding����
# �ݶ��½������²���
optimizer.step()
model.zero_grad()